





点击上方蓝色字关注我们~

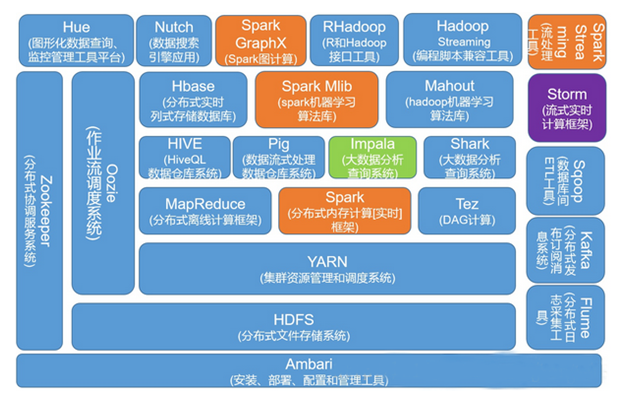
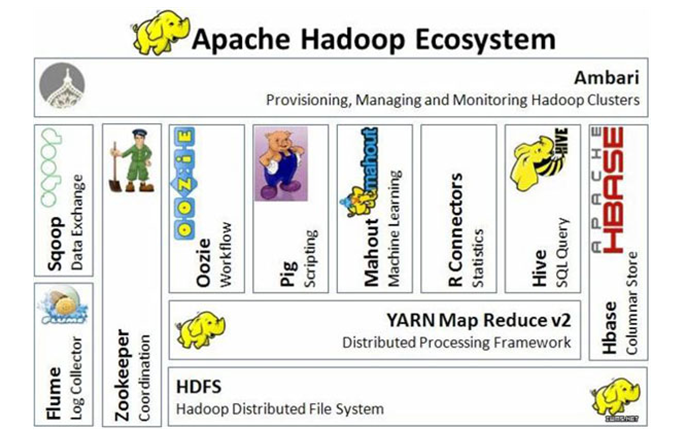

位于动物园最底层的是HDFS,它是各种动物的粮仓,这里的粮食就是数据。大家应该还没忘记上文提到的‘谷歌文件系统’,HDFS就是那篇文章的产物。在使用上,它和大家接触的普通文件系统没区别,就是创建文件夹、文件。最本质的区别就是你电脑中的文件系统是单机的,而HDFS是分布式的。所谓分布式就是把你的n多台电脑当成一台电脑使用,而且让你觉得真的是在使用一台,并且这台是‘超极本’,性能、内存、磁盘是n台的总和。
位于HDFS上面的是Yarn,它是资源调度的总司令。就好比打仗的时候,各大军区都需要飞机、大炮和粮草。总量就那么多,不可能你要多少就给你多少,一定要由总司令运筹帷幄。Yarn干的就是这个事情,至于争夺资源的各大军区则是什么Spark、MapReduce。除了分配资源,Yarn也要指挥各大军区的作战,用专业的话讲叫做调度各种任务的作业运行。
谈到大数据就有一个绕不去坎,那就是MapReduce,作为谷歌三驾马车中的又一位狠角色,当年学习它的时候确实老费劲了。通俗的解释一下,MapReduce就是工厂流水线的各道工序,负责加工的就是数据文件。
举个例子:如果你有一份公司人员的工资单,你想计算出总的人力成本,利用MapReduce就可以实现。
上文已提到谷歌三驾马车的两架,剩下一架‘Bigtable’的实现就是HBase。HBase是一款高可用的、高性能的、面向列式存储的、可伸缩的分布式数据仓库。是不是很牛逼,但用起来如果没有一定功底,那是真的很难用。犹如大家闺秀的一般,各种的讲究。给大家普及一下什么是列存和行存吧,它们的样子如下图所示。

行式的代表就是以Oracle为首的关系型数据库。它的优点就是非常适合随机的增删改查以及所有属性的查询。那列式则在随机查询个别字段具备较高的响应速度以及具有较高的I/O压缩比。
上图的蜜蜂是什么鬼?它的名字叫Hive。它是和oracle比较类似的工具。如果你是一位数据分析工程师,你一定会爱死它的。因为它支持sql语法,并且具备海量数据分析计算的能力。更直观的解释一下:某局点原来用oracle跑了一天的业务sql,Hive两三个小时搞定了。但它也有软肋,一个简单的查询原来用oracle那是秒出,如果用hive,估计你会恼羞成怒的,它能跑十几分钟才有结果。这就是上文提到的大数据工具的局限性。
由于动物园里的动物确实有点多,这里就不在一一介绍。就按照它们所属的大数据的环节做一下归纳吧。
数据采集:将数据从某系统搬到大数据平台。这其中的工具包括Flume、Kafka、Sqoop、Datax等。
数据存储:存放数据的池子,包括HDFS、HBase。
数据计算:针对批处理、流计算,分别有MapReduce、Spark、Storm、SparkSteaming、Flink等计算框架。
数据交互:对计算框架的一种封装,方便用户包括使用,包括Hive、Spark SQL、Impala等。
有了前世与今生!那么随着当前大数据体系底层技术框架的尘埃落定,大数据的未来何去何从?可以预见的是,大数据技术的发展方向也是会见风使舵的,它正从聚焦解决海量数据的低成本存储与规模化处理向提升效率大步迈进。这样迈进会对具体行业产生怎样的深远影响?
长话短说就以咱从事的银行业进行概括说明,以作为本文的收尾,可能总结会有些晦涩,但每一次的分享都是一种沉淀和成长。
一方面是大数据处理与分析技术,从单一的技术体系向更加高效的混合计算框架、算力融合、云数融合方向发展,将强有力的支撑咱们银行业的智能营销、资金行为分析、风控反欺诈等领域;
另一方面是大数据科学本身的相关研究,包括基于AI的数据管理、边缘数据科学等将极大的推动商业银行战略转型,优化银行资源配置,进而提升整体营运水平。

— END —
数匠笔谈
感觉内容很精彩?
快长按下方二维码关注我们~~

