





文末有抽奖福利,要看到最后哦!
一、Apache Flink和数据湖介绍
1.1 Apache Flink CDC原理
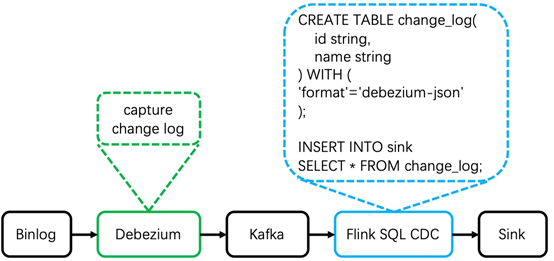
{"before": { --更新之前的数据"id": 001,"name": "tom"},"after": { --更新之后的数据"id": 001,"name": "jerry"},"source": {...},"op": "u","ts_ms": 1589362330904}
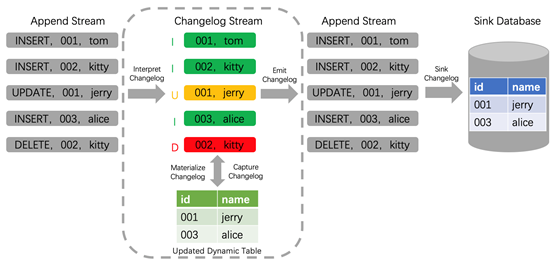
通过以上分析,基于Flink SQL CDC的数据同步有如下优点:
a)业务解藕:无需入侵业务,和业务完全解藕,也就是业务端无感知数据同步的存在。
b)性能消耗:业务数据库性能消耗小,数据同步延迟低。
c)同步易用:使用SQL方式执行CDC同步任务,极大的降低使用维护门槛。
d)数据完整:完整的数据库变更记录,不会丢失任何记录,Flink 自身支持 Exactly Once。
1.2 数据湖介绍
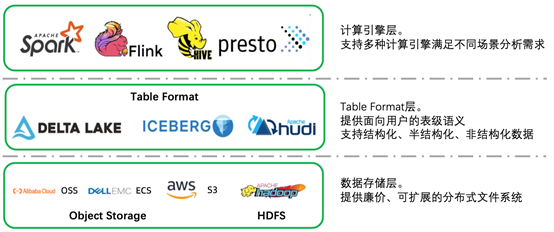
不支持ACID
不支持Upsert场景,不支持Row-level delete,数据修改成本高
时效性差
数据难以做到准实时可见,无法支持分钟级延迟的数据分析场景
只能存储结构化数据
传统数仓不支持存储非结构化和半结构化数据
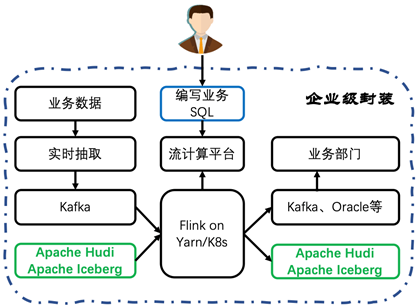
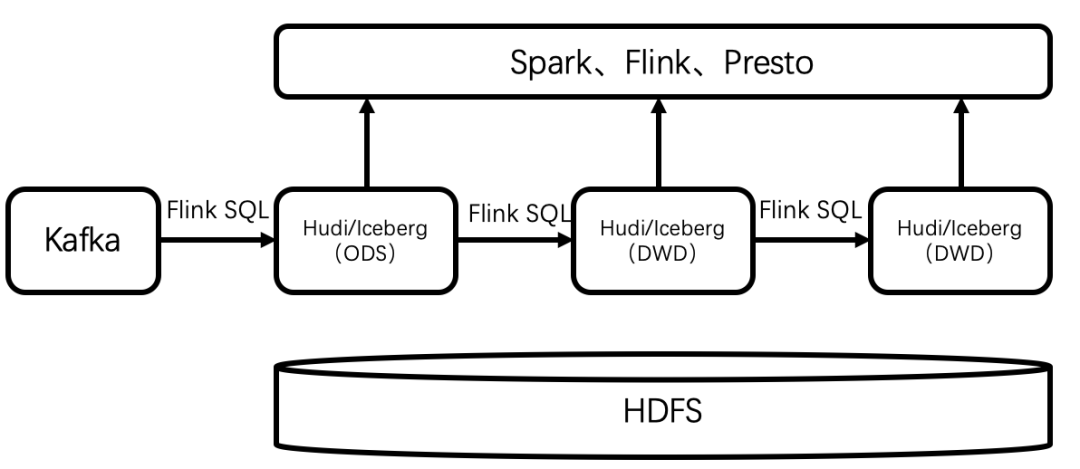
二、实时数据入湖实践
CREATE TABLE KafkaTable (id STRING,name STRING) WITH ('connector' = 'kafka','xxx' = 'xxx');
CREATE TABLE IcebergTable (id STRING,name STRING)WITH ('connector'='iceberg','xxx' = 'xxx');
INSERT INTO IcebergTableSELECT * FROM KafkaTable;
----/ *a.离线方式* /----SET execution.type=batch;SELECT COUNT(*) FROM IcebergTable;----/ *b.实时方式* /----SET execution.type=streaming;SELECT COUNT(*) FROM IcebergTable;
资源配置情况
| TaskManager | 内存4G,slot:1 |
| Checkpoint | 1分钟 |
| 测试数据列数 | 10列 |
| 测试数据行数 | 1000万 |
| iceberg存储格式 | parquet |
测试数据情况
数据入湖分为append和upsert两种方式。append方式只能新增数据,不能对结果数据进行更新操作;upsert方式即能够对结果数据更新。
| SQL | INSERT INTO IcebergTable /*+OPTIONS('equality-field-columns'='id')*/SELECT * FROM KafkaTable; | |
| 导入的数据 | 只有数据插入 | 只有数据更新 |
| 并行度1 | 3.2万/秒 | 2.9万/秒 |
| 并行度2 | 4.9万/秒 | 4.2万/秒 |
| 并行度4 | 6.1万/秒 | 5.1万/秒 |
结论
三、实时数据入湖经验
3.1 实时性

当程序BUG或者任务重启等导致数据传输中断,如何保证数据的一致性呢?
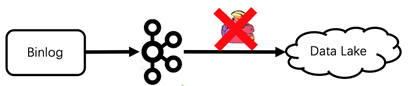
a)借助Flink实现的exactly once语义和故障恢复能力,实现数据严格一致性。在运行过程中,checkpoint周期内任务异常重启时,会从上一个checkpoint点恢复,重新消费数据写入下游的数据湖。
b)借助Hudi/Iceberg ACID能力来隔离写入对分析任务的不利影响。在checkpoint周期内写入的数据,下游数据湖对这部分未commit的数据是不可见的,从而隔离这部分未提交数据对分析任务的影响,周期性的commit也是数据湖分钟级延迟的主要原因。
3.3 顺序性
数据入湖否可保证全局顺序性插入和更新?

3.4 初始化
四、未来规划
END


本文作者:杜威科
扫二维码,立即关注
精彩内容,只为等你
