
最近找实习发现数据结构与算法不太会,基本和互联网IT岗位无缘,想要转行到互联网/计算机,数据结构与算法是敲门砖啊,今天我们就来谈一下数据结构的入门知识。
1 数据结构简介
数据结构的出现是为了方便计算机更加高效的处理本身具有一定逻辑关系的数据,不同的数据结构适用于不同的场景,甚至一些会专门为某一个任务设计一种数据结构。例如 图(Graphs) 被用于社交网络如微信,Twitter等;树(Tree)被用来表示有层次的数据如你的文件夹系统;队列(Queues)可被用于创建任务调度器,哈希表(Hash tables)被用于编译器的标识符查询;二叉树(Binary trees)被用于搜索算法.....通常来说,选择正确的数据结构是设计有效的算法的关键,这里我们主要介绍几种常见的数据结构来入门。数组(Array)
链表(Linked List)
栈(Stack)
队列(Queues)
图(Graph)
二叉树(Binary Tree)
哈希表(Hash Table)
2 数组(Array)
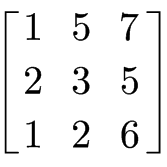
数组是计算机数据处理中最常用的数据结构之一。顾名思义,数组是一系列相同数据类型数值的组合,这些数被连续的存储在一段连续的物理存储器上,如RAM。举一个例子,将上面这个数组赋值给一个变量时,这个数组会存储在计算机的RAM上,如下图所示,每一个数都对应一个唯一的物理地址。
值
| 1
| 5
| 7
| 2
| 3
| 5
| 1
| 2
| 6
|
地址
| #2140
| #2141 | #2142 | #2143 | #2144 | #2145 | #2146 | #2147 | #2148 |
这种首尾的结构通常叫做线性表结构,之后要讲到的链表,栈,队列也都是线性表结构,与之对立的自然就是非线性表结构,如图和树。3 链表(Linked List)
链表作为一种基础数据结构,常被用于实现其他的数据结构。如图所示,链表是一系列的节点(Node),节点中包含了存储的数据本身以及指向下一节点的指针(地址),值得注意的是,链表的最后一个节点内的指针,指向的是NULL,即代表了链表的结尾。

虽然链表类似于数组,但它不限于声明的元素数量。此外,与连续存储数据在内存或磁盘上的数组不同,链表可以轻松地插入或删除元素,而无需重新分配或重组整个结构,因为数据项不需要连续存储,而是通过指针连接。链表也有它的缺点,一是不允许随机访问,我们必须从第一个节点开始按顺序访问节点。因此,我们不能对链表进行二分查找。另外,链表每个元素需要额外的内存空间用于链接栈是一种简单的数据结构,它按照特定的顺序增加和删除元素。每次添加元素的时候,总是被添加在栈的最顶端,只有在最顶端的元素能够被删除,这就叫做后进先出。向堆中添加元素叫做Push,删除元素叫做Pop。栈可以被用于设计“重做/撤销”功能。

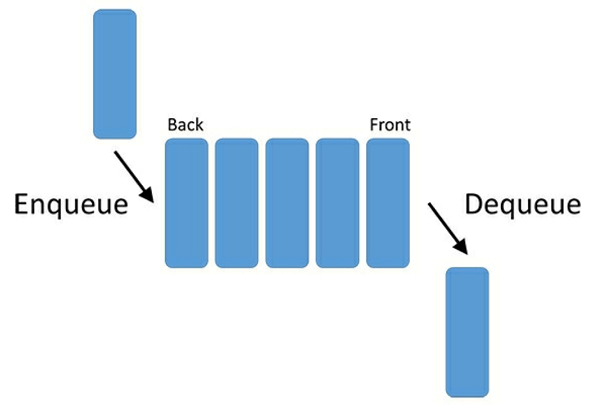
队列和栈一样,也是最基础的数据结构,队列一个接一个的插入元素,但只能从最先插入的元素开始删除,最先插入元素的一端叫做头部(Head),最后插入的一端叫做尾部(Tail),对标栈,队列的这种方式可以总结成先进先出。在队列中,添加元素叫做入队(enqueue),删除元素叫做出队(dequeue)。队列可以应用于诸如打印机打印文件时的排队等类似需要先进先出顺序的场景。
图是一种非线性表结构,常常被用于表示许多真实生活中的应用,如网络,城市交通路径,以及如微信这类社交软件中,每个用户都可以代表图中的一个节点。图在计算机科学中也应用十分广泛,如在机械学习领域中一些图模型的表示等。
图是一堆相互连接的节点的集合,其中每个节点被称作顶点(Vertex),连接顶点之间的连线叫做边(Eage)。图定义为一种由一系列有限的顶点和边组成的数据结构。图可以分为有向图(directed)和无向图(undirected)两种结构,如下图中的A和B。
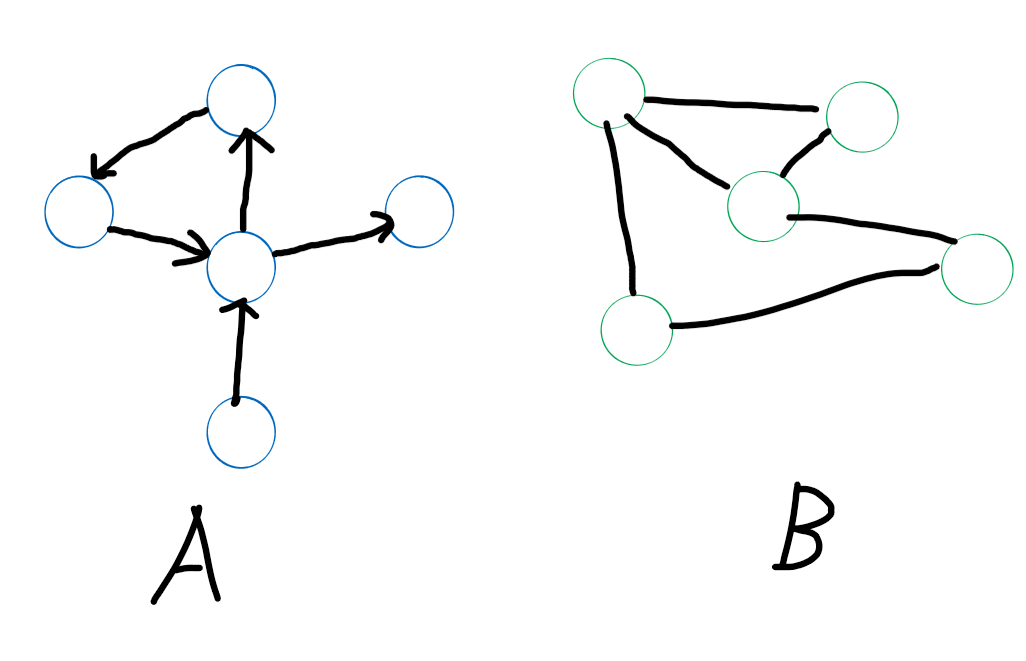
在有向图中,每条边都被加上了方向的定义,比如在微博中,你点击关注丁禹锡,表示建立了从你指向丁禹锡的“边”,但是丁禹锡并不会关注你,所以这种边是有单方向指向的。而无向图更像是微信,你如果加了丁禹锡微信好友,那么你是他的好友,他也是你的好友,所以,这种连接时没有方向的,是双向的。
7 二叉树(Binary Tree)
二叉树是一种典型的分层结构,它由相互连接的节点组成,之所以叫做二叉树,是因为每个节点最多只能有两个子节点。最上面的节点叫做根节点(Root),对于每一个给定的节点,与它直接相连且在它之下的节点被称之为子节点(children),在它之上的称之为父节点(parent)。父节点和子节点一起被称作子树,如果一个节点没有子节点,则称之为叶子节点。从根节点到叶子节点的最大节点数称之为二叉树的高度。下图详细展示了这些概念。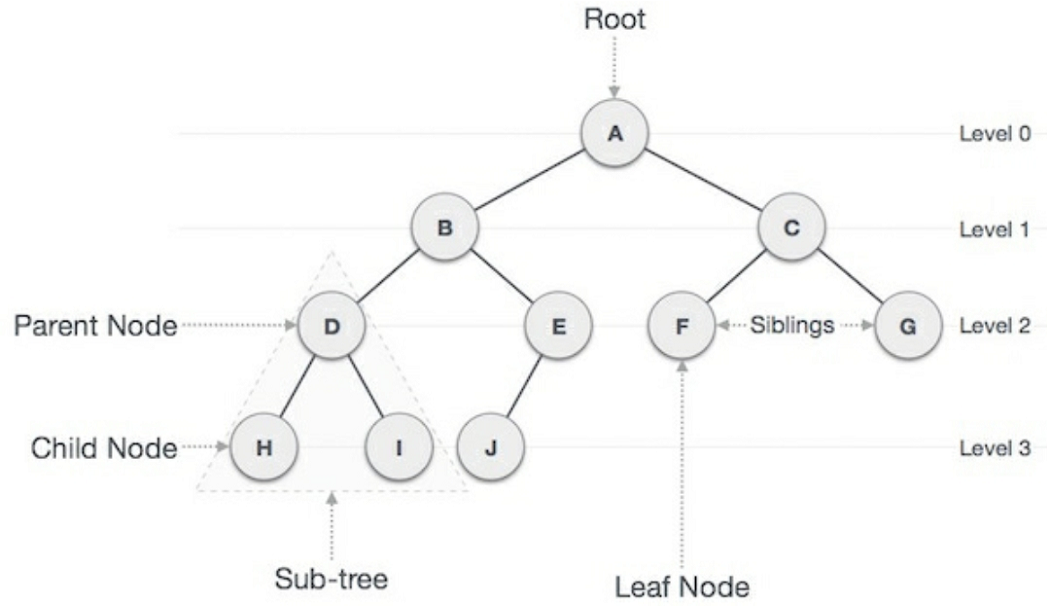
二叉树反映数据中的结构关系,用于表示层次结构,并且能高效的插入和搜索,同时树的结构也非常灵活,可以使用最小的代价移动子树。
8 哈希表(Hash Table)
哈希表是一种将键(key)映射到值(Value)的结构,在介绍哈希表之前,需要先了解一下什么是哈希(Hash)。哈希是一种用于从一组类似对象中唯一标记特定对象的技术,在我们的日常生活就经常用到哈希技术,如学校的每个学生都有自己的学号,这种将人映射到唯一的编号就是一种哈希方法;又比如图书馆中的每一本书也都有独立的位置编号一样。哈希函数可以是任何将任意大小的数据集映射到哈希表中固定大小的数据集的函数,比如输入学生名字,返回的是学生的ID(Hash值)。哈希函数必须保证每一个元素的哈希值都是唯一的,这样才能避免冲突。
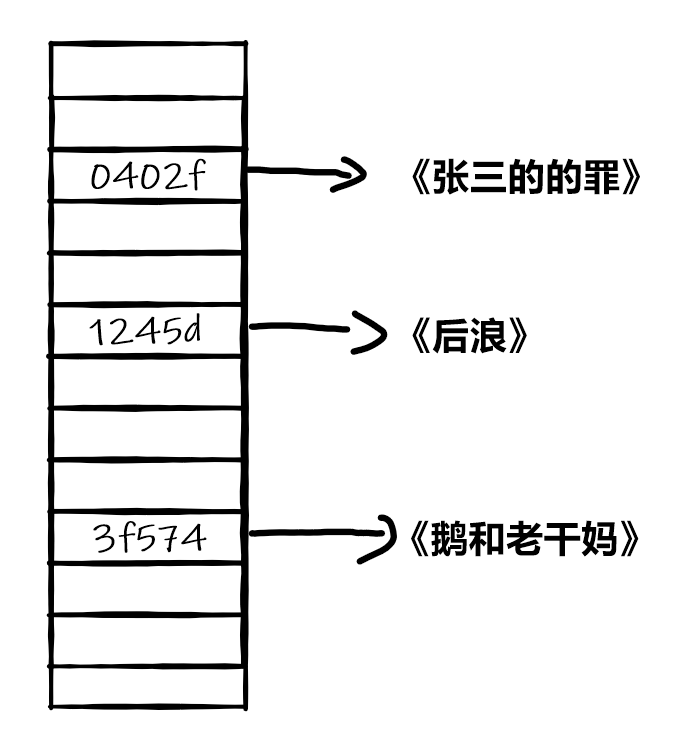
哈希表,实际上就是键为通过哈希函数获取的唯一的哈希值,值为对应数据的表的结构。如果想从哈希表中寻找一本书,只需要将书名输入到哈希函数中,直接通过于哈希表中的键匹配,就可以获得书对应的位置了。哈希表的优点就在于可以通过键直接的匹配到想要的值,但哈希表无法记录数据输入的顺序,所以排序效率不高。
其实心里有很多话想说,但夜深人静了,无意再添负能量。

注:部分图和概念搬运自Sololearn,作为学习记录使用 SoloLearn官网: https://www.sololearn.com/Courses/





