点击上方蓝字关注我们
 编者荐语:MPP (Massively Parallel Processing),即大规模并行处理,其将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果。然而,在实际的生产应用中MPP架构会受制于基础硬件性能,存在一定的短板效应。本文作者针对此短板效应的优化处理进行了初步的探索,并取得良好的效果,让我们一起跟着作者,开启接下来的探索之路吧!
编者荐语:MPP (Massively Parallel Processing),即大规模并行处理,其将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果。然而,在实际的生产应用中MPP架构会受制于基础硬件性能,存在一定的短板效应。本文作者针对此短板效应的优化处理进行了初步的探索,并取得良好的效果,让我们一起跟着作者,开启接下来的探索之路吧!

一、 现状
二、问题
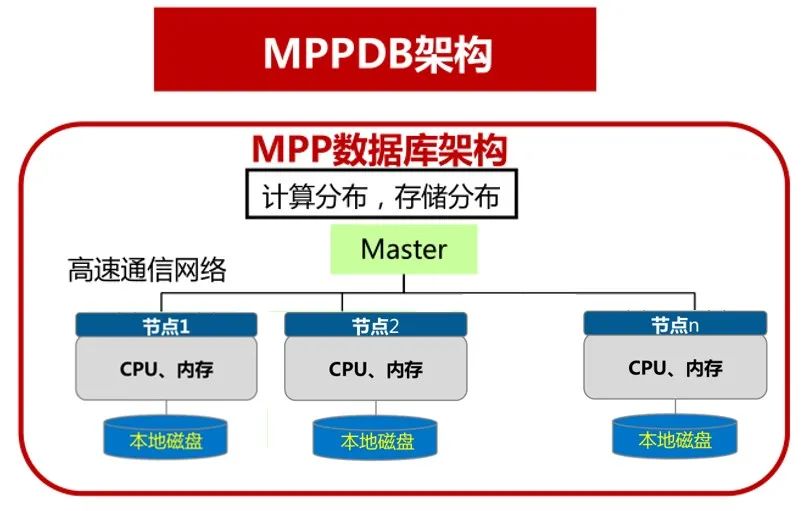
三、采取的方法及迭代
面对慢盘的初始阶段,无疑是艰难的,我们甚至不知道敌人是谁。
l 根源初探
为改变被动的局面,我们进行了新的尝试,根据长期的任务跟踪,开发了慢盘智能预警模块, 通过特征提取,预警指标加入集群运行状态、批量任务执行时间、单个任务执行状态等。模块上线后,验证发现在应用效果中,单纯依靠任务指标,监测过程存在两种情况,一种是滞后性,一种是超期置前性。滞后性,即当慢盘产生时,基本能够准确定位到慢盘位置,但是预警性不足,我们需要的是在慢盘影响业务前提前将其下线或更换;而超期置前性,即我们通过历史预警结果发现,几天前、甚至是数周前预警到的部分硬盘,在几天后、数周后发生了慢盘故障,然而这种超预期的提前发现,不仅提前量较大,且存在随机性和误判,同样无法满足预防性更换。
基于上述情况,我们尝试直接从硬盘IO指标进行分析,并上线IO监控,开始积累IO数据。通过分析积累到的IO指标和慢盘样本点,我们设置了重点IO指标预警,涉及参数包括svctm、await、r/s、w/s等,从应用效果及统计发现, IO指标预警虽然准确率较高,但同样存在滞后性。即短时间内的突变异常即使容易发现,但此时业务已经实际受到影响,所以单纯依靠IO指标仍然较难实现提前预警。
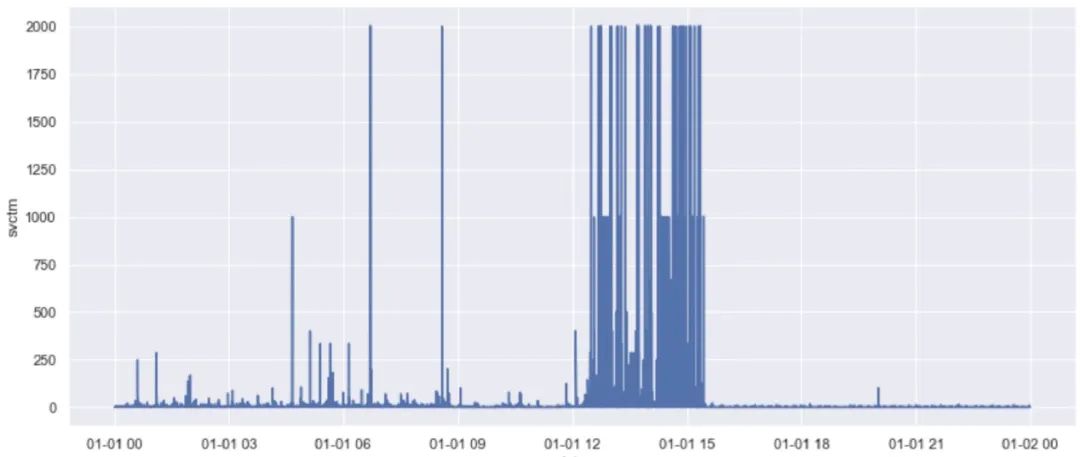
例如上图所示为实际慢盘样本点的svctm指标变化(svctm指io平均服务时间,一般值越高硬盘状态越差),当日约13点发现任务堵塞,而svctm指标在12点-15点间值明显异常波动,虽然短时特征较为明显,但前期特征不足。因此难以实现较大时间提前量的预防性更换。
因此,考虑利用应用侧指标预警的超期置前性以及硬件侧指标预警的准确性,我们将两者结合,利用统计学相关原理,综合判定实现硬件故障智能纠错预警,为了在实现预警的基础上提升命中准确率,硬件日志成了重要的方向,通过同硬件厂商对接,我们确定了日志中的重要参数口径,根据前期慢盘带来影响的特性,以及反复结合应用侧指标预警情况,我们确定了日志监测逻辑,结合日志指标,将问题硬盘打上标记。
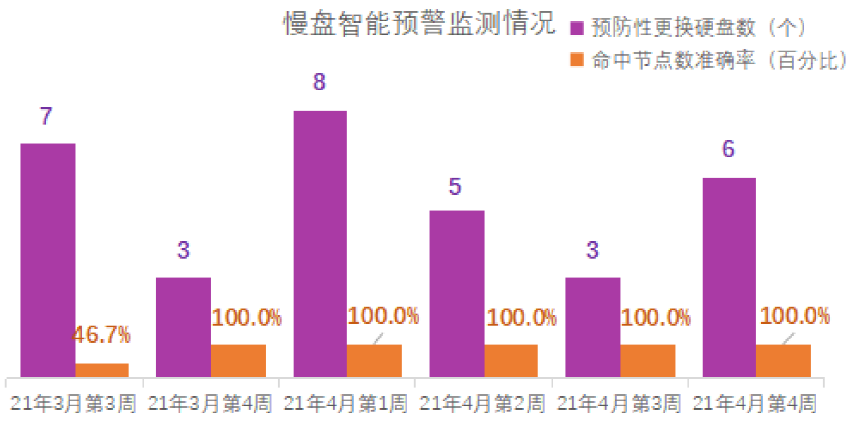
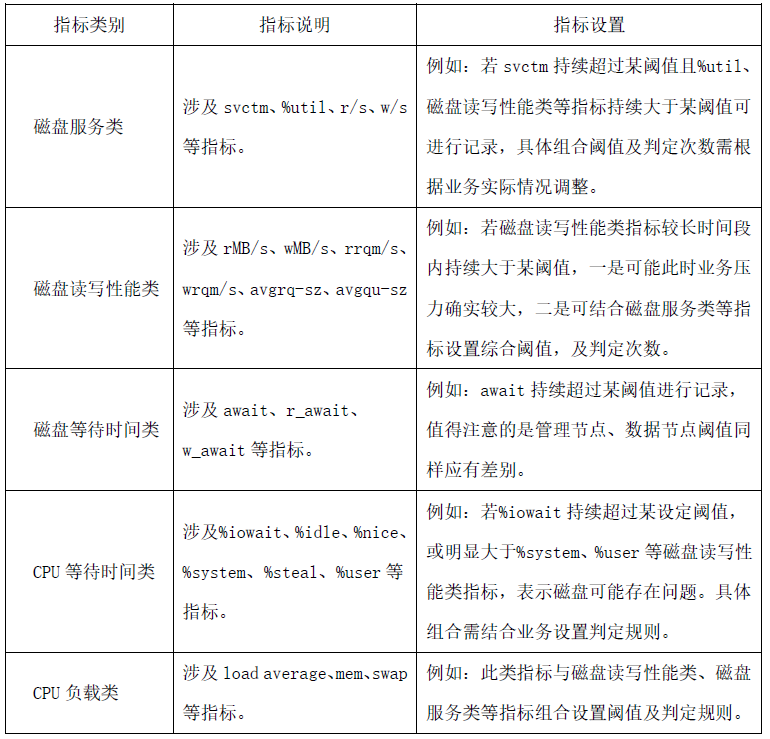
通过调整,根据预警结果将疑似问题硬盘打上标记,我们基本改变了被动局面,具备了预防性更换的能力。下表给出部分硬件侧指标参考。
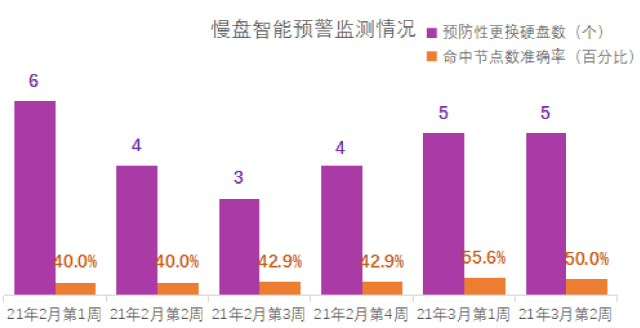
四、成果