




应用层,以及它所处的位置
数据层,以及它在数据库和应用层之间的位置
索引策略,以及它如何与内存和CPU使用相关联
存储层设计
在所有这些方面与可扩展性和成本考虑相关的问题
1.本地部署 vs. 云托管
云原生(托管)+ 客户端-服务器模式
本地部署(自托管)+ 嵌入式
云原生(托管)+ 嵌入式
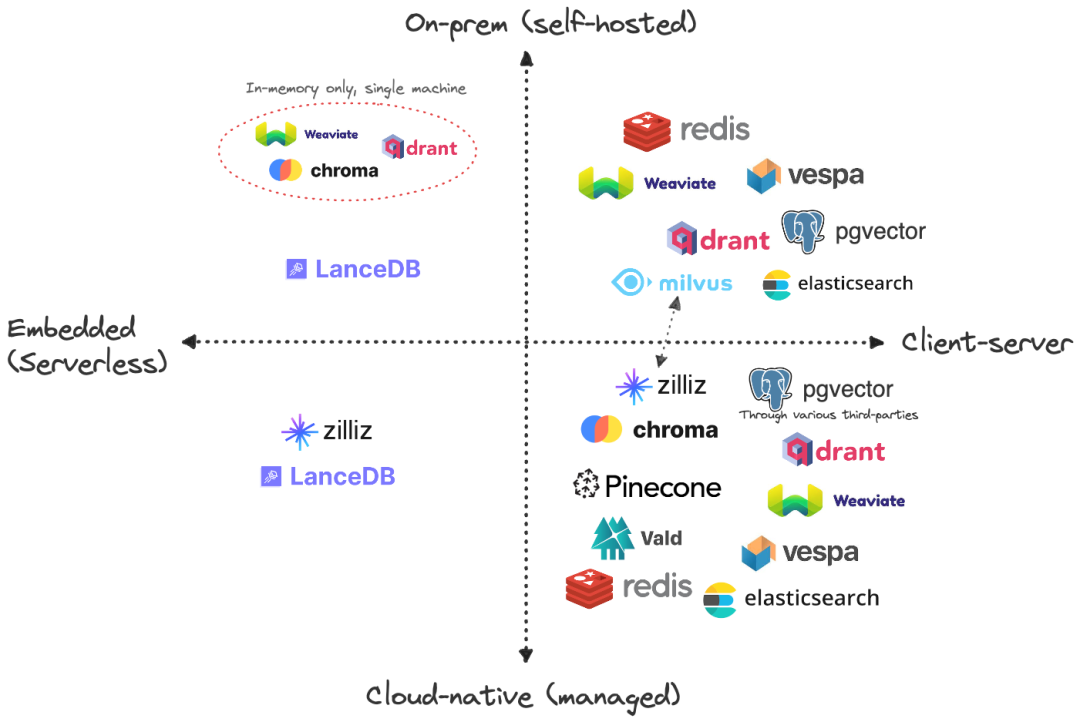
客户端-服务器架构 vs. 嵌入式架构
成本考虑
我的数据集增长得足够快,需要在云上按需弹性扩展吗?
我是否有足够大的数据基础设施团队来支持本地或嵌入式托管?
我的数据集是否足够敏感,需要将其保留在本地?
对于完全托管的云托管解决方案,按查询和存储的数据量付费可能会有哪些成本考虑?
2. 专业供应商 vs. 传统供应商
我是否已经拥有现有的数据库可以用于向量搜索?
我是否可以在自己的数据上运行简单的基准测试,以比较传统解决方案和专为向量搜索构建的解决方案的性能?
这个解决方案是否能够随着数据的增长而扩展?
3. 插入速度 vs. 查询速度
我将多频繁地插入(和索引)大量向量?
在查询时,我是否满足应用程序的延迟要求?
4. 召回率 vs. 延迟
一种索引是以原始形式存储向量,并用于精确的k最近邻搜索。它是最准确的,但也是最慢的。
IVF-Flat索引使用倒排文件索引来快速缩小搜索空间,比暴力搜索要快得多,但在召回率方面会牺牲一些准确性。
IVF-PQ将IVF与Product Quantization结合使用,对向量进行压缩,减少内存占用并加快搜索速度,同时在召回率方面比纯索引更好。
HNSW是目前最流行的索引方法,可以与Product Quantization结合使用,以提高召回率,同时相对于HNSW-PQIVF-PQ在内存效率上有所改进。
Vamana是一个相对较新的索引方法,专为磁盘性能进行了设计和优化-它承诺可以存储大于内存的向量数据,并且在性能上与HNSW相当快。

对于我的使用案例,搜索召回率有多重要?通常,通过对自己的数据和查询进行基准测试研究,可以帮助回答这个问题。
在我的使用案例中,延迟有多重要?如果数据集非常大,那么使用产品量化索引(如IVF-PQ或HNSW-PQ)来减少内存占用可能是有意义的。
5. 内存中 vs. 磁盘上的索引和向量存储
如果我的数据集非常大,如何减少内存消耗?在这种情况下,减少存储的向量的维度、调整图连接的最大数量(如果使用HNSW),或者添加产品量化(如果您的数据库支持)都可以帮助减少内存消耗。
我的数据库是否有将向量存储在磁盘上的选项,如果有,它会如何影响查询速度?像往常一样,需要在自己的数据和使用案例上进行测试!
6. 稀疏向量存储 vs. 密集向量存储
在我的使用案例中,语义搜索有多重要?如果非常重要,那么密集向量绝对是首选。
延迟和索引速度有多重要?如果这些是非常重要的约束条件,那么可能值得考虑稀疏向量(尽管从语义搜索的角度来看,它们永远无法与密集向量表现得一样好)。
7. 全文搜索 vs. 向量搜索混合策略
简单回退方法:这种方法使用“回退”策略,首先使用实现了BM25的解决方案(如Meilisearch或Elasticsearch)进行关键词搜索,然后将高延迟的向量搜索与关键词搜索结果进行线性组合。这是最简单的方法,但在相关性方面并不总是产生最佳结果。
倒数秩融合(RRF):这种方法将稀疏向量和密集向量获得的倒数秩相加,提供一个融合的排序分数。Elasticsearch和Weaviate11等数据库提供了使用多种RRF方法的混合搜索。
交叉编码器重新排序:这是用于混合分数重新排序的最先进的方法。它使用具有交叉编码损失函数的神经双编码器来融合稀疏/密集排序分数,通常产生最佳结果,但由于通过更昂贵的方法进行重新排序,会导致更高的延迟。这些解决方案通常不直接在向量数据库中提供,需要在向量数据库的下游构建自定义搜索引擎来执行重新排序。Nils Reimers是该库的创建者,现在在Cohere.ai工作,他在下面链接的Weaviate播客中详细描述了这些解决方案。
我选择的数据库是否实现了可靠的混合搜索策略?还是我需要在向量数据库的下游手动构建一个解决方案?
重新排序策略对搜索延迟有何影响?
通过提高准确性(例如通过交叉编码器重新排序)来改进搜索结果时,我能够接受增加多少延迟?
8. 过滤策略
我选择的数据库如何处理预过滤和后过滤?
对于我将执行的查询类别,预过滤和后过滤策略在我的数据上的效果如何?请注意,以上内容是基于虚构的情景和名称,仅用于说明目的。
结论
