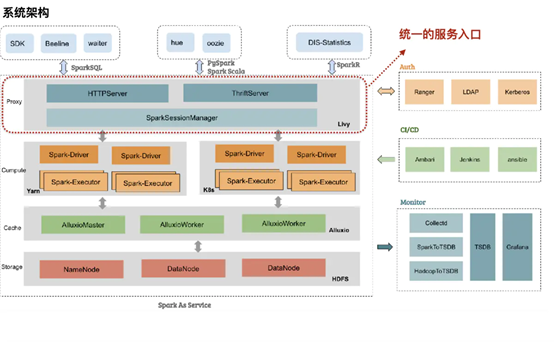
阅读本文,需先了解的术语

Kubernetes:简称K8s,是一个可移植的、可扩展的开源平台,用于管理容器化的工作负载和服务,可促进声明式配置和自动化
Yarn:hadoop 2.0 引入的集群资源管理系统。用户可以将各种服务框架部署在YARN上,由YARN进行统一地管理和资源分配
Spark:基于内存计算的通用大规模数据处理框架
RDD:弹性分布式数据集,Spark的核心模块,旨在封装了基础的数据操作(如map,filter,reduce等)的可共享的数据抽象
Livy:通过REST的方式将代码片段或是序列化的二进制代码提交到Spark集群中去执行
什么是Spark
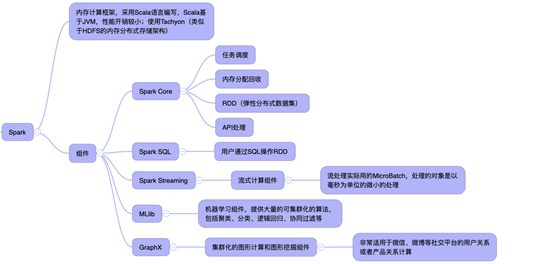
Spark使用场景
1.Spark是基于内存的迭代计算框架,适用于需要多次操作特定数据集的应用场合。需要反复操作的次数越多,所需读取的数据量越大,受益越大,数据量小但是计算密集度较大的场合,受益就相对较小;
2.由于RDD的特性,Spark不适用那种异步细粒度更新状态的应用,例如web服务的存储或者是增量的web爬虫和索引,即对于那种增量修改的应用模型不适合:
3.数据量不是特别大,但是要求实时统计分析需求。在实际应用中,互联网公司的玩法是主要应用在广告、报表、推荐系统等业务中。在广告业务方面需要大数据做应用分析、效果分析、定向优化等,在推荐系统方面则需要大数据优化相关排名、个性化推荐以及热点点击分析等。不难发现这些场景无外乎是数据量大、计算量大、效率高特点。
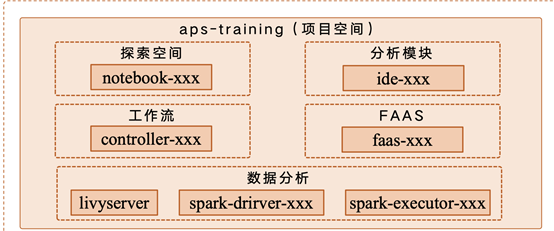
Spark生态
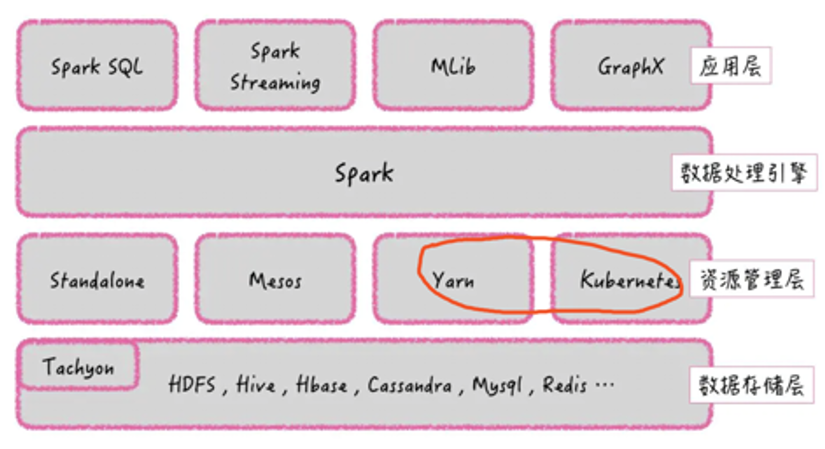
Spark集群
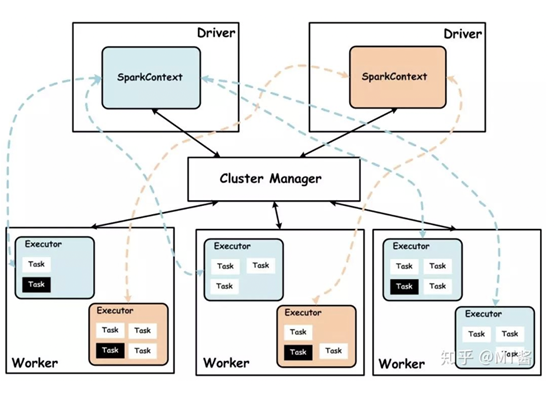
传统集群(CDH集群)
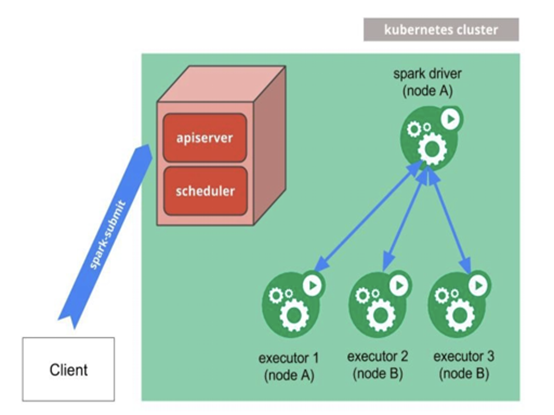
容器部署
使用与Yarn相反的Kubernetes集群具有明显的好处:
l 成本:相较于CDH集群,Kubernetes集群支持联邦集群、联邦应用等特性。
l 弹性:Cloud中的Kubernetes集群支持弹性自动扩展。反之,Hadoop集群的扩展速度远远没有那么快,可以手动或自动完成(2019年7月预览)。
l 集成:我们可以在包装在Docker容器中的Kubernetes集群中运行任何工作负载。至少我还没见过写过Yarn App的人。
l 支持:我们无法完全控制Cloud提供的群集设置,并且通常在发行后的几个月内没有可用的最新版本的软件。但是,使用Kubernetes,我们完全可以自己构建映像。
l 其他Kuebernetes优点:具有Helm的CI / CD,可一键单击即可使用的监视堆栈,获得了广泛的欢迎和社区支持。当然还有HYPE诸如此类的优秀工具。
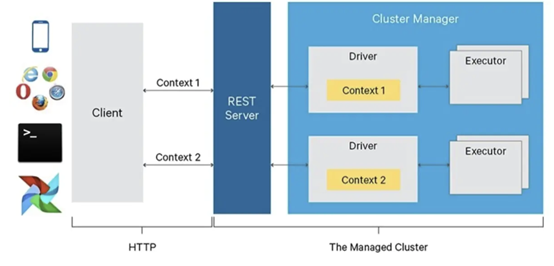
探索尝试
探索步骤
1. 搭建K8s集群
2.制作livy-server镜像
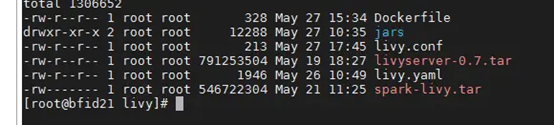
3.livy.conf配置master节点指向k8s

4.制作spark-livy镜像
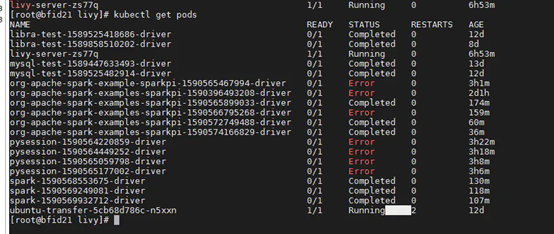
5.查看livy-spark pod
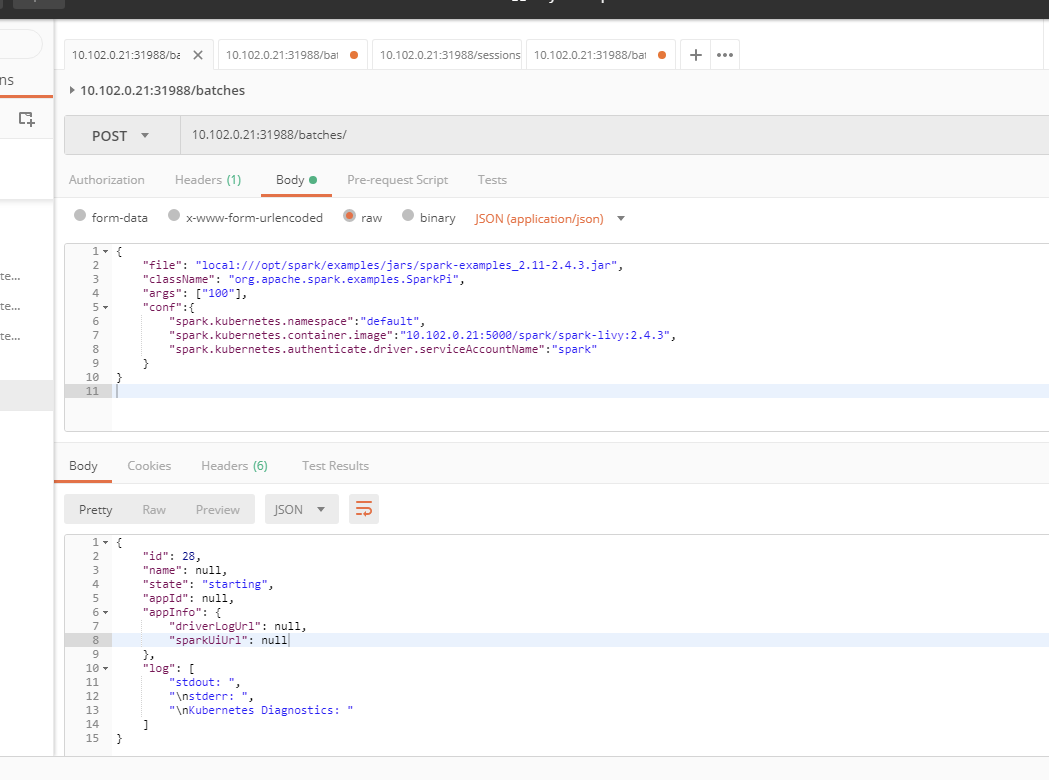
6.通过rest接口提交一个spark任务
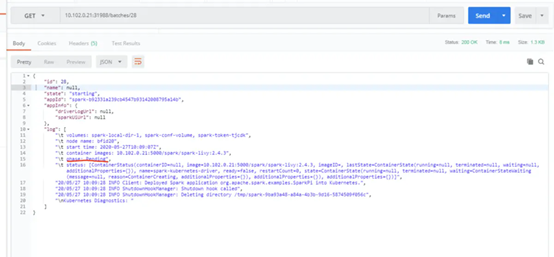
7.通过rest接口,可以轻松查看各个job状态和运行结果
结语