




点击蓝字 关注我们


背景介绍
大数据时代,政务在享受大数据带来的管理便利的同时,也面临着数据质量、数据管理、数据共享等问题的挑战。为了提高政府决策的科学性和精准性,提高政府工作效率,优化政府服务,促进政府数字化转型,政务数据交换平台成为政务数据相互流通必不可缺的“桥梁”。
政务数据共享交换平台是指政府部门之间共享数据的平台,通过这个平台可以实现政府部门之间的数据共享、交换和整合,实现政府数据跨层级、跨地域、跨部门、跨系统、跨业务的信息资源共享交换。
由于政务数据共享平台需要实现多个数据源的集成,包括不同部门、不同数据库、不同格式等,其建设和维护都离不开数据集成技术支持。
数字广东在实现数字化转型上一直走在前列,不断在数据共享交换业务场景上进行探索,并将数据集成支持从 DataX 替换为 Apache SeaTunnel。
政务行业在数据交换的业务场景上面临哪些挑战?如何利用 Apache SeaTunnel 数据集成技术支持实现数据价值的最大化?数字广东通过其数据集成技术演进之路,来回答了这些问题。
业务挑战

1
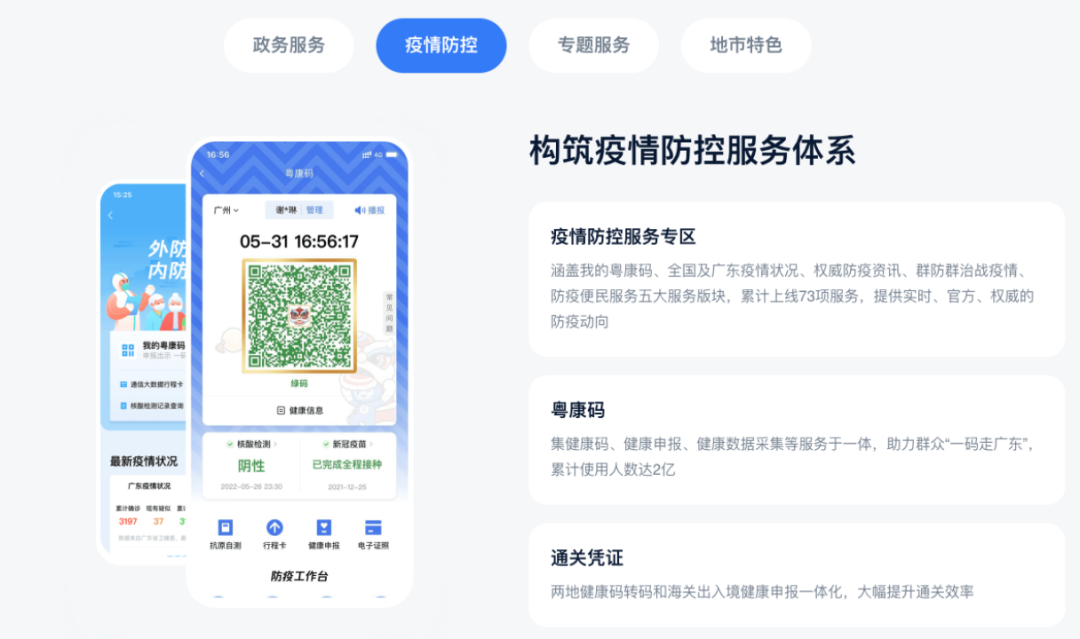
政务服务场景
2
疫情防控场景
数据同步痛点
1
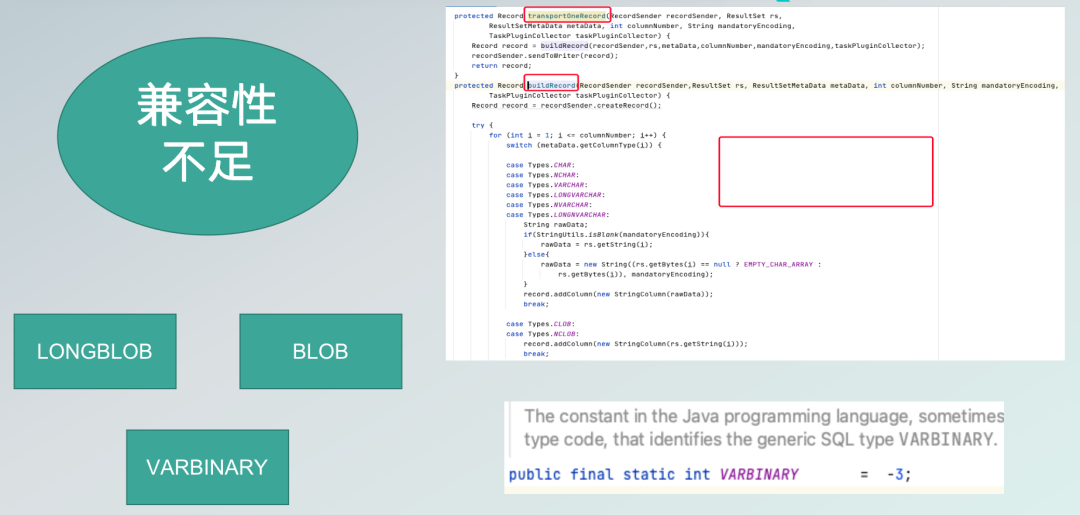
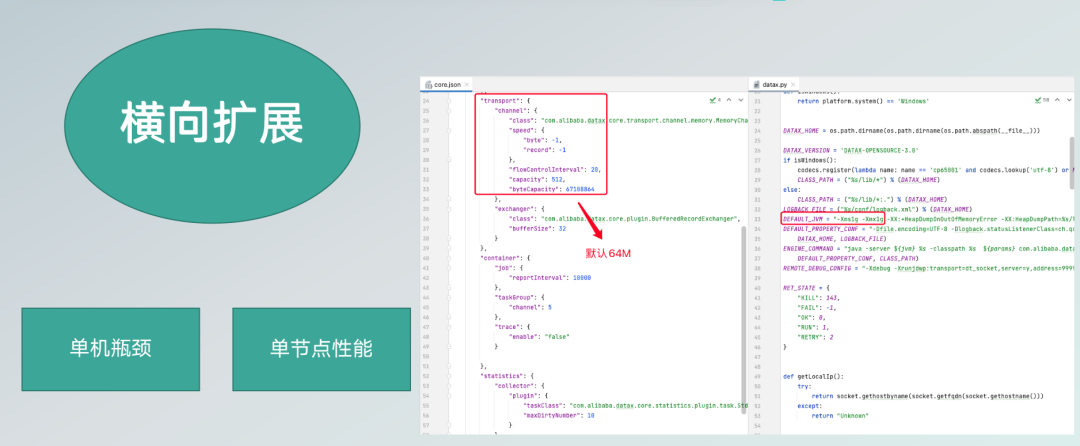
离线数据同步的痛点
整体解决方案
2
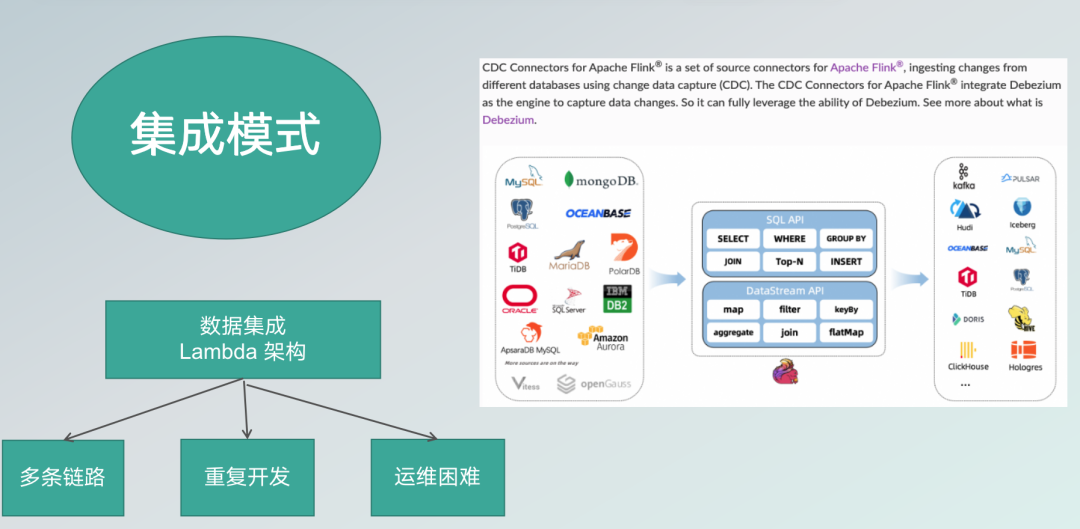
实时数据同步痛点

数据集成平台选型与演进之路

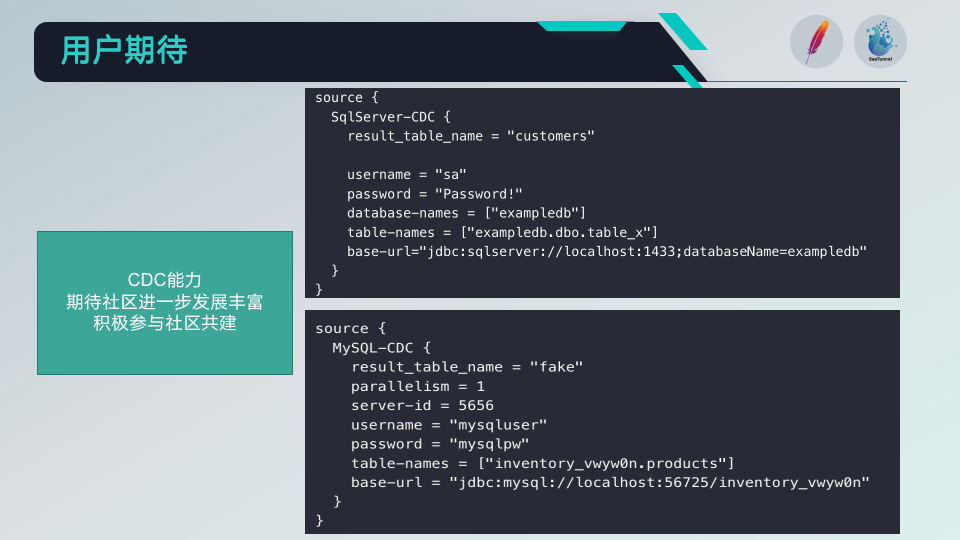
用户期望
作者介绍

孟小鹏 数字广东 技术经理
数字广东技术委员会专业委员
Apache SeaTunnel&DataX Contributor
华北电力大学计算机系研究生
Apache SeaTunnel
精彩推荐
一键三连-点赞在看转发⭐️!

文章转载自SeaTunnel,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
