






“把大象装冰箱总共要几步”来自于赵本山、宋丹丹的小品《钟点工》中的经典桥段。在这个小品里面,宋丹丹假装严肃的提了一个问题:“说,要把大象装冰箱,总共分几步?” 老赵本来就腼腆型的,一听懵了。正常我们都会想:大象怎么装冰箱?宋丹丹没忍住噗嗤乐了,“三步,把冰箱门打开,大象塞进去,关上冰箱门”。

国内私有云:把公有云装进自己的数据中心需要分几步?
最近几年,国内中大型企业,如大型国有银行,掀起了一股热潮,就是想把公有云装进自己的数据中心。既要利用公有云的优势,又要满足自己对安全性的要求以及满足监管要求。那么,私有云如何才能把公有云装进自己的数据中心呢?
笔者这里所说的“公有云”,不是真正的阿里云腾讯云这种公有云,而是这些国内头部公有云厂商所提供的专有云版本,比如腾讯专有云企业版TCE、阿里云专有云(Apsara Stack)。以TCE为例,其官方介绍是这样的:“腾讯专有云企业版(简称 Tencent TCE)是基于腾讯云成熟产品体系的企业级专有云平台,为企业提供自主可控、弹性伸缩的全栈服务能力。TCE 基于腾讯公有云技术栈实现,产品路径和公有云保持一致,包括虚拟化、SDN、分布式存储、云原生安全等能力都沿袭了公有云,确保技术栈一致。”
当下,在非互联网金融领域,银行之类的金融机构是没法光明正大地使用公有云的。公有云厂商所提供的专有云产品,实质上是一个面向企业私有云场景的公有云裁剪版。写到这里,突然想到阿里巴巴王坚博士在《在线》一书中反复地坚定地写道“我没听说过私有云。客观来说,私有云是不存在的,是个假命题”,不知道王博士是如何看待阿里云专有云的。
要把公有云装进企业和机构自己的数据中心,大概总共要四步。
第一步,把公有云的IaaS装进自己的数据中心
2020年,笔者写过一篇文章,年终盘点 | 2020年,国内私有云正式进入3.0时代,文中说过为什么中大型企业和机构的私有云基座正在向公有云技术栈演进,这里不再赘述。
从这几年实际发展情况来看,当年笔者的看法基本上依然成立。比如,从公开招标的资料看,建行云在利用腾讯专有云TCE的IaaS,工行云在利用华为专有云的IaaS,刚刚发布号称要“全力打造国家级金融云平台”的央行金电云有三家技术合作伙伴:中国电子云、腾讯云、华为云。
应该说,把公有云IaaS以专有云部署的形式装进自己的数据中心,这是一个相对容易的事情。从各大银行私有云的做法来看,主要有两种做法:一是单一来源,就是利用一家的专有云,比如工行云和建行云;二是利用多家的专有云技术栈,比如金电云。
笔者认为,这两种做法倒不是二选一,而是一种递进式发展关系。在一开始,先玩转一家专有云技术栈,玩得差不多的就可以引入第二家甚至第三家了。这么做的好处是,可以在私有云的IAAS层实现所谓的“云中立”,就是不依赖单一厂商。
这么做的另一个原因是,这些企业和机构靠自己的IT力量是啃不动专有云产品的,只能依赖厂商,而为了避免厂商绑定,那就只能引入第二家甚至第三家。还有一个原因是,现在国家几家头部专有云的IaaS还是有较高技术含量的,产品上基本上已经标准化了,需要定制的地方越来越少了,实际上利用这种技术栈构建私有云的企业和机构也没那么必要再在IaaS上做很大的投入了。
第二步,基于专有云IaaS,自己利用K8S做统一PaaS平台
我们来看一个类似案例。2023 年2月在北京举行的QCon全球软件开发大会上,OPPO 云服务中心高级总监韩建飞发表了题为《OPPO 全球混合云建设之路》的演讲。据介绍,OPPO 在全球有逾 5 亿用户,为了在全球范围内更好地为 5 亿用户提供技术支持,OPPO打造了安第斯智能云。演讲中分享的OPPO的安第斯智能云管理平台架构如下图所示。
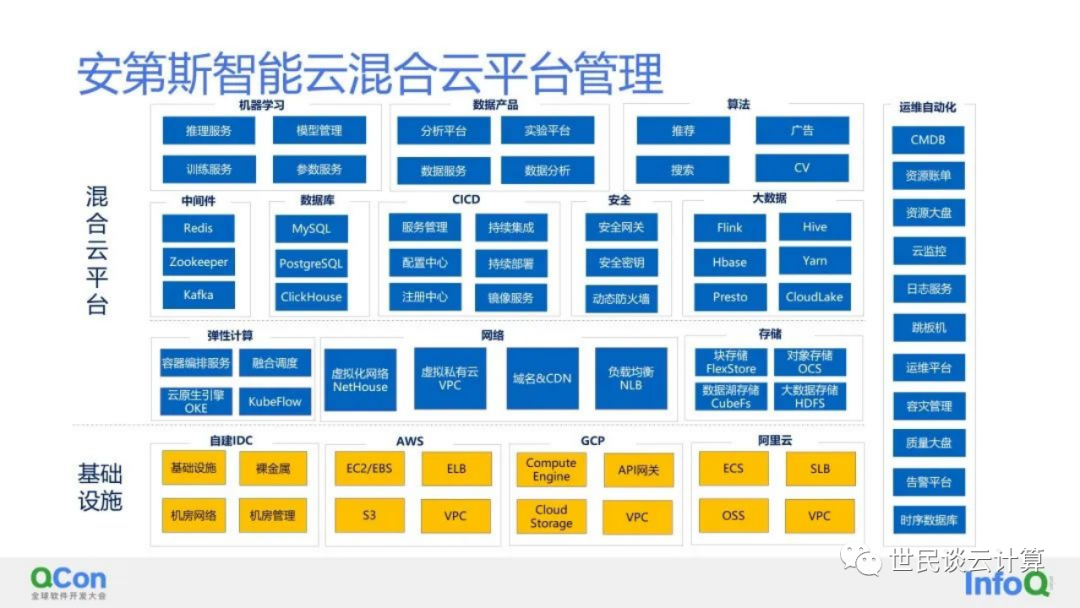
在基础设施层,OPPO 在国内自建有12万台机器的数据中心。在海外,OPPO依托公有云的能力快速扩容和全球化。这种架构,其实和国内一些大型金融机构的私有云基础设施层架构是差不多的。区别在于,这些私有云的机房是自己管理的,而机房里面部署的是公有云厂商提供的专有云产品,提供着类似公有的能力。在基础设施层,OPPO主要使用公有云的虚拟机、块存储、负载均衡等在各家公有云上相对标准的云服务。
在基础设施层之上,OPPO构建了混合云平台层。其中,基于K8S的混合、编排、调度的能力,同时配合网络及存储,在部分场景实现了多租户,并在此上构建整个业务平台和运维管理服务,并自研了中间件、数据库所有能力。
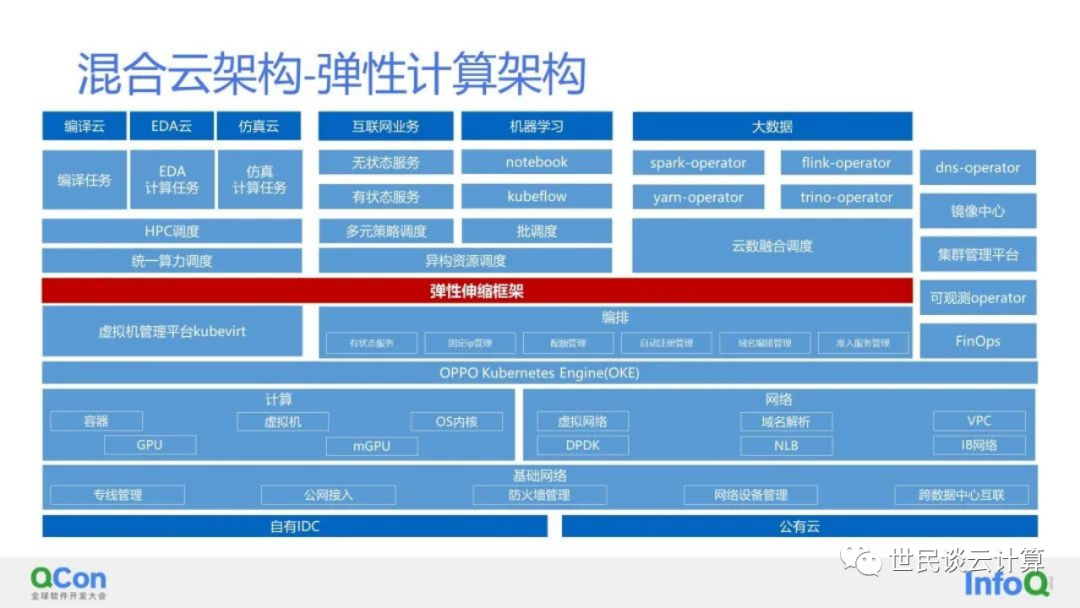
笔者在多家大型金融机构的云计算方案中都看到OPPO这个方案的影子。究其这么做的原因,笔者认为主要有几个:
PAAS层为应用服务,需要快速响应应用的需求,而依赖专有云厂商的话,往往无法得到快速响应,就无法支持自身业务的快速需求。
现在国内多个专有云的PaaS层和其IaaS层相比,水平差距很大。很多PaaS层服务,也都是基于开源项目进行二次开发的。比如基于K8S包装出一个容器云平台,基于mysql包装出一个数据库服务,基于kafka包装出一个消息中间件服务,比如基于lvs和Nginx包装出负载均衡服务等等。金融机构认为,你们公有云厂商包得,为什么我们自己就包不得?
很多大中型金融机构对中间件和数据库还是有比较长期的积累的,早年前就基于开源项目进行自我学习和二次封装,具备一定的二次开发能力,也比较长时间服务了自己的业务,因此具有一定的人员和技能基础。
K8S越来越成熟,而应用容器化乃至云原生化逐步成为主流,那么,投入一些人力去做K8S,让它屏蔽底层IAAS层差异,为应用提供统一的平台,这种做法投入回报比还是很可观的,对这些大中型机构来说是一个很好的选择。
2022年11月,InfoQ发表的一篇关于工行云的文章《工商银行十年磨砺:建成同业最大规模云计算平台,既要开源又得可控》,介绍了工行PaaS云的发展历程。
工行云PaaS团队聚焦容器领域的建设,主要职责是跟进云计算方向最新的技术趋势,开展新技术前瞻性研究和原型验证工作,同时推进平台能力建设,支持应用上云。目前,工行PaaS 研发团队有 50 人左右,涉及有状态容器、无状态容器及配套运维监控等技术方向。
不同于工行云IaaS 层面以厂商产品为主,PaaS 层主要是基于开源产品自主研发。2015 年,PaaS团队已经基于开源 Docker 容器技术,建设应用平台云 PaaS 1.0。2016 年,PaaS 团队开始着手调研业界容器编排产品,包括 Kubernetes、Swarm、Openshift等。2017 年,基于 Kubernetes 的 PaaS 2.0 应用云平台正式上线。
PaaS 团队还牵头建立了云上 DevOps 工具链,对 Deployment 等资源对象进行抽象,封装成模板、构建包等概念,尽可能屏蔽 Kubernetes 底层技术细节,并与行内 DevOps 体系衔接,支持全链路自动化上线,降低应用上云成本。
PaaS 团队已实现涵盖 MySQL、Redis、ElasticSearch、ZooKeeper 等多种有状态应用的容器化部署,其中 MySQL 容器上云率已达到 90% 以上。
当前,工商银行容器规模早已超过 30 万,全面承载包括核心银行业务系统在内的众多应用。
工行云对其云平台的上层服务,如容器、中间件和数据库等,提出了较高的自主可控要求。工行云PaaS的这种发展路线,已被越来越多金融机构的选择。
王坚博士在《在线》中写道:“云计算相当于发电产业,云存储相当于钢铁产业,而大数据就是福特汽车生产线”。可见,大数据对一个企业来说是多么重要。
2022年1月,InfoQ发表一篇文章《工商银行实时大数据平台建设历程及展望》,介绍了工行大数据平台的发展历程。从中,我们得以一窥国有大行的大数据发展历程。
从2002年到目前为止的20余年中,工行大数据经历了数据集市(2002-2007)、数据仓库(2008-2013。基于Teradata,这个公司后文还会提到)、大数据服务云(2014-2019,基于Hadoop和Spark等)、数据中台(2020年至今)等几大阶段。

从2002年开始建设数据集市,当时主要使用Oracle类单机版的关系型数据库。随着数据量不断增加,开始引入 TD、ED 等国外高端一体机。2014 年工行正式基于Hadoop技术建设了大数据平台,在其之上构建了企业级数据湖及数据仓库。2017 年,随着 AI 技术的兴起,又开始建设机器学习平台,2020 年开始建设数据中台和高时效类场景。
在笔者看来,工行这种大数据发展历程,在金融领域具有较广泛的代表性。但是,这种大数据平台建设模式,还是传统模式。
技术上,这种传统大数据集群往往构建在物理机之上,大数据集群和云计算平台是分离的。因为数据量巨大,数据保存要求时间长,这些大行往往需要用到几千乃至万台服务器,利用Hdfs和Hadoop套件做离线数据存储和离线数据处理,利用Spark和Flink等进行实时数据处理和提供实时数据服务。
在组织形式上,可能是下图中的样子。云计算团队负责云平台,大数据团队负责大数据平台,团队之间隔着厚厚的部门墙。数据开发团队基于大数据平台,采集业务系统所提供的各类数据,进行数据处理后,将结果数据保存到数据表中;应用研发团队基于数据表开发数据服务以及业务应用,业务应用调用数据服务来查询和增删改查数据等,同时将所产生的数据同步到大数据平台中。
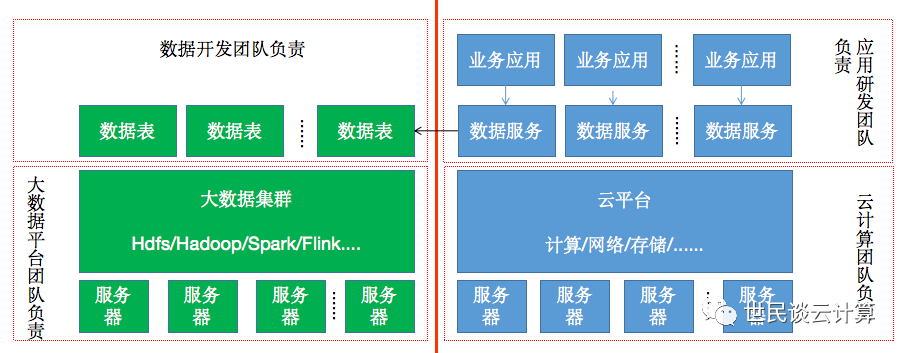
这种技术架构和组织形式的主要问题有:
大数据平台无法利用云平台提供的存储弹性,比如不是采用云平台提供的对象存储,而是采用大量的服务器在HDFS中存放数据。
大数据平台无法利用云平台提供的计算弹性,需要自己提供计算能力,而不是利用云平台提供的计算能力。而大数据平台中的计算能力往往是和存储能力在一台服务器之上,无法做到计算和存储分离。
业务应用和大数据平台之间存在大量的数据同步需求,一份数据往往多份多地保存,浪费存储容量。
对于大数据平台团队来说,需要把很多精力花在服务器、计算、存储等方面,没法集中精力搞数据方面的事情。
云原生大数据服务构建在云平台之上,充分利用云平台所提供的计算和存储的资源和弹性能力,自己则把精力集中到数据处理和服务提供上。新型云原生数据仓库的典型代表是Snowflake。它是一个以SaaS形式运行在公有云上的云原生企业级数据仓库服务,不能在本地数据中心内运行。2012年开始研发,2014年正式推出。
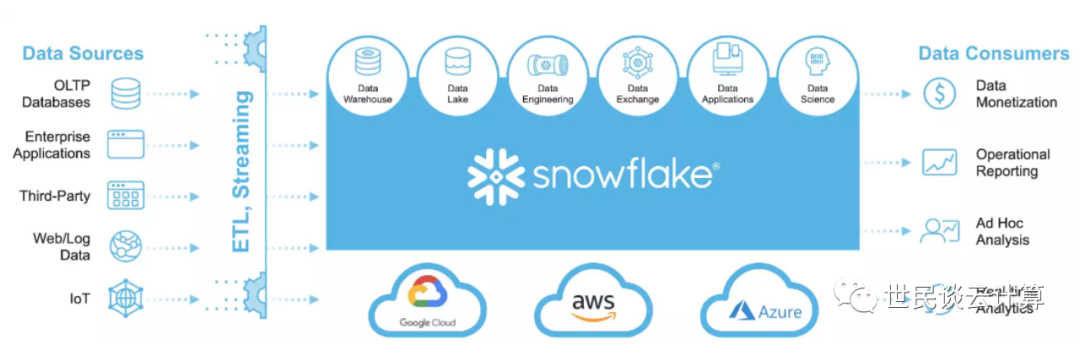
2016年,Snowflake发表了论文《The Snowflake Elastic Data Warehouse》,对其设计理念和整体架构做了整体的介绍。Snowflake在Shared-nothing的基础上提出了Multi-Cluster, Shared Data Architecture的概念,这种架构的关键在于将存储和计算彻底分离,从本质上解决了传统Share Nothing架构的痛点。
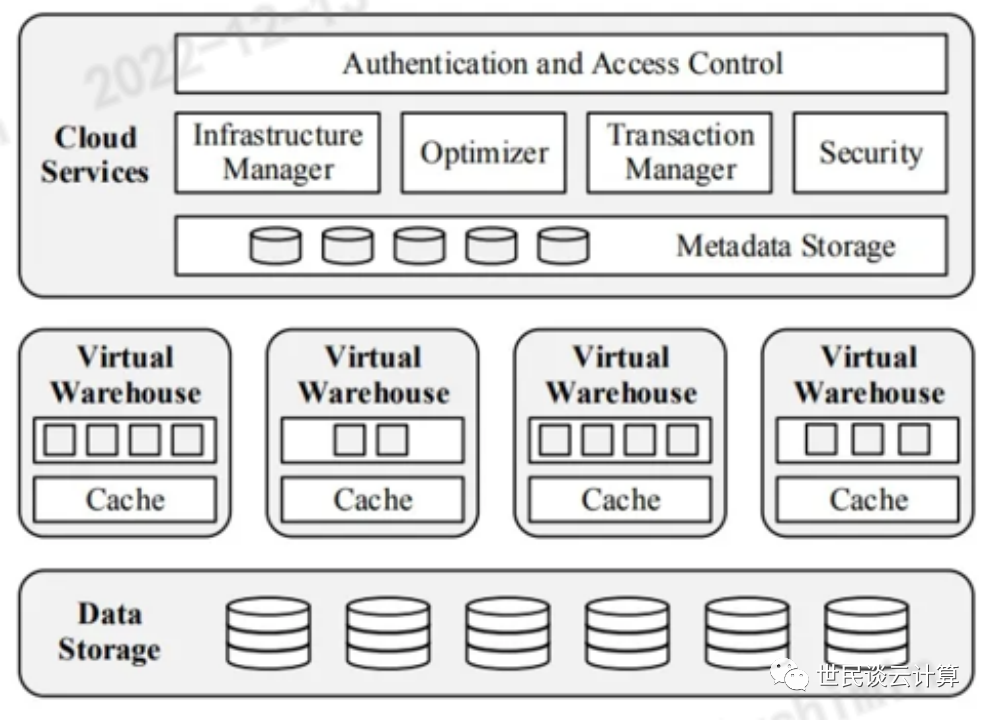
服务层是多租户的,负责执行用户的查询请求。Snowflake使用抽象的T-shirt尺寸的概念来定义VMs的算力。
计算层包括处理数据的虚拟机节点,Virtual Warehouse(VW)层包含集群的EC2实例。
存储层使用AWS S3、Azure Blob、Google Storage三大对象存储来存储表数据和查询结果。
Snowflake的典型特征主要有:
存储和计算分离 | 计算和存储采用两个不同的集群,直接利用公有云上的计算和存储服务 |
计算弹性 | 用户可以在没有任何查询的情况下可关闭所有的计算资源。这种弹性使得用户可根据实际的使用需求来动态地匹配计算资源,而不依赖于数据量大小。 |
存储弹性 | 云厂商提供的共享、无限的对象存储意味着用户可以共享和集成他们所有的数据。 |
云原生 | Snowflake是建立在云上的数据仓库,data-warehouse-as-a-service(DaaS)。自2014年以来,Snowflake就在Amazon S3上运行,从2018年开始就在Microsoft Azure上运行。于2019年在Google Cloud Platform上推出。通过支持多云,避免了用户的“云锁定”问题。 |
商业模式 - 按需付费 | 采用按需付费模式,基于云的弹性,客户可以根据自己的实际消耗进行购买,即用多少买多少。计算与存储是Snowflake的两大定价系统。存储费用按照实际存储的数据量计费。计算费用只需付费自己所使用的部分。如果客户目前想要停止运行,可以选择“暂停模式”,暂时停止记录积分。等到客户继续使用的时候,数据库会自动计费。操作简便,节约成本。 |
Serverless | 用户不需要关心和管理计算和存储资源,只需要导入数据并进行分析,底层资源自动根据负载弹性伸缩。 |
混合架构 | 既利用了shared-disk 架构的性能上的优势,又利用了shared-nothing架构在弹性上的优势。 |
这种云原生类型的大数据平台,能充分利用云平台所提供的能力和弹性,自己专注做好大数据处理和服务,而把计算、存储、底层弹性等要求由云平台实现。对用户来说,其Serverless特性让用户不需要关心和管理计算和存储资源。
笔者认为,云原生大数据服务也将是未来私有云中大数据服务的发展方向,也将象专有云IAAS那样进入企业和机构的自有数据中心,但其落地还为时尚早,甚至还需要几年时间,主要原因有:
企业和机构未能充分理解和认识到云计算的价值,不知道如何在大数据领域中利用云平台的能力。
国内厂商还不能提供Snowflake这种新型的云原生大数据平台。当下,提供传统大数据平台的公司仍然大行其道,所做的只是在传统产品之上戴上了一顶数据中台的华丽帽子。
企业和机构现在更重视数据的量,往往以有多少PB的数据和大数据平台有几千几万台节点为荣,但而未能充分意识到,数据如果不能被很好地使用、充分地给业务带来价值,这种数据是死数据,而不是大数据。这几年,数据治理大行其道,一方面说明企业和机构的数据之乱,另一方面也说明企业和机构也开始重视对数据的使用。国内企业和数据的数字化水平,导致其数据利用的需求没有被充分地打开,同时,数据也不知道如何支持业务。国家一直在强调数据的重要性,但传统企业和金融机构如何利用数据来促进业务转型发展,一直还在摸索中。
组织结构上,大数据平台部门和云计算平台部门往往是两个独立的部门,两者之间缺乏有效的衔接和合作。
王坚博士在《在线》中写道:“一提到大数据,大家就会比谁的数据中心建的更大,谁买的服务器更多,买了10万台服务器的公司一定比隔壁只买5万台机器的公司更厉害”。不得不说王博士是非常接地气的。
除了引入云原生大数据平台之外,还需要对组织结构做适当调整。笔者在年中盘点 | 2022年,PaaS 再升级 一文中建议把大数据平台/服务团队和云平台/服务团队合并到一个部门中。
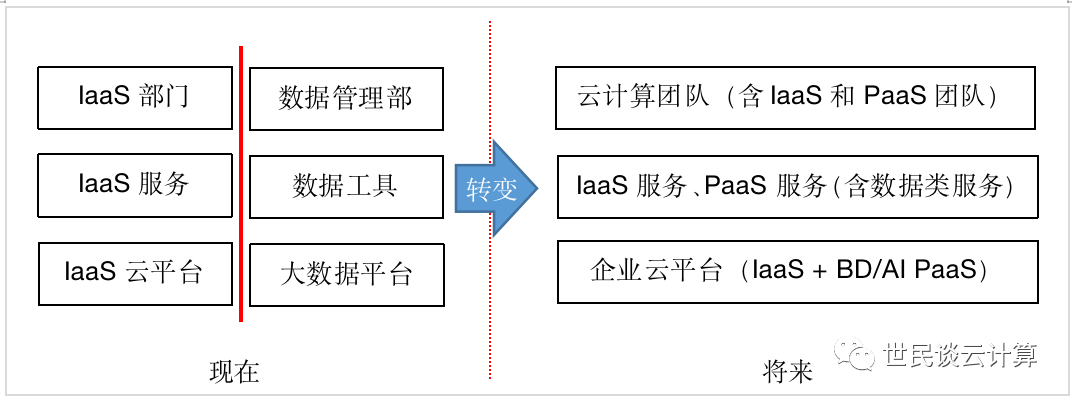
第四步,将公有云的运营理念装进自有数据中心
国内当前传统私有云的运营理念,和公有云的运营理念,是两种完全不同的理念。
传统的私有云,是面向运维和运营人员的。用户要使用私有云,需要给云管理团队提交工单,由管理部门审核后再创建好资源,再提供给用户。
网上搜到一个私有云运营流程,其流程之复杂,其审核环节之多,组织结构之复杂,看着就让人头大。采用这种运营形式的私有云,充其量就是个资源池,根本就不能称为“云”。王坚博士在《在线》一书中写道:“云计算的本质是服务。如果不能将计算资源规模化、大范围地进行共享,如不能真正以服务的方式提供,就根本算不上云计算”。
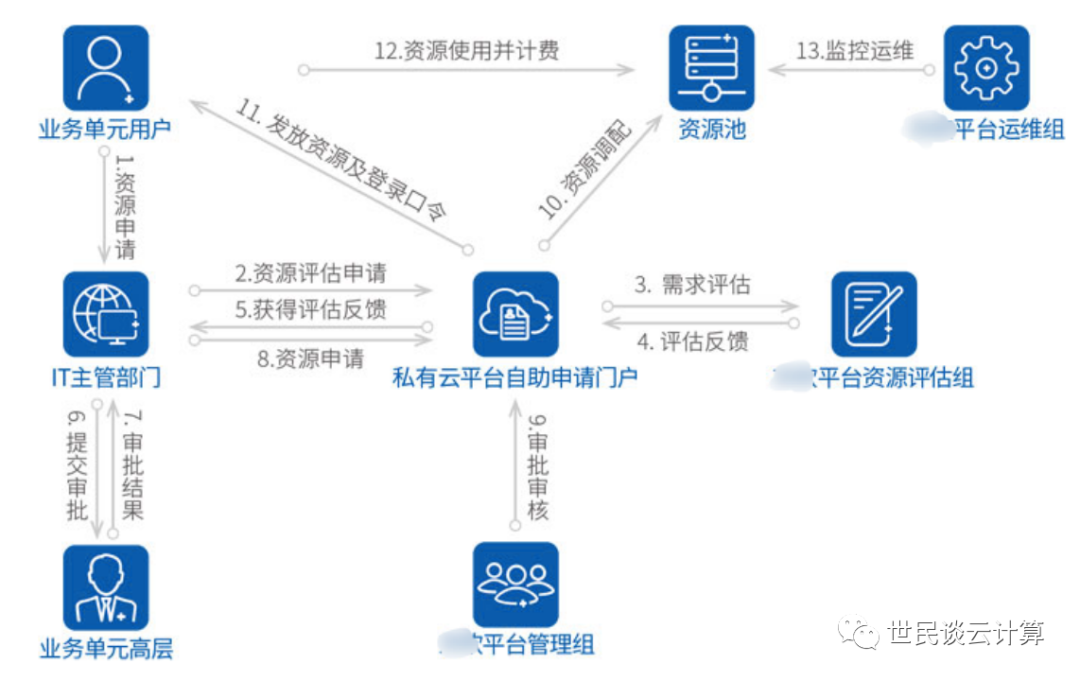
但处于图中C位的IT主管部门看来,是有充足的理由需要这种运营体系的:监管层就是这么要求的、公司管理层就是这么要求的、应用稳定运行要求这么做、应用安全保障要求这么做等等。至于什么云计算的敏捷、弹性、丰富的产品、用户使用体验之类的,这些东西都有,都在ppt里面放着呢。运行在这种“云”中的应用,就像一个个宠物,被360度呵护,一旦有风吹草动,那可是大事情。
而公有云是面向用户的,提供用户控制台,用户可以可视化地申请和管理云资源和服务;还提供丰富的API,让应用和用户可以通过编写代码来管理和使用云服务。
这两种云使用模式,一种是管控模式,一种是自服务模式。现在,在金融业界,很多大型银行都采用了新云技术栈构建了新的云平台,但是,基本都还是利用原有的管控模式在管理和运营新的云平台。哪个好哪个坏姑且不论,至少从用户便捷性、效率、用户体验等层面,自服务模式有其优势。笔者有一篇文章,是时候把云计算的使用权交给开发者了,文中谈到,云计算的真正用户应该是开发者,而不是运维人员。
小结 - 四步发展历程预测
从国内大型金融机构视角来说,笔者乐观地预测这四步的发展历程可能是这样子(图中时间指的是在金融行业内成为主流的时间):
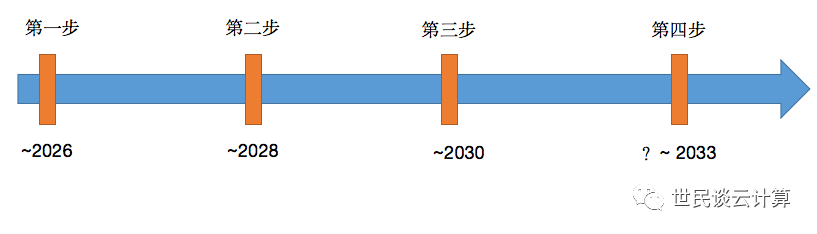
第一步,把公有云IaaS装进自己的数据中心。目前正在进行中,预计到2026年各大行基本能完成。
第二步,基于专有云IaaS,自己利用K8S做统一PaaS平台,并推动应用云原生化。目前正在进行中,预计在2025年能各大行基本能完成平台和体系建设,在2028年差不多能基本完成大部分应用的容器化改造。
第三步,把公有云大数据服务装进自己的IDC。已有少数金融机构在试点,但大规模进入生产估计需要8-10年时间。
第四步,将公有云的运营理念装进自有数据中心。这个笔者无法预测,因为最难改变的其实是人的理念和思想。也许十年后的2033年,情况能有较多的改变吧。
大银行做大事情往往第一步是做规划。对云计算建设来说,往往是3年规划一次,管3到5年时间。如果说最近一次的规划是面向第一步(引入公有云IaaS)和第二步(自建PaaS)的,那笔者认为,下一个规划将是面向数据服务的,其中不只是大数据平台和服务,还有API、区块链、隐私计算等广义上的数据服务。在这个规划中,公有云云原生数据平台和服务将进入金融机构自己的数据中心。
小结 - 对IT业界的影响
私有云技术栈的公有云化,将显著地影响IT产业。
其中一个影响,是面向传统私有云的产品、方案甚至从业人员都将逐步退出历史的舞台。比如基于OpenStack的私有云平台,如今已鲜有大型企业采用这种技术栈来构建私有云了。还有比如传统数仓的代表Teradata。前不久,财经十一人发表了一篇文章《宣布退出中国的美国Teradata,在北美也面临被取代危机》。
Teradata成立于1979年,专注于数据仓库、数据分析、整合营销等企业软件。1997年进入中国大陆市场。巅峰时期,Teradata曾占据中国金融业数据仓库市场50%以上的市场份额。2014年以后,亚马逊AWS开启了全球IT产业的云转型。数据分析的经典解决方案变成了“云+数仓”。“咨询+数仓+一体机”这套捆绑方案变得昂贵、笨重且落伍。
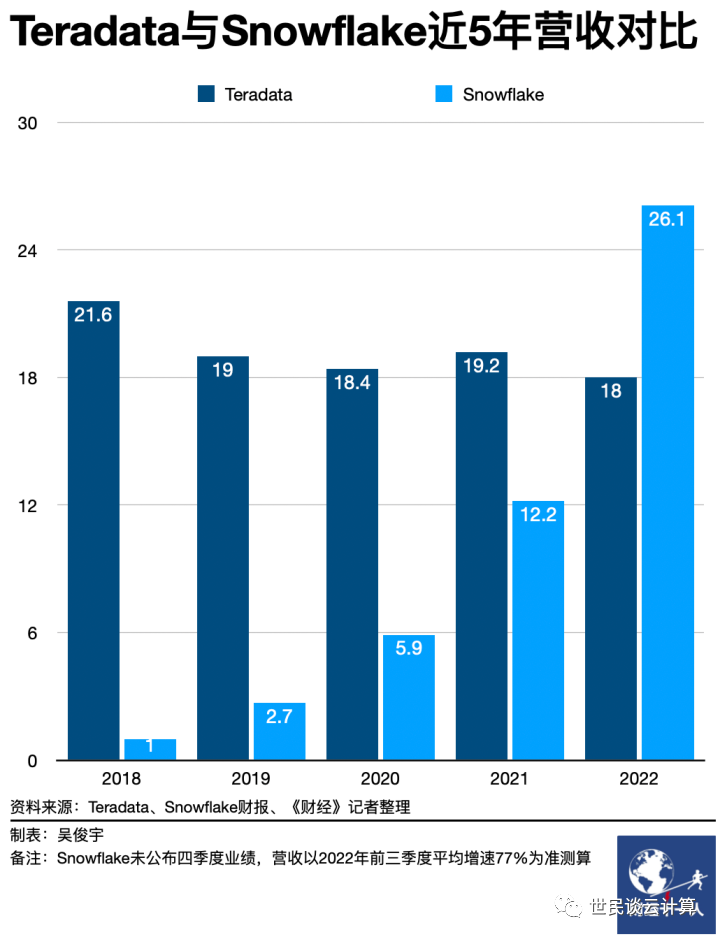
Teradata不仅在中国市场正被国内数仓产品替代,在美国市场同样在被Snowflake等云原生数仓产品替代。在北美主战场,它也正在面临挑战。Snowflake等一批云原生的数据仓库、数据分析企业对其形成了冲击。2018年,Snowflake营收仅为1亿美元,Teradata营收为21.6亿美元。4年后的2022年,Snowflake年营收将超过26亿美元,但Teradata营收不增反减至18亿美元。截至美国东部时间2月22日下午收盘时,Snowflake市值为486亿美元,Teradata市值仅为42亿美元。
财经十一人的文章开头写道:“这家美国企业软件公司曾在中国金融数据仓库市场占据超过50%的市场份额。它的遭遇说明了一个朴素道理:如果你赶不上时代,就很难不被时代抛弃”。其实,不只是公司和产品,对于从业人员来说也是如此:如果你赶不上时代,就很难不被时代抛弃。
国内私有云的未来:存在的就一定是合理的吗?
国内私有云建设大行其道如火如荼,这是很长一段时间以来客观存在的事实。但是,存在的就一定是合理的吗?笔者认为,过去和未来一段时间内,私有云的存在确实有其一定的合理性。但是,从长期来看,私有云不应该是国内云计算未来的主流发展方向。在下一篇文章中亮出笔者的观点之前,这次先放出了Notion AI的观点:

