





想象一下,你编写了一个程序来解决一个并行问题,每个线程都完成自己独立的工作,线程之间不需要进行协调,只需要在最后将结果合并。显然,你期望它在运行的核心数越多时速度越快。你首先在笔记本电脑上对其进行了基准测试,确实发现它在所有4个可用核心上的扩展几乎完美。然后你在一台大型、高级的多处理器机器上运行它,期望获得更好的性能,但事实上它的运行速度比笔记本电脑慢,无论你给它多少个核心。嗯,最近我就遇到了这样的情况。
最近我一直在开发一个名为Latte的Cassandra基准测试工具,它可能是你能得到的最高效的Cassandra基准测试工具,无论是在CPU使用还是内存使用方面。整个想法非常简单:一小段代码生成数据并对Cassandra执行一系列异步CQL语句。Latte循环调用这段代码并记录每次迭代所花费的时间。最后,它进行统计分析并以各种形式展示结果。
基准测试似乎是一个非常适合并行化的问题。只要被测试的代码是无状态的,就可以相对简单地从多个线程中调用它。我在之前的博文中已经介绍了如何在Rust中实现这一点。
然而,在我写下那些早期博文的时候,Latte的工作负载定义能力相当有限。它只提供了两个预定义的硬编码工作负载,一个用于读取,另一个用于写入。你可以对一些参数进行调整,例如表列的数量或大小,但没有什么特别的。没有二级索引。没有自定义过滤条件。对CQL文本没有控制权。真的什么都没有。因此,总体而言,当时的Latte更多是一个概念验证工具,而不是一个用于实际工作的通用工具。当然,你可以fork它并在Rust中编写一个新的工作负载,然后从源代码编译所有内容。但是,谁想要浪费时间去学习一个小众基准测试工具的内部机制呢?
之前,为了能够测量Cassandra中存储附加索引的性能,我决定将Latte与一个脚本引擎集成,以便能够轻松定义工作负载,而无需重新编译整个程序。经过一番尝试将CQL语句嵌入到TOML配置文件中(结果既混乱又有限),以及在Rust中嵌入Lua(在C世界可能很棒,但与我预期的Rust并不那么兼容,虽然它基本上可以工作),最终我采用了类似sysbench的设计,但使用了嵌入的Rune解释器代替Lua。
我被Rune所吸引的主要卖点是与Rust的无缝集成以及对异步代码的支持。由于异步支持,用户可以直接在工作负载脚本中执行CQL语句,利用Cassandra驱动程序的异步特性。此外,Rune团队非常乐于助人,在几乎没有时间的情况下解决了我遇到的任何问题。
以下是一个完整工作负载的示例,用于测量通过随机键选择行的性能:
const ROW_COUNT = latte::param!("rows", 100000);const KEYSPACE = "latte";const TABLE = "basic";pub async fn schema(ctx) {ctx.execute(`CREATE KEYSPACE IF NOT EXISTS ${KEYSPACE} \WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : 1 }`).await?;ctx.execute(`CREATE TABLE IF NOT EXISTS ${KEYSPACE}.${TABLE}(id bigint PRIMARY KEY)`).await?;}pub async fn erase(ctx) {ctx.execute(`TRUNCATE TABLE ${KEYSPACE}.${TABLE}`).await?;}pub async fn prepare(ctx) {ctx.load_cycle_count = ROW_COUNT;ctx.prepare("insert", `INSERT INTO ${KEYSPACE}.${TABLE}(id) VALUES (:id)`).await?;ctx.prepare("select", `SELECT * FROM ${KEYSPACE}.${TABLE} WHERE id = :id`).await?;}pub async fn load(ctx, i) {ctx.execute_prepared("insert", [i]).await?;}pub async fn run(ctx, i) {ctx.execute_prepared("select", [latte::hash(i) % ROW_COUNT]).await?;
您可以在README中找到有关如何编写这些脚本的更多信息。
对基准测试程序进行基准测试
虽然这些脚本尚未被即时编译为本机代码,但它们的执行速度仍然可接受。由于它们通常包含的代码量有限,因此在性能分析中它们不会成为主要瓶颈。根据我的经验,Rust-Rune FFI的开销比mlua提供的Rust-Lua要低,可能是由于mlua采用的安全检查机制。
最初,为了评估基准测试循环的性能,我创建了一个空脚本:
pub async fn run(ctx, i) {}
即使没有函数体,基准测试程序仍然需要执行一些工作来实际运行它:
使用buffer_unordered调度N个并行异步调用
为Rune虚拟机设置一个新的本地状态(例如堆栈)
调用Rust端传递的参数来调用Rune函数
测量完成每个返回的future所需的时间
收集日志、更新HDR直方图并计算其他统计信息
使用Tokio线程调度器在M个线程上运行所有这些操作
在我使用定频3 GHz的Intel Xeon E3-1505M v6处理器的旧4核笔记本电脑上,结果非常有希望:
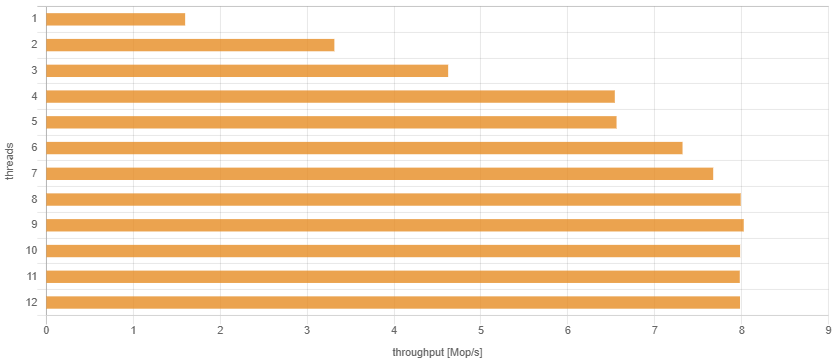
因为有4个核心,吞吐量可以线性增加,直到4个线程。然后,由于超线程技术可以从每个核心中挤出更多性能,吞吐量在8个线程时稍微增加。显然,在超过8个线程后就没有性能改进了,因为此时所有的CPU资源都已饱和。
我对获得的绝对数字也感到满意。在笔记本电脑上每秒几百万次的空调用听起来意味着基准测试循环足够轻量级,不会在实际测量中造成重大开销。在同一台笔记本电脑上启动的本地Cassandra服务器在完全负载时只能达到每秒大约20万个请求,而且仅当这些请求非常简单且所有数据都适应内存时才能实现。
顺便说一句,当在函数体中添加一些真实的数据生成代码,但没有调用数据库时,正如预期的那样,所有的操作都会变慢,但不会超过2倍,仍然在“每秒数百万次操作”的范围内。
这很容易。我本可以在这里停下来并宣布胜利。然而,我很好奇如果在具有更多核心的大型机器上尝试,它能有多快。
在24个核心上运行一个空循环
一个具有两个Intel Xeon CPU E5-2650L v3处理器的服务器,每个处理器有12个核心,运行频率为1.8 GHz,显然比旧的4核笔记本电脑快得多,不是吗?好吧,也许如果只有1个线程的话,由于较低的CPU频率(3 GHz对比1.8 GHz),可能会变慢,但它应该通过拥有更多核心来弥补这一点。
让数据说话:
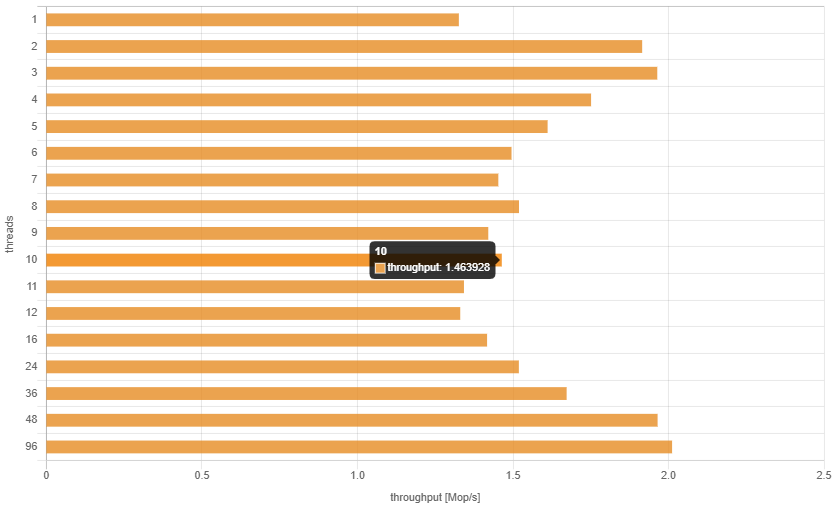
你会同意这里有些问题。两个线程比一个线程要好...基本上就是这样。我无法获得比每秒大约200万次调用更高的吞吐量,这大约是我在笔记本电脑上获得的吞吐量的4倍差。要么这台服务器有问题,要么我的程序存在严重的可扩展性问题。
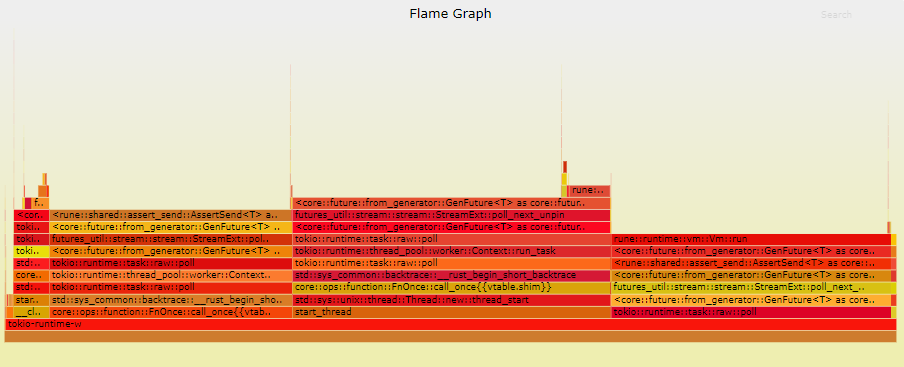
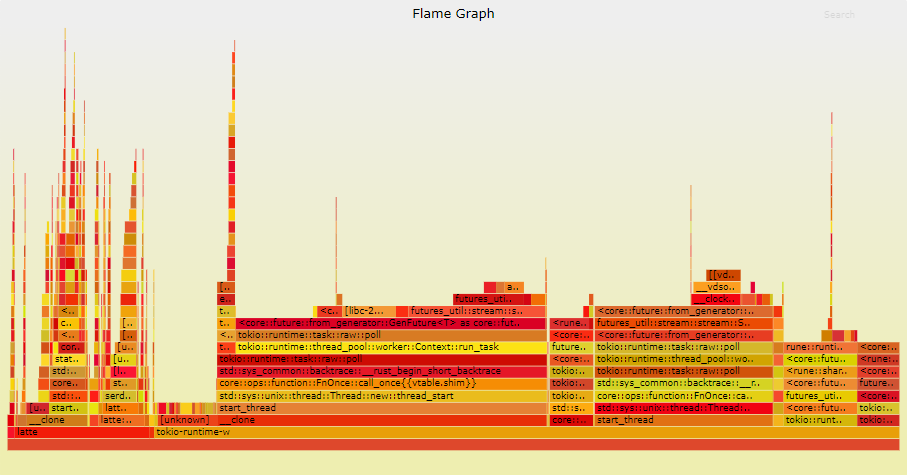
调查 当遇到性能问题时,最常见的调查方法是使用性能分析器运行代码。在Rust中,使用cargo flamegraph可以很容易生成火焰图。让我们比较在使用1个线程和12个线程运行基准测试时收集到的火焰图:
// Executes a single iteration of a workload.// This should be idempotent –// the generated action should be a function of the iteration number.// Returns the end time of the query.pub async fn run(&self, iteration: i64) -> Result<Instant, LatteError> {let start_time = Instant::now();let session = SessionRef::new(&self.session);let result = self.program.async_call(self.function, (session, iteration)).await.map(|_| ()); // erase Value, because Value is !Sendlet end_time = Instant::now();let mut state = self.state.try_lock().unwrap();state.fn_stats.operation_completed(end_time - start_time);// ...Ok(end_time)}
这样可以在48个线程上轻松达到每秒超过1亿次的调用!因此问题肯定出现在Program::async_call函数以下的某个地方:
// Compiled workload programpub struct Program {sources: Sources,context: Arc<RuntimeContext>,unit: Arc<Unit>,}// Executes given async function with args.// If execution fails, emits diagnostic messages, e.g. stacktrace to standard error stream.// Also signals an error if the function execution succeeds, but the function returns// an error value.pub async fn async_call(&self,fun: FnRef,args: impl Args + Send,) -> Result<Value, LatteError> {let handle_err = |e: VmError| {let mut out = StandardStream::stderr(ColorChoice::Auto);let _ = e.emit(&mut out, &self.sources);LatteError::ScriptExecError(fun.name, e)};let execution = self.vm().send_execute(fun.hash, args).map_err(handle_err)?;let result = execution.async_complete().await.map_err(handle_err)?;self.convert_error(fun.name, result)}// Initializes a fresh virtual machine needed to execute this program.// This is extremely lightweight.fn vm(&self) -> Vm {Vm::new(self.context.clone(), self.unit.clone())}
Vm::new(self.context.clone(), self.unit.clone())
代码看起来相当无害。这里没有锁、互斥锁、系统调用或共享可变数据。有一些只读结构 context 和 unit 在 Arc 后面共享,但只读共享不应该是问题。
VM::new 也很简单:
impl Vm {// Construct a new virtual machine.pub const fn new(context: Arc<RuntimeContext>, unit: Arc<Unit>) -> Self {Self::with_stack(context, unit, Stack::new())}// Construct a new virtual machine with a custom stack.pub const fn with_stack(context: Arc<RuntimeContext>, unit: Arc<Unit>, stack: Stack) -> Self {Self {context,unit,ip: 0,stack,call_frames: vec::Vec::new(),}}
然而,无论代码看起来多么无害,我还是喜欢对我的假设进行双重检查。我使用不同数量的线程运行了该代码,并且尽管它现在比以前快,但它仍然没有扩展性 - 它的吞吐量达到了每秒约400万次调用的上限!
问题所在
即使代码看起来非常简单,没有锁、互斥体、系统调用或共享的可变数据,这里确实有一些微妙的隐藏的共享和可变数据:Arc 引用计数本身。这些计数器在所有的调用中都是共享的,并且在多个线程之间进行变化,这就是问题的源头。
有人可能会争论,原子增加或减少共享的原子计数器不应该是问题,因为这些操作只是“无锁”的。它们甚至可以转换为单个汇编指令(例如 lock xadd)!如果一条指令只需要一条汇编指令,那就不会很慢,对吗?然而,这种推理是有问题的。
问题的根本原因实际上并不是计算,而是维护共享状态的成本。
读取或写入数据所需的时间主要受到 CPU 核心需要访问数据的距离的影响。以下是根据这个网站上提供的信息,Intel Haswell Xeon CPU 的典型延迟:
L1 缓存:4 个周期 L2 缓存:12 个周期 L3 缓存:43 个周期 RAM:62 个周期 + 100 ns
L1 和 L2 缓存通常是每个核心(L2 可能被两个核心共享)的本地缓存。L3 缓存被 CPU 的所有核心共享。不同处理器之间的 L3 缓存之间还有一个直接的互联,用于管理 L3 缓存的一致性,因此 L3 在逻辑上是在所有处理器之间共享的。
只要你不更新缓存行并且只从多个线程中读取它,该行将被多个核心加载并标记为共享。很可能这些对数据的频繁访问将从 L1 缓存中提供服务,而 L1 缓存非常快速。因此,共享只读数据是完全可以接受的,并且可以很好地进行扩展。即使在只读情况下使用原子操作,性能也足够好。
然而,一旦引入对共享缓存行的更新,情况就开始变得复杂起来。x86-amd64 架构具有一致的数据缓存。这基本上意味着在一个核心上写入的数据可以在另一个核心上读取。在多个核心上无法存储具有冲突数据的缓存行。一旦线程决定更新共享的缓存行,该行就会在所有其他核心上失效,因此在这些核心上的后续加载将不得不从至少
L3 缓存中获取数据。这显然要慢得多,如果主板上的处理器超过一个,那么速度就更慢了。
事实上,我们的引用计数器是原子的,这是问题更复杂的另一个原因,它使处理器的情况变得更加复杂。尽管原子操作通常被称为“无锁编程”,但实际上,在硬件层面上需要进行一些锁定操作。只要没有拥塞,这种锁定是非常细粒度且廉价的,但和其他锁定一样,如果有很多线程同时竞争同一个锁,那么性能将非常差。如果这些“东西”是整个 CPU 而不仅仅是接近彼此的单个核心,那么情况就更糟了。
修复
// Makes a deep copy of context and unit.// Calling this method instead of `clone` ensures that Rune runtime structures// are separate and can be moved to different CPU cores efficiently without accidental// sharing of Arc references.fn unshare(&self) -> Program {Program {sources: self.sources.clone(),context: Arc::new(self.context.as_ref().clone()), // clones the value under Arc and wraps it in a new counterunit: Arc::new(self.unit.as_ref().clone()), // clones the value under Arc and wraps it in a new counter}}
Vm::new(self.context.clone(), self.unit.clone())
这是因为self.context和self.unit不再在线程之间共享。对于非共享计数器的原子更新幸运地非常快速。
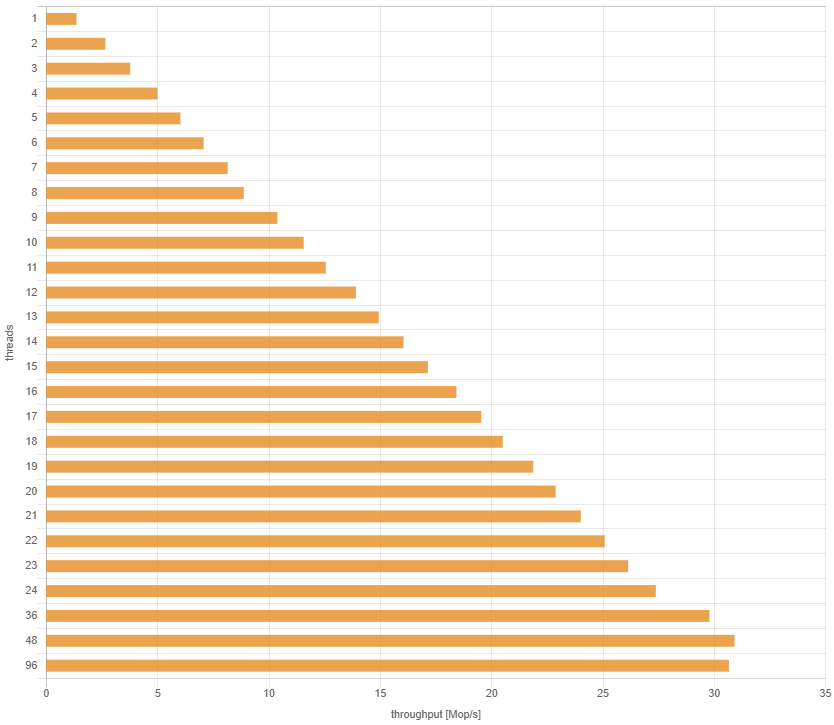
最终结果 现在,吞吐量按预期线性增加,直到24个线程:
要点
如果在多个线程上频繁更新共享的Arc对象,那么在某些硬件配置上的成本可能非常高。
不要认为单个汇编指令不会成为性能问题。
不要认为如果某个程序在单CPU计算机上良好地扩展,那么它在多CPU计算机上仍然能够扩展。
