




活动说明:
https://developer.aliyun.com/mission/activity/sql?utm_content=m_1000372352&accounttraceid=dcdc94c3a96d4270b9df440902f71d15nzar
参考答案链接:
https://developer.aliyun.com/article/1249105?spm=a2c6h.28178935.J_9396481960.4.5de9587bmYQ8XQ
因为第三题相对比较简单, 就是套用一个公式,这里不做讨论, 下面分别对第一题和第二题做一些分析, 同时也给出老虎刘的写法.
第一题: 找出各项考试中的佼佼者
题目要求:
一个学生可以参加任意考试,不限次数。
现在我们关注的是每门考试有哪些顶尖的学生。
一门考试的顶尖学生是指一个学生的分数在参加该考试的不同学生中得分排名前三 。
编写一个SQL查询,找出每个考试中得分最高的的考生 。
若同一个考生有多条考试记录,则取最高分。
如果存在并列,将并列的考生都列举出来,直到列举的考生达到或超过三人。
以每门考试考试分数从高到低的顺序 返回结果表。
详细说明请见:
https://developer.aliyun.com/article/1220621?spm=a2c6h.28178935.J_9396481960.5.5de9587bmYQ8XQ&groupCode=aliyundb
官方给出的参考答案:
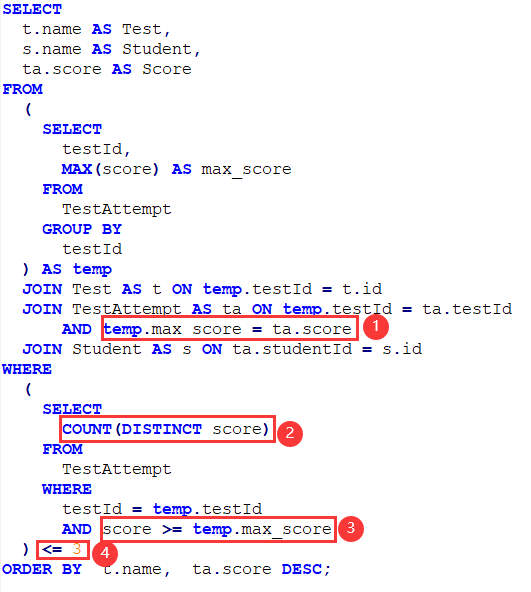
老虎刘分析一下这个SQL的逻辑:
标记1: 关联的时候只保留了最高成绩;
标记2: 根据标记3的条件,这个count(distinct score)只会是1;
标记4: 因为标记2始终=1, 这个<=3 实际上没多大意义了.
(这个写法我一开始没理解,跟苏旭辉老师探讨了一下才搞清楚)
上面SQL用模拟数据得出的输出结果: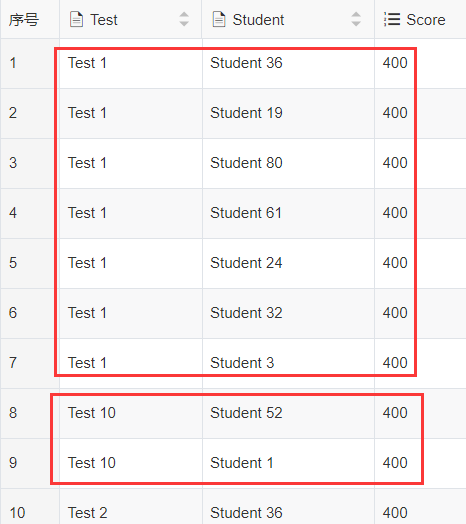
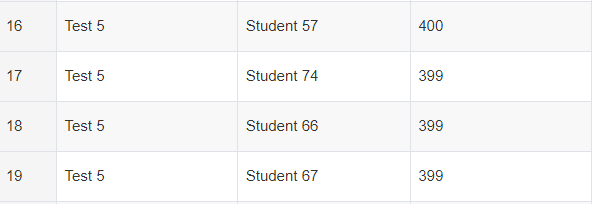
其中Test1排名第一的7个人,都显示了出来; Test10只显示了两个得分最高的学生,后面得分399的没有显示. 这个跟参赛说明给出的示例输出不太一致:
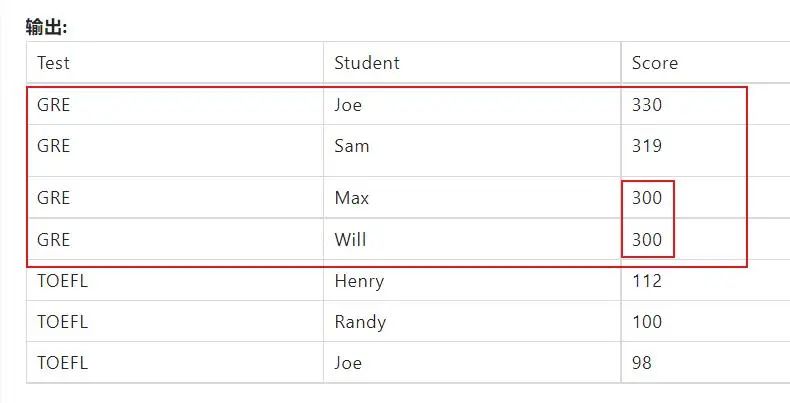
参赛说明给出的示例输出:(第二名会输出,并列的第三名也会输出,这个符合rank排名的特点)
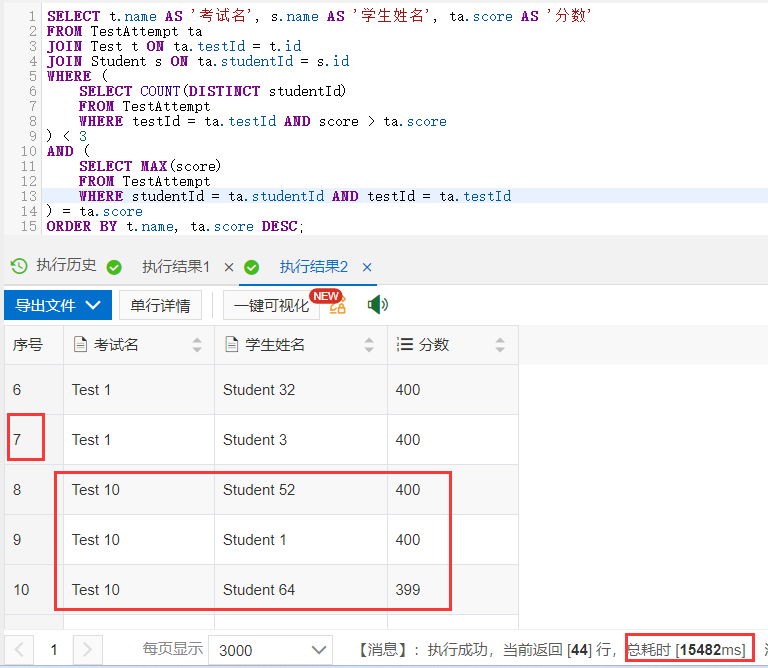
老虎刘的参赛写法:

说明:
按成绩排名, 一般会使用rank()分析函数(有些人用dense_rank或row_number,都不是正常人理解的成绩排名选择).
同时题目中有并列的排名,显示个数不能超过3个, 如果只用rk<=3 的条件, 那么如果有 500人都考了第一名,都会显示出来; 如果第一名有1个或2个人, 第二名有几百人, 这几百名也会显示出来; 如果第一名和第二名各有1人, 第三名有几百人, 同样也会把这几百名显示出来.
为了避免并列显示过多,可以再配合row_number() 分析函数, 把并列排名的个数限制在3人(随机选3人),输出结果如下:
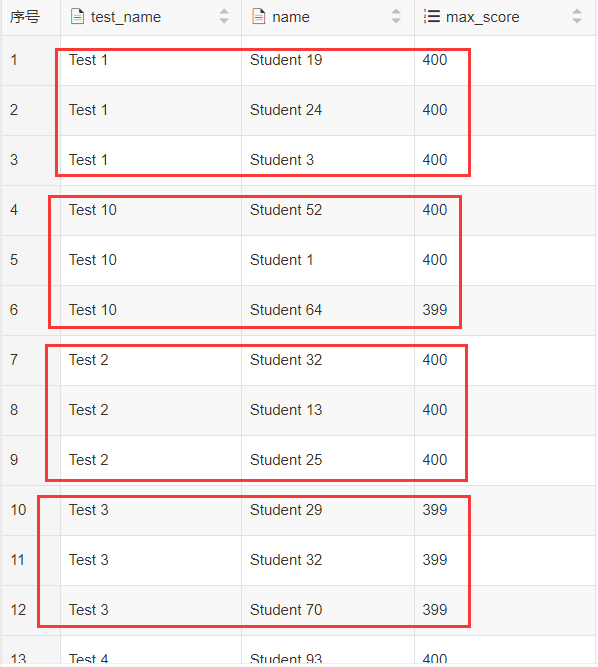
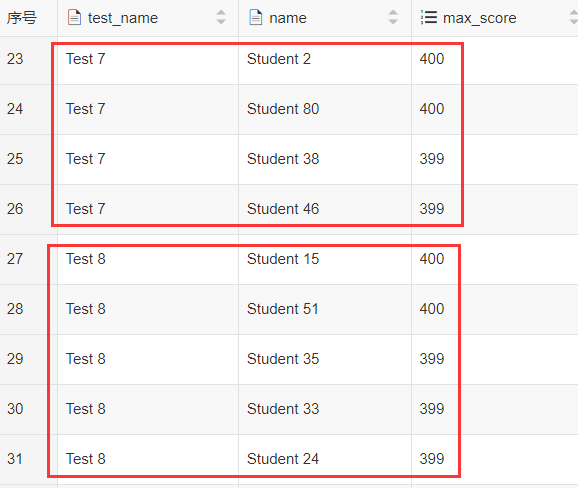
顺便说一下, 在墨天轮上看到有人用chatGPT生成了这个赛题的SQL写法(https://www.modb.pro/db/648444), 需要经过多次纠正,最终得到了类似rank()的排名结果, 用上面的模拟数据执行需要15+秒(本人的写法耗时30多毫秒),1万条记录就慢成这样, 数据量再大基本上就跑不出结果了,chatGPT有时只能做个参考,指望它起大作用,可能还早(做一些简单的问答好像还可以,墨天轮上有些问答, 感觉有点这个味了):
第二题: 找出首次游玩后的一周内至少再有一次游玩的玩家的比例
题目说明:
Activity这张表显示了某些游戏的玩家的活动情况。
(player_id,event_date)是此表的主键。
每一行是一个玩家在指定日期的游玩记录,包含了设备信息,以及总共玩了多少款游戏。
编写一个 SQL 查询,报告在首次游玩后的一周内至少再有一次游玩的玩家的比例,也就是注册首周内至少有两次登录的玩家占总玩家的比例,四舍五入到小数点后两位。
详细说明请见:
https://developer.aliyun.com/article/1220625?spm=a2c6h.12873639.article-detail.74.75bf5981lCZlDl
官方参考答案:

参考答案的写法没有使用分析函数(可能是mysql的分析函数效率还不太尽如人意吧), 3次全表扫描耗时55毫秒.
下面是我的参赛sql:
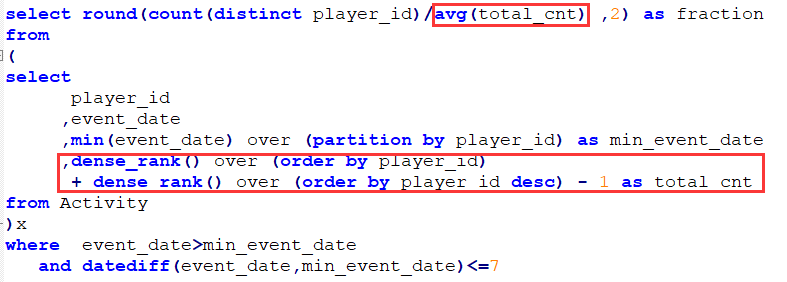
说明:
因为mysql不支持count(distinct )分析函数, 我用两次dense_rank来替代; total_cnt都是一个值, 用avg或min/max都可以.
这个sql在参赛平台耗时111毫秒(每次执行都会有几个毫秒的细微差别), 相同SQL在本人笔记本电脑虚拟机上的oracle数据库执行20毫秒, 模拟数据都是一样的1万条,排除磁盘读的差异,说明oracle的分析函数比mysql性能还是要好一些.
后来我又对上面SQL做了一点小改进, 用row_number 取代两次dense_rank,耗时70毫秒, 比较接近官方参考答案写法的效率了.如果数据量大了, 我的写法只需要做一次表扫描, 说不定效率更高, 写法也相对简洁一些:

总结:
实现相同逻辑的SQL写法多种多样,首先要满足的是业务要求,其次还要特别关注SQL性能, 然后还有SQL写法(可读性).
这样的SQL大赛我觉得非常有意义,如果更多的开发者能够提升SQL能力,大量运行在国产数据库上的业务, 也会越来越稳定和高效.
(完)

