






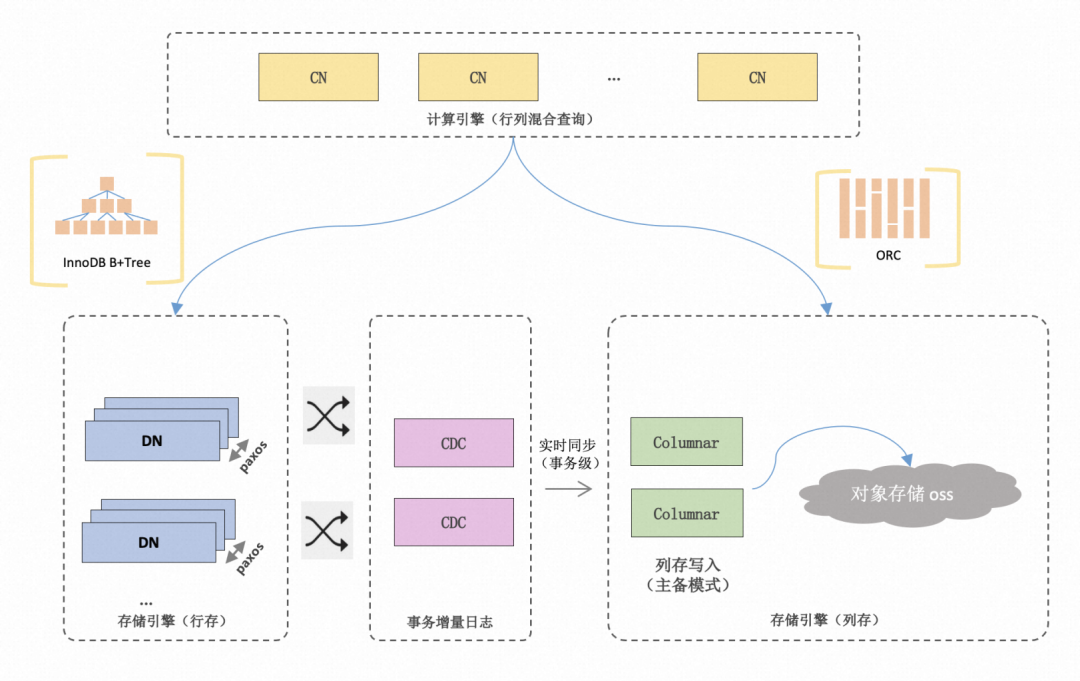
PolarDB分布式版(PolarDB for Xscale,简称:PolarDB-X)作为一款云原生分布式数据库,具有在线事务及分析的处理能力(HTAP)、计算存储分离、全局二级索引等重要特性。在HTAP方面,PolarDB分布式版对于AP引擎的向量化已经有了诸多探索和实践,例如实现了列式内存布局、MPP、面向列存的执行器等高级特性(参考《PolarDB-X 向量化执行引擎》[1]及《PolarDB-X 向量化引擎》[2])。
● 寄存器:
SSE指令集中的128位寄存器XMM0-XMM15;
● Load/Store指令
MOVAPS:每次移动128bits的值。
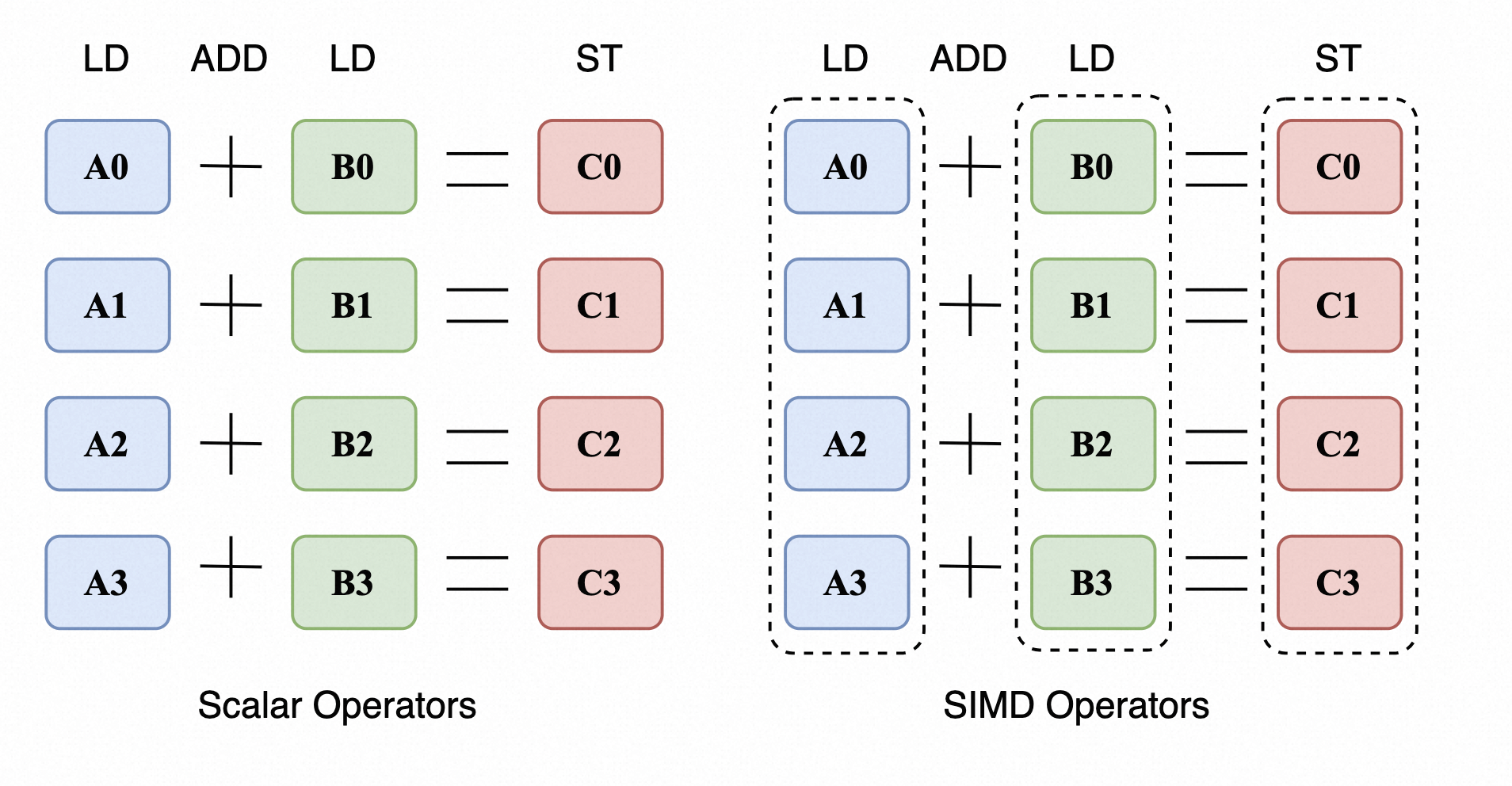
在JDK 17以前,Java并不能主动的调用SIMD指令,但是在JDK 17版本中,Java官方提供了对SIMD指令的封装- Vector API。Vector API提供了IntVector, LongVector等寄存器,其会根据底层CPU自动选择合适的指令集,这使得开发人员无需考虑具体的CPU架构来快速进行SIMD编程。同时它也提供了add, sub, xor, or等操作来进行SIMD运算,以及fromArray, intoArray等来一次性读取多位数据。
Vector API的基本用法
我们以一个数组相加的例子来快速入门Vector API 在Vector API中,每一个Vector代表一个寄存器,其可以存放若干个元素,取决于寄存器的大小和元素类型,例如当寄存器大小为128位时,可以存放4个int类型(每个int占32位)
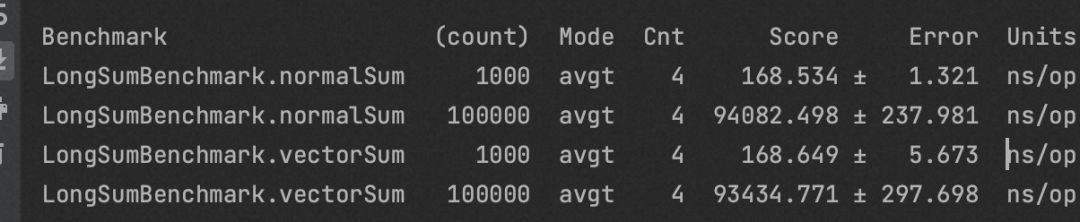
public class LongSumBenchmark {//定义SPECIES,表示Vector的类型private static final VectorSpecies<Long> SPECIES = LongVector.SPECIES_PREFERRED;private int count;private long[] longArr;private long[] longArr2;private long[] longArr3;public void normalSum() {for (int i = 0; i < longArr.length; i++) {longArr3[i] = longArr[i] + longArr2[i];}}public void vectorSum() {int i;int batchSize = longArr.length;int end = SPECIES.loopBound(batchSize); //通过loopBound获取到对齐后的上限for (i = 0; i < end; i += SPECIES.length()) {//fromArray(SPECIES, longArr, i)表示从longArr的第i个位置元素开始取出SPECIES.length()个元素LongVector va = LongVector.fromArray(SPECIES, longArr, i);LongVector vb = LongVector.fromArray(SPECIES, longArr2, i);LongVector vc = va.add(vb); //调用add函数,使用SIMD指令求和//intoArray(longArr3, i)表示将vc寄存器中的内容存入longArr3中i偏移量开始的元素vc.intoArray(longArr3, i);}for(; i < batchSize; ++i) { //剩余的部分需要手动处理longArr3[i] = (longArr[i] + longArr2[i]);}}}
FMA计算
FMA加法是指:c = c + a[i] * b[i]。其中a和b都是float/double类型的数组:
@Benchmarkpublic double normalSum() {double sum = 0;for (int i = 0; i < doubleArr.length; i++) {sum += doubleArr[i] * doubleArr2[i];}return sum;}@Benchmarkpublic double vectorSum() {var sum = DoubleVector.zero(SPECIES);int i;int batchSize = doubleArr.length;var upperBound = SPECIES.loopBound(doubleArr.length);for (i = 0; i < upperBound; i += SPECIES.length()) {DoubleVector va = DoubleVector.fromArray(SPECIES, doubleArr, i);DoubleVector vb = DoubleVector.fromArray(SPECIES, doubleArr2, i);sum = va.fma(vb, sum);}var c = sum.reduceLanes(VectorOperators.ADD);for(; i < batchSize; ++i) {doubleArr3[i] = (doubleArr[i] + doubleArr2[i]);}return c;}
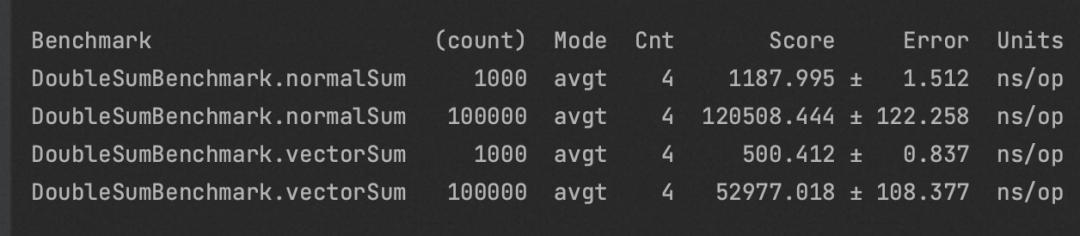
结果分析:
0x00007f764d363902: vfmadd231pd %ymm0,%ymm2,%ymm3
● 标量执行的结果:将乘法和加法拆成了两条指令vmulsd和vaddsd
0x00007f000133050d: vmulsd 0x10(%rax,%r13,8),%xmm0,%xmm00x00007f0001330514: vaddsd %xmm0,%xmm1,%xmm1
由测试结果可以看出,对于FMA计算场景,Vector API将原本需要两条指令的vmulsd和vaddsd合并为了一条指令vfmadd。
但需要注意:FMA计算的优化无法用在数据库中,因为PolarDB-X是将乘法和加法拆为两个算子来执行的。
使用Vector API实现基础SIMD操作
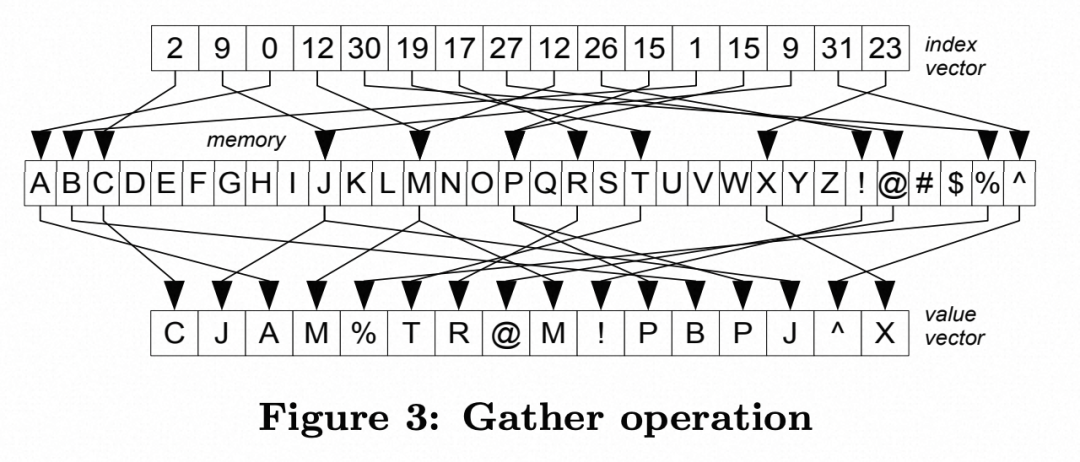
public void gather(int[] source, int[] indexes, int count, int[] target) {for (int i = 0; i < count; i++) {target[i] = source[indexes[i]];}}
public void gather(int[] source, int[] indexes, int count, int[] target) {final int laneSize = INTEGER_VECTOR_SPECIES.length();final int indexVectorLimit = count laneSize * laneSize;int indexPos = 0for (; indexPos < indexVectorLimit; indexPos += laneSize) {IntVector av = IntVector.fromArray(INTEGER_VECTOR_SPECIES, source, 0, indexes, indexPos);av.intoArray(target, indexPos);}if (indexPos < indexLimit) {scalarPrimitives.gather(source, indexes, indexPos, indexLimit - indexPos, target, targetPos);}}
2. Scatter实现:与Gather同理,Vector的intoArray运算提供了对Scatter运算的封装。
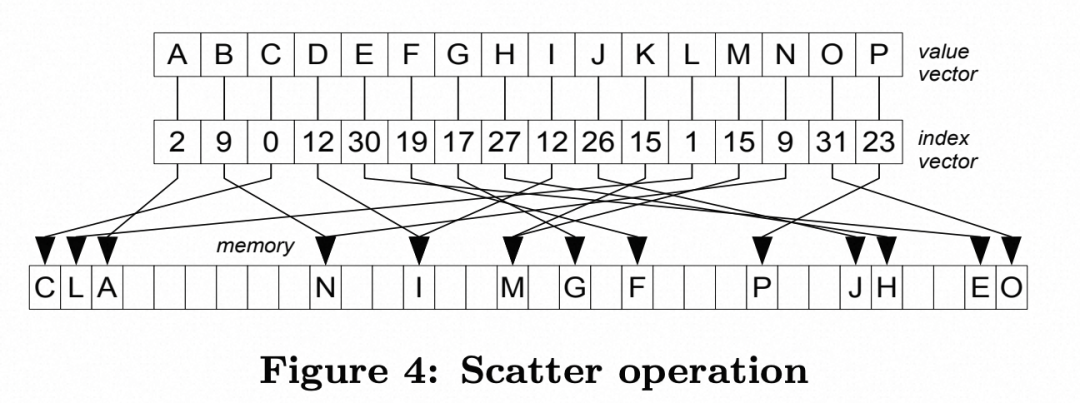
public void scatter(long[] source, long[] target, int[] scatterMap, int copySize) {for (int i = 0; i < copySize; i++) {target[scatterMap[i]] = source[i];}}
public void scatter(int[] source, int[] target, int[] scatterMap, int copySize) {int laneSize = SIMDHandles.INT_VECTOR_LANE_SIZE; //每次SIMD能处理的位数final int indexVectorLimit = copySize laneSize * laneSize;int index = 0;for (; index < indexVectorLimit; index += laneSize) {IntVector dataInVector = IntVector.fromArray(INTEGER_VECTOR_SPECIES, source, index); //从source[index]位置取出K个数字dataInVector.intoArray(target, 0, scatterMap, index);}if (index < copySize) {scalarPrimitives.scatter(source, target, scatterMap, index, copySize - index);}}
Vector API实现原理
LongVector va = LongVector.fromArray(SPECIES, longArr, i);LongVector vb = LongVector.fromArray(SPECIES, longArr2, i);LongVector vc = va.add(vb);
JDK层面
在JDK层面Java并没有做任何的优化,其底层实现就是对Vector中的每个元素调用了apply函数,而apply函数指向了一个绑定的函数,该函数的实现为标量加法。显然,这么做甚至会增加执行的开销,那Vector API的高性能从何谈起呢?
1. add函数的实现
@Override@ForceInlinepublic final LongVector add(Vector<Long> v) {return lanewise(ADD, v);}
2. 最终调用b0pTemplate函数进行计算
@ForceInlinefinalLongVector bOpTemplate(Vector<Long> o,FBinOp f) {long[] res = new long[length()];long[] vec1 = this.vec();long[] vec2 = ((LongVector)o).vec();for (int i = 0; i < res.length; i++) {res[i] = f.apply(i, vec1[i], vec2[i]);}return vectorFactory(res);}
3. apply绑定了标量执行的函数实现
LongVector lanewiseTemplate(VectorOperators.Binary op,Vector<Long> v) {LongVector that = (LongVector) v;that.check(this);....int opc = opCode(op);return VectorSupport.binaryOp(opc, getClass(), long.class, length(),this, that,BIN_IMPL.find(op, opc, (opc_) -> {switch (opc_) {case VECTOR_OP_ADD: return (v0, v1) ->v0.bOp(v1, (i, a, b) -> (long)(a + b));case VECTOR_OP_SUB: return (v0, v1) ->v0.bOp(v1, (i, a, b) -> (long)(a - b));case VECTOR_OP_MUL: return (v0, v1) ->v0.bOp(v1, (i, a, b) -> (long)(a * b));case VECTOR_OP_DIV: return (v0, v1) ->v0.bOp(v1, (i, a, b) -> (long)(a b));....}}));}
JVM层面
1. 前置知识:JIT与C2编译器
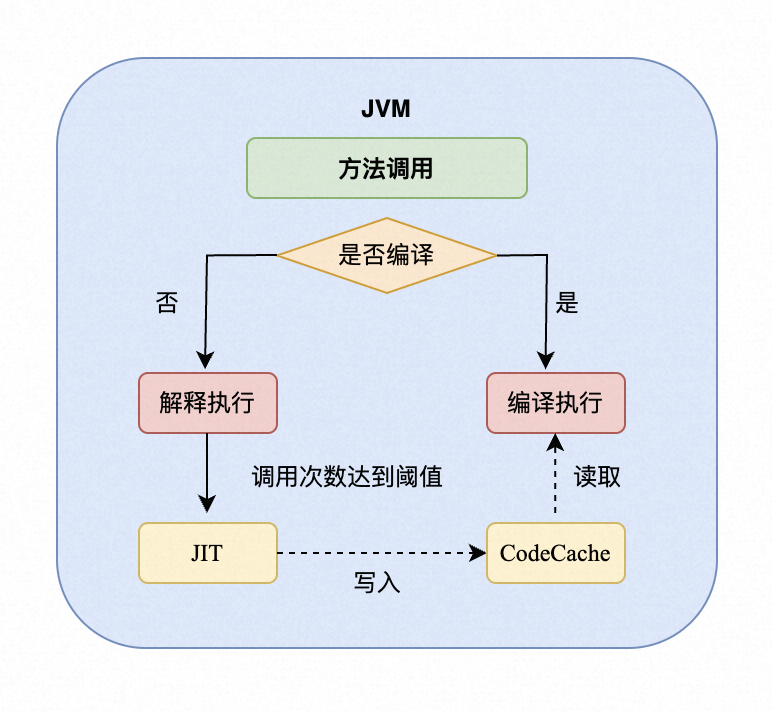
2. Vector API在JVM层面的实现

//---------------------------make_vm_intrinsic----------------------------CallGenerator* Compile::make_vm_intrinsic(ciMethod* m, bool is_virtual) {vmIntrinsicID id = m->intrinsic_id();C2Compiler* compiler = (C2Compiler*)CompileBroker::compiler(CompLevel_full_optimization);bool is_available = false;methodHandle mh(THREAD, m->get_Method());is_available = compiler != NULL && compiler->is_intrinsic_supported(mh, is_virtual) &&!C->directive()->is_intrinsic_disabled(mh) &&!vmIntrinsics::is_disabled_by_flags(mh);if (is_available) {return new LibraryIntrinsic(m, is_virtual,vmIntrinsics::predicates_needed(id),vmIntrinsics::does_virtual_dispatch(id),id);} else {return NULL;}}
void Assembler::addpd(XMMRegister dst, XMMRegister src) {NOT_LP64(assert(VM_Version::supports_sse2(), ""));InstructionAttr attributes(AVX_128bit, /* rex_w */ VM_Version::supports_evex(), /* legacy_mode */ false, /* no_mask_reg */ true, /* uses_vl */ true);attributes.set_rex_vex_w_reverted();int encode = simd_prefix_and_encode(dst, dst, src, VEX_SIMD_66, VEX_OPCODE_0F, &attributes);emit_int16(0x58, (0xC0 | encode));}
Long数组相加
0x00007f3eb13602ae: vpaddq 0x10(%r11,%rbx,8),%ymm3,%ymm3;
2. 标量执行
0x00007fa6fd33259a: vpaddq 0x10(%r8,%rbp,8),%ymm4,%ymm4
vpaddq:AVX512指令集。将(%r11 + %rbx * 8)开始的16个字节的数据和ymm3寄存器中的数据相加,写到ymm3寄存器中。
自动向量化(auto-vectorization)
1. 只支持自增的for循环
2. 只支持Int/Long类型(Short/Byte/Char 通过int间接支持)
使用SIMD实现大小写转化的思路比较简单,我们只需要调用compare方法进行比较,使用lanewise方法进行异或即可。这里引入了VectorMask,可以理解为一个boolean类型的寄存器,里面含有n个0/1。
@Benchmarkpublic void normal() {final long Mask = 'A' ^ 'a';for (int i = 0; i < charArr.length; i++) {if(charArr[i] >= 'A' && charArr[i] <= 'Z') {charArr[i] ^= Mask;}}}@Benchmarkpublic void vector() {final long Mask = 'A' ^ 'a';int i;int batchSize = charArr.length;int end = SPECIES.loopBound(charArr.length);for (i = 0; i < end; i += SPECIES.length()) {ByteVector from = ByteVector.fromArray(SPECIES, charArr, i);VectorMask mask = from.compare(VectorOperators.GE, 'A', from.compare(VectorOperators.LE, 'Z'));ByteVector to = from.lanewise(VectorOperators.XOR, Mask, mask); //这里传入了mask,表示只对mask=1的位置执行xorto.intoArray(charArr, i);}for(; i < batchSize; ++i) {if(charArr[i] >= 'A' && charArr[i] <= 'Z') {charArr[i] ^= Mask;}}}
Benchmark
测试环境:随机生成1000和10w个byte类型的字母来进行Benchmark
测试结果:在count=10w的场景下快了50x,原因在于ByteSpecies的长度为32,同时SIMD的执行方式没有分支预测失败flush流水线的开销。

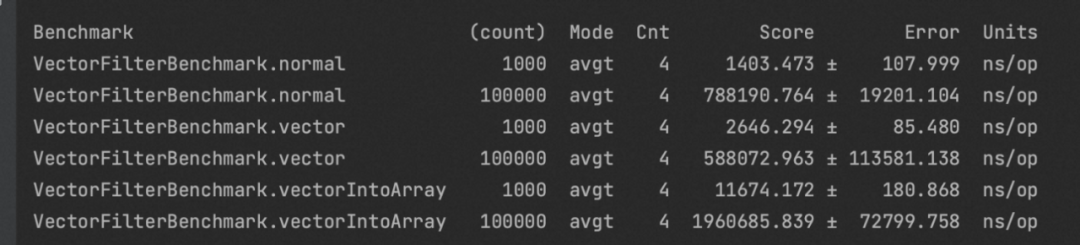
@Benchmarkpublic void normal() {newSize = 0;for (int i = 0; i < intArr.length; i++) {if(intArr[sel[i]] <= intArr2[sel[i]) {sel[newSize++] = i;}}}@Benchmarkpublic void vector() {newSize = 0;int i;int batchSize = intArr.length;int end = SPECIES.loopBound(intArr.length);for (i = 0; i < end; i += SPECIES.length()) {IntVector va = IntVector.fromArray(SPECIES, intArr, 0, sel, i);IntVector vb = IntVector.fromArray(SPECIES, intArr2, 0, sel, i);VectorMask<Integer> vc = va.compare(VectorOperators.LE, vb);if(!vc.anyTrue()) {continue;}int res = (int) vc.toLong();while(res != 0) {int last = res & -res; //找到二进制中最后一个1对应的幂次, 例如12 = 1100, 12 & (-12) = 4sel[newSize++] = i + Integer.numberOfTrailingZeros(last); //numberOfTrailingZeros(2^i) = ires ^= last;}}for(; i < batchSize; ++i) {int j = sel[i];if(intArr[j] <= intArr2[j]) {sel[newSize++] = i;}}}
Benchmark
什么是Local Exchange算子
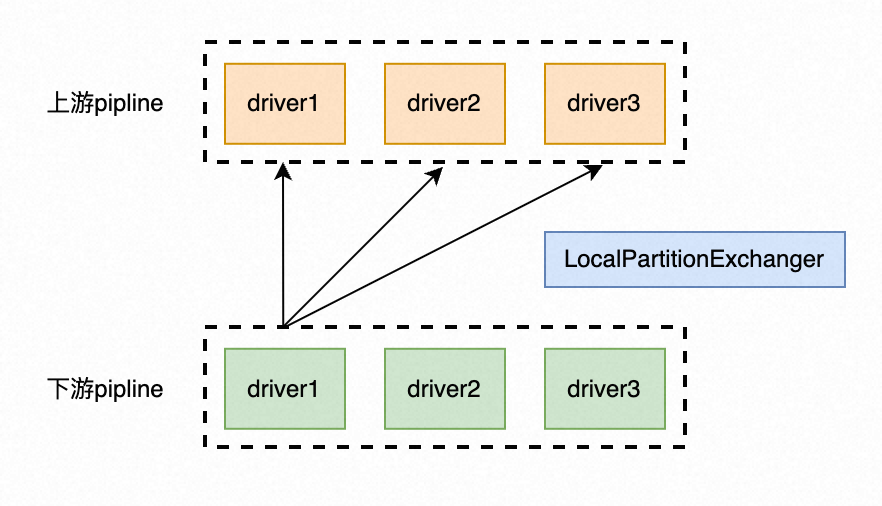
对于这一段表述不理解的话也没关系,本文的重点在于介绍使用SIMD指令优化代码逻辑的方式,因此可以放心继续阅读下文。
非向量化版本(PolarDB分布式版现有版本)
PolarDB分布式版现有版本沿用了行存执行模型下的Local Exchange算子,其基本思想是row by row的逐行枚举、逐行计算partition并写入对应的Chunk,这一执行模式的缺点在于其既不能有效的利用列式内存布局,同时appendTo操作会带来大量的时间开销。
1. 计算position(行号)对应的partition:使用了n个链表来保存每个partition对应的position list
a. (partitionGenerator.getPartition可以简单的理解为对position对应的数据进行hash运算得到目标partition的位置)
for (int position = 0; position < keyChunk.getPositionCount(); position++) {int partition = partitionGenerator.getPartition(keyChunk, position);partitionAssignments[partition].add(position);}
2. buildChunk:生成对应partition的Chunk
a. 先枚举partition
i. 枚举partition对应的position(position表示行)
1. 枚举该行对应的列block
a. 调用builder的appendTo来为ChunkBuilder添加元素
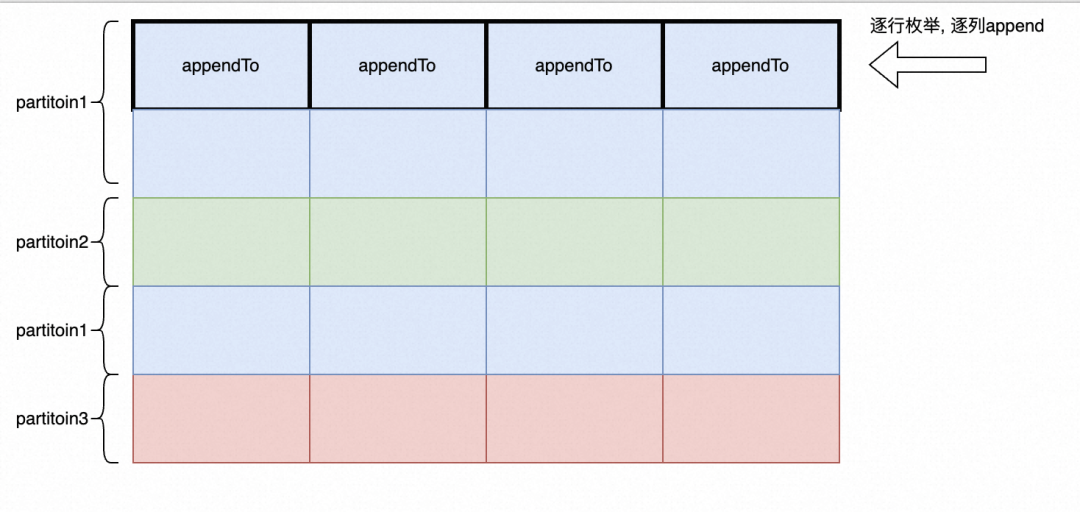
Map<Integer, Chunk> partitionChunks = new HashMap<>();for (int partition = 0; partition < executors.size(); partition++) { //枚举partitionList<Integer> positions = partitionAssignments[partition]; //获取到对应的positions = partitionAssignments[partition]ChunkBuilder builder = new ChunkBuilder(types, positions.size(), context);Chunk partitionedChunk;for (Integer pos : positions) { //枚举对应的position(行)for (int i = 0; i < chunk.getBlockCount(); i++) { //枚举对应的列builder.appendTo(chunk.getBlock(i), i, pos); //将pos行,i列位置的元素添加到对应的ChunkBuilder}}partitionedChunk = builder.build();partitionChunks.put(partition, partitionedChunk);}
Local Exchange SIMD优化
思路:
1. 对appendTo的优化: appendTo操作开销极大,尝试用更高效的方法拷贝数据, 例如system.arrayCopy
2. 对行式枚举模式的优化:逐行枚举的方式受限,因为每一列的数据在不同的Block内,不可能攒批copy。同时逐行枚举的方式对访存不友好。那么考虑先枚举列。
● 解决方案:如下图所示,我们希望求出positionMapping数组使得相同partition的行能够被迁移到连续的行中,这样以来就可以使用Scatter运算进行加速。
afterValue[positionMapping[i]] = preValue[i]
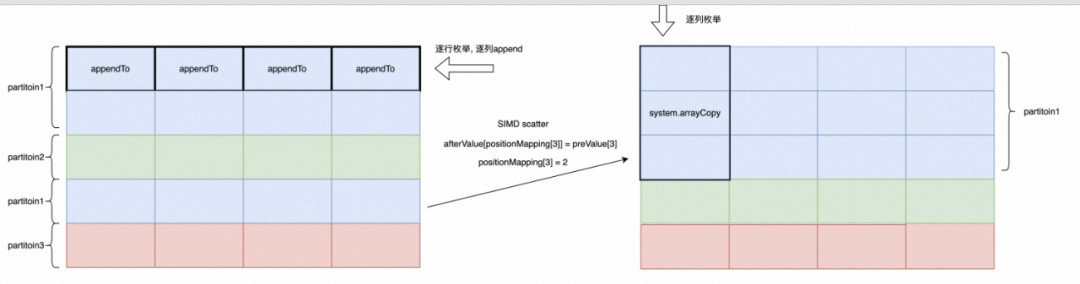
3. 问题:如何知道positionMapping?
● 已知offset就可以边遍历边求出positionMapping:只需要记录出该行对应的partition的offset,然后让offset自增即可。这一过程看代码会更直观。
private void scatterAssignmentNoneBucketPageInBatch(Chunk keyChunk, int positionStart, int batchSize) {int[] partitions = scatterMemoryContext.getPartitionsBuffer();for (int i = 0; i < batchSize; i++) {int partition = partitionGenerator.getPartition(keyChunk, i + positionStart);partitions[i] = partition;++paritionSize[partition]; //统计每个partition的size}}
private void prepareDestScatterMapStartOffset() {int startOffset = 0;for (int i = 0; i < partitionNum; i++) {partitionOffset[i] = startOffset; //统计每个partition对应的偏移量startOffset += partitionSize[i];}}
protected void prepareLengthsPerPartitionInBatch(int batchSize, int[] partitions, int[] destScatterMap) {for (int i = 0; i < batchSize; ++i) {positionMapping[i] = partitionOffset[partitions[i]]++; //获取每个位置scatter之后对应的内存地址}}
protected void scatterCopyNoneBucketPageInBatch(Chunk keyChunk, int positionStart, int batchSize) {Block[] sourceBlocks = keyChunk.getBlocksDirectly(); //获取到所有的blockfor (int col = 0; col < types.size(); col++) { //枚举所有列Block sourceBlock = sourceBlocks[col]; //获取到blockfor (int i = 0; i < chunkBuilders.length; i++) {blockBuilders[i] = chunkBuilders[i].getBlockBuilder(col); //获取到所有partition的pageBuilder}vectorizedSIMDScatterAppendTo(sourceBlock, scatterMemoryContext, blockBuilders);}}
public void copyPositions_scatter_simd(ScatterMemoryContext scatterMemoryContext, BlockBuilder[] blockBuilders) {//存放目的数据的bufferint[] afterValue = scatterMemoryContext.getafterValue();//存放原始数据的bufferint[] preValue = scatterMemoryContext.getpreValue();//positionMappingint[] positionMapping = scatterMemoryContext.getpositionMapping();//每个partition的sizeint[] partitionSize = scatterMemoryContext.getpartitionSize();//使用scatter的操作VectorizedPrimitives.SIMD_PRIMITIVES_HANDLER.scatter(preValue, afterValue, positionMapping, 0, batchSize);int start = 0;for (int partition = 0; partition < blockBuilders.length; partition++) {IntegerBlockBuilder unsafeBlockBuilder = (IntegerBlockBuilder) blockBuilders[partition];//注意这里writeBatchInts的实现unsafeBlockBuilder.writeBatchInts(afterValue, bufferNullsBuffer, start, partitionSize[partition]);start += partitionSize[partition];}}
3. 使用writeBatchInts来实现内存拷贝
public IntegerBlockBuilder writeBatchInts(int[] ints, boolean[] nulls, int sourceIndex, int count) {values.addElements(getPositionCount(), ints, sourceIndex, count);valueIsNull.addElements(getPositionCount(), nulls, sourceIndex, count);return this;}
addElements的底层使用了System.arraycopy命令来批量的进行内存复制 System.arraycopy是JVM的内置函数,其实现效率远远快于调用append接口来逐个添加数据。
@IntrinsicCandidatepublic static native void arraycopy(Object src, int srcPos,Object dest, int destPos,int length);
Benchmark
测试环境:我们设置parition的数量为3,并向Local Exchange算子输入100个大小为1024,包含4列int的Chunk来进行Benchmark

我们发现单纯的向量化算法并不会有性能提升,原因在于Local Exchange算子的瓶颈在于appendTo操作。而SIMD Scatter + System.arrayCopy的方式实现了35%的性能提升。
SIMD思路
在CMU 15-721中提到了SIMD Hash Probe的实现,我们将用Vector API来复现这一过程。
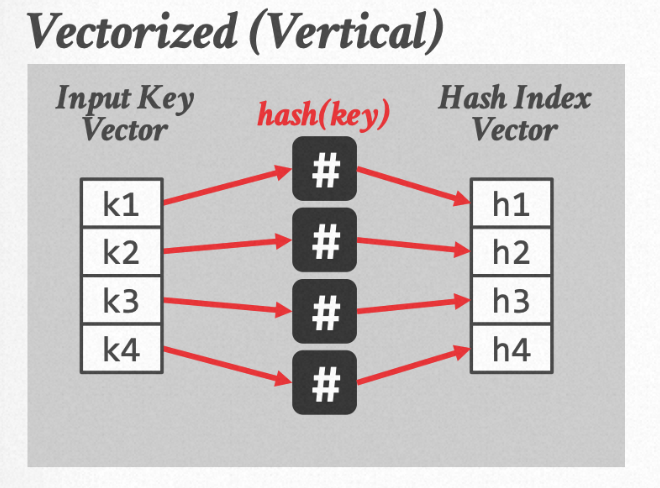
首先来回顾开放地址法的SIMD Hash Probe过程,其基本思路是一次性对4个位置的元素进行probe。
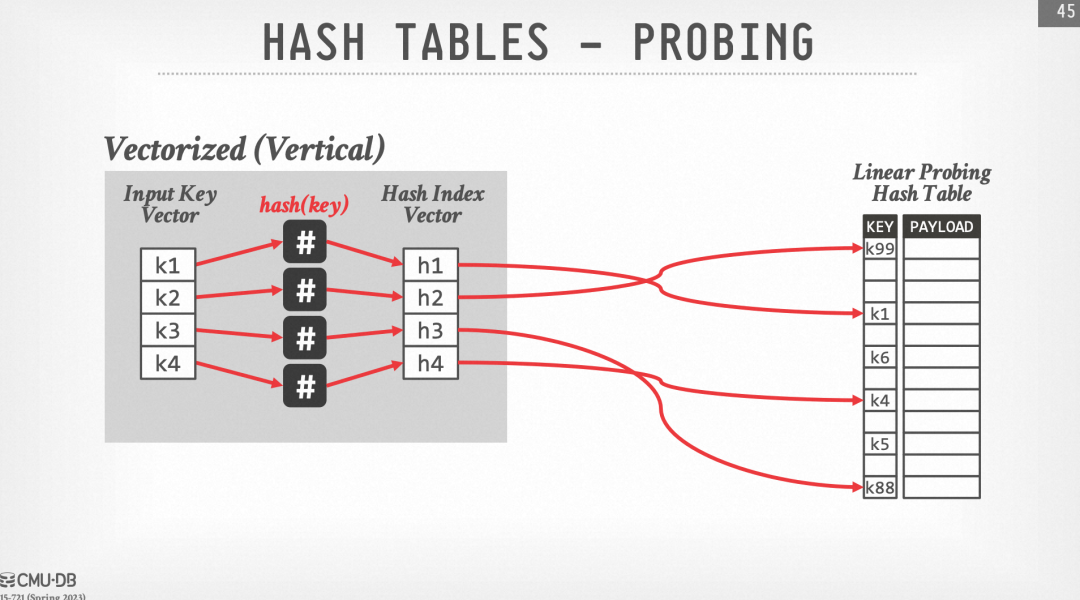
2. 通过Gather运算读取到hash表中对应位置的元素
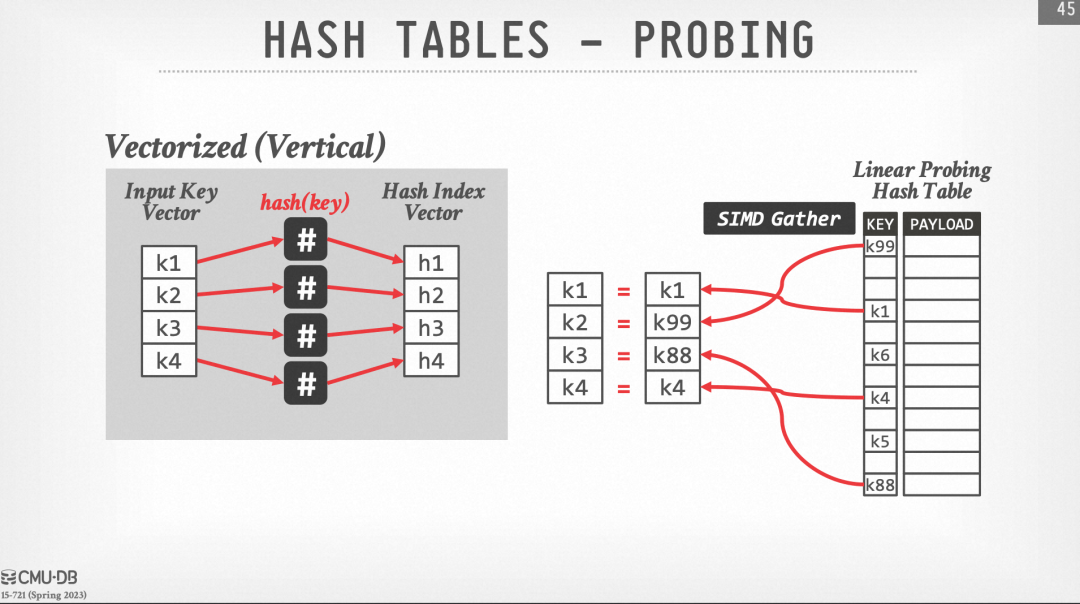
3. 通过SIMD的compare运算比较有无hash冲突
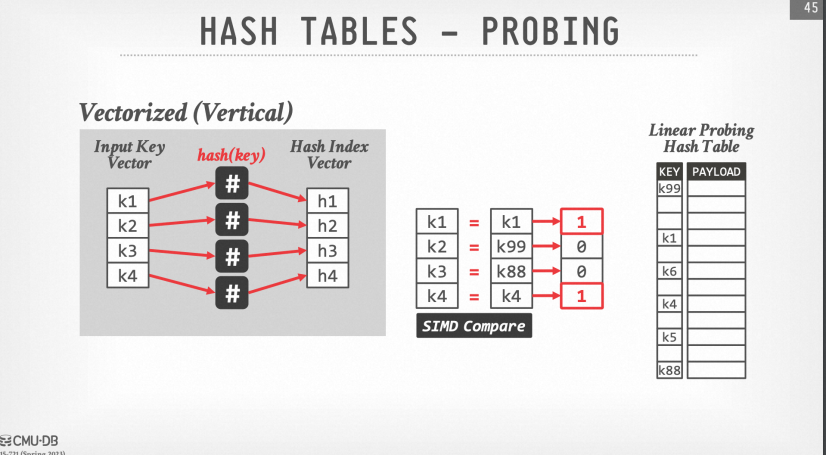
4. 前3步都比较好理解,接下来我们需要让有hash冲突的元素寻址到下一个位置继续解hash冲突,这一步可以由SIMD加法来实现。重点在于如何让没有冲突的元素移走,把数组中后面的元素放进来继续匹配呢?(例如我们希望把下图中的k1, k4分别替换为k5, k6)
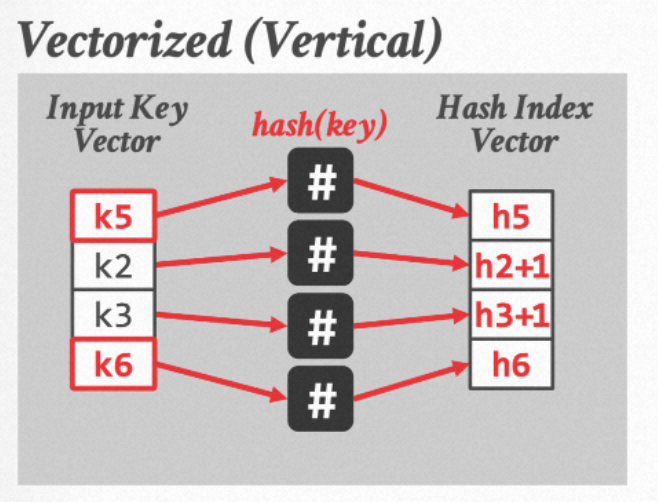
a. 使用expand运算来进行selective load运算
buildPositionVec = buildPositionVec.expand(probePosition, probeOffset, probeMask);
b. expand运算可以将probeMask当中为1的n个位置元素替换为hashPosition数组从probeOffset位置开始的n个元素。
小插曲: 如何实现更强大的expand


这得益于阿里云强大的自研能力,我们与阿里云JVM团队进行了积极的沟通,JVM团队的同学帮助我们实现了更丰富的expand的运算。
验证
PolarDB分布式版的Hash方式并不是开放寻址法,而是布谷鸟Hash,但其SIMD的原理类似,这里给出对布谷鸟Hash的SIMD Hash Probe改造过程。
@Benchmarkpublic void normal() {for(int i = 0; i < count; i++) {int joinedPosition = 0;int matchedPosition = (int) hashTable.keys[hashedProbeKey[i]];while (matchedPosition != LIST_END) {if (buildKey[matchedPosition] == probeKey[i]) {joinedPosition = matchedPosition;break;}matchedPosition = (int) positionLinks[matchedPosition];}joinedPositions[i] = joinedPosition;}}@Benchmarkpublic void vector() {int probeOffset = 0;VectorMask<Long> probeMask;VectorMask<Integer> intProbeMask;LongVector probeValueVec = LongVector.fromArray(LongVector.SPECIES_512, probeKey, probeOffset);// step 1: 使用Gather运算从hashTable的keys中读取数据. int matchedPosition = hashTable.keys[hashedProbeKey[i]];LongVector buildPositionVec = LongVector.fromArray(LongVector.SPECIES_512, hashTable.keys, 0, hashedProbeKey, probeOffset);IntVector probeIndexVec = IntVector.fromArray(IntVector.SPECIES_256, index, probeOffset);probeOffset += 8;while(probeOffset + LongVector.SPECIES_512.length() < count){// step 2: 计算buildPositionVec中为0的位置单独处理VectorMask<Long> emptyMask = buildPositionVec.compare(VectorOperators.EQ, 0);// step 3: 使用Gather运算计算出buildKey[matchedPosition[i]]的值IntVector intbuildPositionVec = buildPositionVec.castShape(IntVector.SPECIES_256, 0).reinterpretAsInts();LongVector buildValueVec = LongVector.fromArray(LongVector.SPECIES_512, intbuildPositionVec, buildKey);// step 4: 使用SIMD compare来进行比较. if (buildKey[matchedPosition] == probeKey[i])VectorMask<Long> valueEQMask = probeValueVec.compare(VectorOperators.EQ, buildValueVec, emptyMask.not());// step 5: 计算出probe过程成功找到目标位置的MaskprobeMask = valueEQMask.or(emptyMask);intProbeMask = probeMask.cast(IntVector.SPECIES_256);// step 6: 使用scatter运算将匹配的position写入joinedPosition. joinedPositions[i] = matchedPosition;buildPositionVec.intoArray(joinedPositions, probeIndexVec, valueEQMask);// step 7: 处理hash冲突. matchedPosition = positionLinks[matchedPosition];buildPositionVec = LongVector.fromArray(LongVector.SPECIES_512, intbuildPositionVec, positionLinks);// step 8: 使用expand运算获取到下一个probe vectorbuildPositionVec = buildPositionVec.expand(probePosition, probeOffset, probeMask);probeValueVec = probeValueVec.expand(probeKey, probeOffset, probeMask);probeIndexVec = probeIndexVec.expand(index, probeOffset, intProbeMask);// step 9: 更新probeOffsetprobeOffset += probeMask.trueCount();}scalarProcessVector(probeValueVec, buildPositionVec, probeIndexVec, joinedPositions); //处理最后一个Vectorif (probeOffset < count) {processBatchX(hashedProbeKey, probeOffset, count, joinedPositions);}}
Benchmark
测试环境:在Build端我们向Hash表中插入了100w个大小在0-1000范围的元素来模拟Hash冲突,Probe时计算探测100w个元素所需要的时间。
测试结果:虽然我们实现了SIMD Hash Probe,但由于现有的Vector API对类型的支持并不充分(代码中含有大量的类型转化),因此实测结果并不优秀,甚至有2倍多的性能下降。

参考文章:
[1] PolarDB-X 向量化执行引擎:https://zhuanlan.zhihu.com/p/337574939
[2] PolarDB-X 向量化引擎:https://zhuanlan.zhihu.com/p/339514444
[3] PolarDB-X 并行计算框架:https://zhuanlan.zhihu.com/p/346320114
PolarDB分布式版 大降价 🎉



 点击 阅读原文 了解 PolarDB分布式版降价详情
点击 阅读原文 了解 PolarDB分布式版降价详情
