




11月17日,今天是值得纪念的一天,技术人生系列回来了, 久违了,朋友们!
自2018年8月第五十八期停更后,由于工作繁忙的原因,就没有继续更新了。时间过的真快,一晃三年已经过去了!还是熟悉的味道,还是每周一篇贴近实战的文章,不过这次,我们跟随一下潮流,换一种形式,那就是以文章结合每周四晚直播的方式和大家分享,这样也可以有良好的互动,让大家有更多的收获,希望大家理解并喜欢这样的改变哦。
言归正传,本期分享的主题希望能给大家带来下面几个方面或多或少的收获:
1、 “在线新建一个索引有风险么,系统真的会崩么?”
答案是可能会,也可能不会。
深入了解这个case之后,你就知道什么业务场景下会崩,什么场景下不会崩,也就可以完善创建索引的指导规范了。
2、 “优化SQL我还可以,但是领导一问,为什么执行计划变了,根本原因是什么,原理是什么,以后怎么预防?总答不上来,也不知道怎么分析这类问题…”
希望这个case之后,你能掌握正确的方法去分析该类问题了,原因找到了,自然就好预防了…
3、 “我的结论说了,但是没有说服领导啊”
实际上,重现出问题往往是最好的说服力,所以大家要不断培养自己重现问题的能力,才能不断突破自己的技术瓶颈。
微信响了,是一家资产过万亿的银行客户的DBA负责人发过来的信息。

看完信息,小y一下来了精神,这是一个19C 两节点的RAC。
不过从发送信息的时间看,问题已经暂时得到解决,客户显然更关心背后的原理,以及今后如何避免类似问题出现。
客户紧接着说道:
“出问题的时候,表的统计信息我看了,全局和分区一级的统计信息,都是新的,没问题。
另外,这个系统绑定变量偷窥是关闭的。
最后实在不行,重新收集了一次统计信息后,执行计划就变好了。
领导需要知道背后的原因和原理,为什么新建一个索引,会出现这样的情况?
以后新建索引该怎么做,规范怎么定,如果出现问题的是高频交易的SQL,系统就崩了!!”
在这个行业摸爬滚打这么多年,特别能理解客户此时的心情,也正是客户这样的高要求促使我们不断进步,帮助客户分析每次问题背后的原因,并由点带面去设计规范预防问题、消除隐患,这不就是我们的价值么。
这类问题,如果在可以重现问题的情况下收集一个10053 event,那么对于我们分析为什么SQL走错索引的原因,将有极大的帮助。于是小y和客户提议:
“现在explain plan for sql…还能重现错误的执行计划么?帮我收集个10053吧”
很可惜,故障现象现在已经无法重现了。当前Explain得到的是正确的执行计划。
实际上,这一类典型的事后分析执行计划突变或选错的问题,是DBA和开发人员比较头疼、没有思路的问题,特别是统计信息还比较准确的情况下,原因说不清道不明。
事后分析,并且在无法重现问题的情况下分析问题,这无疑是一个挑战,而挑战不正是人生的魅力所在么。
到这里,大家不妨停一下,思考一下,如果是你,接下来你打算分几步来分析,又需要哪些信息来帮助你找到问题的根本原因呢…
思考时间
……
此处留白…
什么时候往下翻,由你决定…
……
客户DBA很专业,随后在微信里贴了相关的信息,包括:
² 完整的SQL语句
² 现有索引的字段列表和字段顺序
² 新创建的索引的字段列表和字段顺序
² 表上过滤字段的选择性
² 以前走的的正确执行计划
² 现在走错了的执行计划
2.1 SQL语句以及列选择性


SQL语句如上图所示。
这里小y对表名多了一些脱敏的处理。
表上相关列的选择性如下:

这里大家可以稍微心算一下:
² SQL是单表查询,求count(*),过滤条件有2个条件,分别为法人代码和对账批号
² T1表约有1400万行,是一个分区表,按天范围分区,SQL语句中没有使用分区字段
² 对账批号字段里有800多万的NULL值,列上无直方图,因此平均每个对账批号大概有(1400万-800万)/190=3万条左右的记录
² 法人代码只有一个值,因此满足法人代码条件的记录是所有记录,即1400万行
这里请记住对账批号和法人代码两个字段的名字,以及字段不同值的个数分别为190和1.
看到这里,先来一个小花絮,估计开发的同学和部分DBA已经跃跃欲试了。
并且很快指出了这个SQL的第一个“问题”,
“这个SQL明明是count(*), SQL语句里还有order by,这个写法有问题吧,会导致额外的排序吧…”
实际上,听到这个回答,有喜有悲。
喜的是开发有自己的想法,悲的是,开发还不了解SQL的执行过程,不了解背后的原理。
其实这不是一个问题,因为实际执行时并不会真正发生排序,Oracle数据库的优化器还是非常智能的,其中一个特性叫OBYE 即order by elimination,中文含义为“order by 清除”,对于不必要的order by,在SQL做查询转换的时候自动就去掉了。也就是说,数据库在执行上面SQL的时候,实际上已经改成下面这样的SQL来执行了。

2.2 现有索引的字段列表和顺序

可以看到:
当前存在一个IDX4,即4号索引,顺序分别是 DUIZPHAO,QIARIQI,FARENDMA,其中红色字体的列分别对应SQL语句中的过滤条件即对账批号和法人代码。
显然SQL语句应该走这个索引IDX4,因为对账批号是第一个字段,不同值有190个。
法人代码虽然是复合索引中的第三列,但对于这个SQL,索引字段中带有法人代码字段,则SQL语句无需回表,在索引中就可以过滤,因此走该索引效率还是不错的。
2.3 新建索引的字段列表和顺序
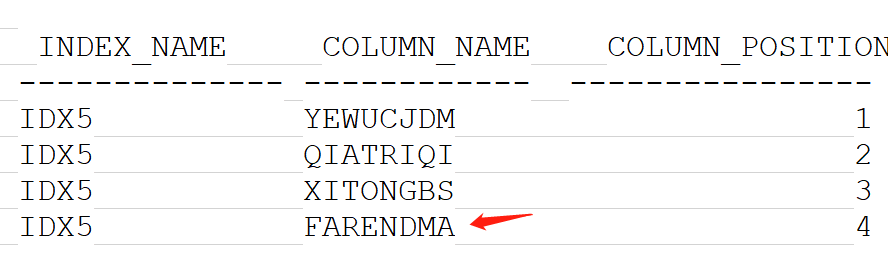
可以看到:
问题当天,新建了一个IDX5,即5号索引,顺序分别是 YEWUCJDM,QIARIQI,XITONGBS,FARENDMA
其中红色字体的部分对应SQL语句中的过滤条件 ,即法人代码字段。
因为法人代码只有1个不同值,因此无论如何也不应该走该索引。
但出人意外的事情发生了,就在这个索引创建后,对账批量的SQL,立马放弃了更合适的IDX4索引,选择了这个打死都不应该选择的IDX5索引。
2.4 新建索引后选错执行计划
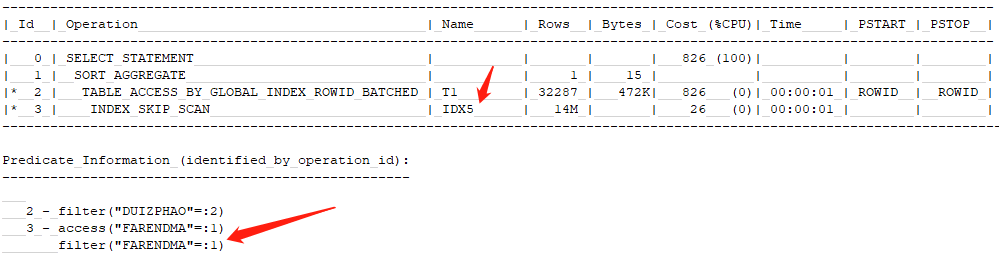
在新创建IDX5这个索引后,数据库居然离谱的选择了这个索引!IDX5索引只能通过法人代码来定位数据,而法人代码只有1个。同时,因为IDX5索引中,过滤字段法人代码不是引导列,而是最后1列,因此是索引跳扫,INDEX SKIP SCAN.
SQL语句走IDX5这个索引,那就太崩溃了。
我们来看看为什么,估算一下走这个索引,SQL要跑多长时间才能完成呢?
因为法人代码是唯一的,则需要先从索引跳扫定位1400万条记录,再回表过滤对账批号(该字段不在复合索引的字段中,该字段的不同值个数为190个),结果约为3万条记录。
1400万的回表,这无疑是灾难,近似等于一条记录一条记录地去访问整张表的所有记录了,发生的IO次数(单块读)最高可能达到1400万次,按照一个IO响应 4毫秒计算,需要的时间是 14,000,000*4/1000=56000秒,超过10个小时(即使按照一个IO 1毫秒计算,也需要2.5小时),这显然是无法接受的!
2.5 以前的正确执行计划
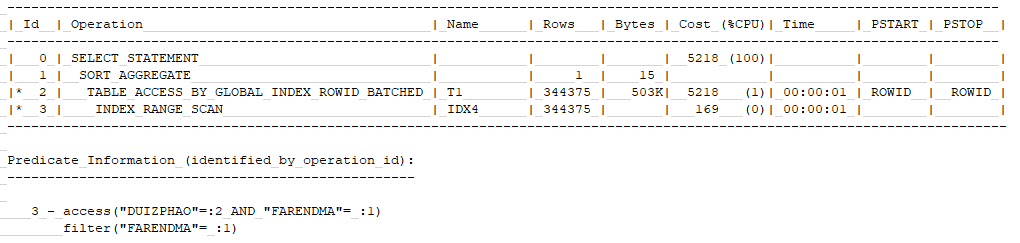
正确的执行计划如上图所示
这里走IDX4索引,是正确的。
这里,我们稍微记忆一下,索引4对5错,索引4对5错,索引4对5错!
IDX4的索引字段顺序如下
即IDX4索引先通过对账批号字段来定位3万条数据,再过滤法人代码即可,这里按照一个索引叶子块存200行计算,也只需要访问150个叶子块,即使所有叶子块不在buffer cache内存里缓存,只需要150次IO,单个IO按照4毫秒计算,这样总计才需要150*4毫秒=600毫秒左右。
2.6 为什么优化器的选择那么离谱呢
这里,我们稍微总结一下,错误的执行计划和正确的执行计划来,估算下来分别要执行56000秒和600毫秒,按照客户的说法,统计信息基本是正确的。那么数据库优化器为什么会选错呢?
好的,阶段性的信息已经有了,接下来你会用什么方法论来分析这个问题呢?
……
此处留白…
什么时候往下翻,由你决定…
……
如果是你,你接下来会怎么来分析这个问题呢?
可能有同学已经跃跃欲试了,我们来听听大家的猜测吧…
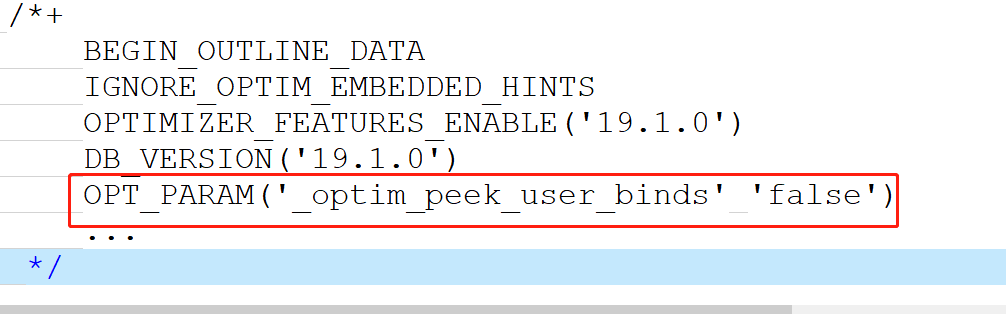
4.1 是绑定变量偷窥特性导致的么
答案是NO…
客户之前提到,绑定变量偷窥特性是关闭的。
也就是说,在选择执行计划的时候,实际上不会按照变量传入值的具体分布来确定执行计划。
以下是display_cursor执行计划的outline部分,显示了bind peeking特性确实是关闭的,因此也就不存在数据倾斜的传入值将执行计划带偏的情况了。
4.2 是新建索引没有及时收集统计信息么
答案是NO…
创建索引的时候,虽然执行的是类似下面的命令,
create index idx_xx on xx_tab(xx_col) online;
实际上,数据库会在命令后面加上compute statistics的默认选项,即数据库执行的SQL是
create index idx_xx on xx_tab(xx_col) online compute statistics;
因此,创建索引后也就完成了同时收集了索引的统计信息。
4.3 容我想想,还有什么其他可能呢…
可能还有同学有各种猜测,是否准确呢?
实际上,解决经验范围之外的未知问题,我们需要的是方法论,方法和思路远比纯粹的猜测更有意义。
暂时想不出来,没关系的,小y在找到这个问题的原因后,已经做了重现案例。
为了更好的互动,我们将在直播上验证大家的猜测或方法论,这也就是我们说到的图文加直播互动结合的形式,让大家更好的提升…
……
此处留白…
不放再思考思考…
什么时候往下翻,由你决定…
……
5.1 方法论是什么?
SQL为什么走错执行计划呢?
实际上,数据库是基于成本的优化器,数据库的优化器将计算各种可能执行计划的成本COST,从中取成本最低的执行计划。这个就是背后的逻辑。
所以,要么是错误的执行计划算低了成本,要么是正确的执行计划算高了成本。
接下来我们将按照这个思路往下分析即可…
5.2 是错误的执行计划成本算低了么?
回想以下,执行计划,走索引,4对5错。4是对账批号的索引,5是法人代码的索引。
走IDX5即法人代码字段上的索引,显然是错误的。如下

按照方法论,这个执行计划到底是成本算低了还是算高了呢?
注意,ID=3和ID=2的步骤,根据法人代码定位到1400万记录,回表后成本只有826-26=800。这显然是算低了!
我们之前提到,1400万记录回表的时间按照4毫秒计算,在数据高度离散的情况下,可能需要56000秒,超过10个小时。成本怎么可能只有800个单块IO呢…
5.3 是正确的执行计划成本算高了么?
执行计划,走索引,4对5错。
再来回顾一下SQL语句和正确的执行计划以及正确索引IDX4的字段列表
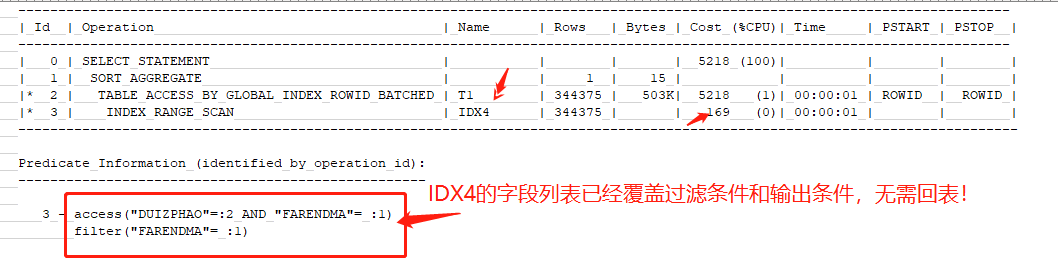
这里走IDX4索引,是正确的。IDX4的索引字段顺序如下
也就是说:
这里实际上是不需要回表的,因为是SELECT COUNT(*),并且2个过滤条件已经在索引中全部包含,索引先按照对账批号定位数据,在不回表的情况下就可以过滤法人代码,并且ORDER BY sanfriqi这里也会做order by清除,不需要回表拿到sanfriqi 字段的值因此没有必要回表。但实际情况是回表了!这导致成本多计算了5218-168=5050,显然是一个优化器的缺陷/BUG。
正确的成本应该是168左右,而不是现在的5218!!
168的成本将远小于错误执行计划的826。
5.4 哪个更为关键呢
两个都很重要。如果只单独考虑这一个SQL和这2个索引,解决任意一个问题都可以解决该问题。但从严重程度来讲, 1400W记录回表访问,COST只有800,显然是严重算低了!IDX5高成本算低,影响的业务场景将会更多,也更关键!
5.5 为什么错误的执行计划的成本严重算低了?
综上,在表和索引统计信息都相对准确的情况下,
为什么走IDX5定位1400W条记录,回表的成本COST只有800呢?
错误的执行计划,成本COST本优化器严重算低了!
如果在没有10053 event的情况下,该怎么继续往下分析呢?
什么业务场景下会导致我们的系统崩塌呢…


请关注上图中的视频号,并预约直播, 11月18日即明晚(周四)八点,小y将用半个小时为大家揭晓真相,用正确的方法论来查明问题真相。记得叫上你家开发同学一起哦,索引他们建的最多了,其中风险还是建议了解下!!
更多实战分享和风险提示,请关注公众号:“中亦安图”和“中亦安图服务号”以及视频号:“小y-黄远邦-中亦”和“中亦安图”!也可以加小y微信,shadow-huang-bj,进微信群探讨技术。喜欢就转发吧,您的转发是我们持续分享的动力!

