




Doris的存储引擎
数据库的存储引擎是最重要的组件,一直好奇Doris的存储引擎是怎么工作的?只知道它最终落盘也是sstable的组织格式。目前数据库技术存储引擎,主流分成B树与LSM树一样,B树的最小存储单元是页块,为了适配操作系统接口,数据页块会与分布式文件系统一样。 而LSM则是把数据分成两部分,增量数据在内存,固化数据以sstable的形式存储在硬盘。
Oceanbase是按行组划分,再按列组划分,最后以sstable保存在硬盘。而Doris是全列的sstable的方式 保存在磁盘。
下面探测一下,建立一个中规中矩的table_duplicate表,然后不停的插入数据
CREATE TABLE IF NOT EXISTS testdoris.table_duplicate
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`timestamp` DATETIME NOT NULL COMMENT "数据灌入的时间戳",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",
`cost` BIGINT DEFAULT "0" COMMENT "用户总消费",
`max_dwell_time` INT DEFAULT "0" COMMENT "用户最大停留时间",
`min_dwell_time` INT DEFAULT "99999" COMMENT "用户最小停留时间"
)
ENGINE=olap
DUPLICATE KEY(`user_id`, `date`)
PARTITION BY RANGE(`date`)
(
PARTITION `p202001` VALUES LESS THAN ("2020-02-01"),
PARTITION `p202002` VALUES LESS THAN ("2020-03-01"),
PARTITION `p202003` VALUES LESS THAN ("2020-04-01")
)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 16
PROPERTIES
(
"replication_num" = "1"
);
持续不停的插入数据
insert into table_duplicate values(1,'2020-2-1','2020-2-1','gz',39,1,'2020-2-1',100,24,48);
存储层对存储数据的管理通过storage_root_path路径进行配置,路径可以是多个。存储目录下一层按照分桶进行组织,分桶目录下存放具体的tablet,按照tablet_id命名子目录并且以dat文件结尾,类似0200000000000069194cb42adb454853b4849dae1cdcb58a_0.dat
笔者理解每一个dat就是一个sstable文件。
[root@server130 data]# find . -name "*dat" | wc -l
218
通过重启be服务,相关dat也没有减少,等待良久后,再查看,发现dat文件在减少
[root@server130 data]# find . -name "*dat" | wc -l
184
笔者再做了一个aggregator的实验,建立一个中规中矩的table_aggregator表,然后不停的插入同样的数据
drop table testdoris.table_aggregate;
CREATE TABLE IF NOT EXISTS testdoris.table_aggregate
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`timestamp` DATETIME NOT NULL COMMENT "数据灌入的时间戳",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",
`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
)
ENGINE=olap
AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`)
PARTITION BY RANGE(`date`)
(
PARTITION `p202001` VALUES LESS THAN ("2020-02-01"),
PARTITION `p202002` VALUES LESS THAN ("2020-03-01"),
PARTITION `p202003` VALUES LESS THAN ("2020-04-01")
)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 16
PROPERTIES
(
"replication_num" = "1"
);
测试中发现,连续增加70个数据,一开始对应的dat文件有上升,但是很快就会降下去,总的来看dat文件还是很多。
[root@server130 data]# find . -name "*dat" | wc -l
276
[root@server130 data]# find . -name "*dat" | wc -l
163
[root@server130 data]# find . -name "*dat" | wc -l
167
[root@server130 data]# find . -name "*dat" | wc -l
167
[root@server130 data]# find . -name "*dat" | wc -l
167
[root@server130 data]# find . -name "*dat" | wc -l
167
[root@server130 data]# find . -name "*dat" | wc -l
167
看到官方的建议,doris 系统本身不适合 单条数据(超过500 报错)的导入,建议批量导入。
我就一直等下去,等了两三个小时,再查看dat数量,后台线程 慢 慢 整合成了32个,
[root@server130 be]# find ./storage/ -name "*dat" | wc -l
32
加大注码,这次采用导入数据的方式批量导入
[root@server130 ~]# wc -l loadfile.txt.1
3332476 loadfile.txt.1
[root@server130 ~]# curl -u root -H "label:load_local_file"21 -H "column_separator:,"
-T /root/loadfile.txt.1
http://19.168.178.130:8040/api/testdoris/table_aggregate/_stream_load
Enter host password for user 'root':
{
"TxnId": 4268,
"Label": "load_local_file21",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 3332476,
"NumberLoadedRows": 3332476,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 156626372,
"LoadTimeMs": 5261,
"BeginTxnTimeMs": 2,
"StreamLoadPlanTimeMs": 5,
"ReadDataTimeMs": 4822,
"WriteDataTimeMs": 5233,
"CommitAndPublishTimeMs": 20
[root@server130 be]# find ./ -name "*dat" |wc -l
33
仅仅增加了一个文件
[root@server130 ~]# wc -l loadfile.txt
33324760 loadfile.txt
[root@server130 ~]# du -sh loadfile.txt
1.9G loadfile.txt
[root@server130 ~]# curl -u root -H "label:load_local_file3" -H "column_separator:,"
-T /root/loadfile.txt
http://192.168.178.130:8040/api/testdoris/table_aggregate/_stream_load
Enter host password for user 'root':
{
"TxnId": 4270,
"Label": "load_local_file3",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 33324760,
"NumberLoadedRows": 33324760,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 1566263720,
"LoadTimeMs": 50800,
"BeginTxnTimeMs": 3,
"StreamLoadPlanTimeMs": 4,
"ReadDataTimeMs": 48814,
"WriteDataTimeMs": 50774,
"CommitAndPublishTimeMs": 17
[root@server130 be]# find ./ -name "*dat" |wc -l
62
仅仅增加30个dat文件,这下子我悟了
[root@server130 ~]# curl -u root -H "label:load_local_fduplicate" -H "column_separator:,"
-T /root/loadfile.txt
http://192.168.178.130:8040/api/testdoris/table_duplicate/_stream_load
Enter host password for user 'root':
{
"TxnId": 4272,
"Label": "load_local_fduplicate",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 33324760,
"NumberLoadedRows": 33324760,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 1566263720,
"LoadTimeMs": 43593,
"BeginTxnTimeMs": 3,
"StreamLoadPlanTimeMs": 10,
"ReadDataTimeMs": 41563,
"WriteDataTimeMs": 43531,
"CommitAndPublishTimeMs": 48
针对duplicate的导入也很友善
dat文件结构
dat文件结构类似sstable的结构,也有人说它的结构类似orc,暂时把它当成sstable吧。
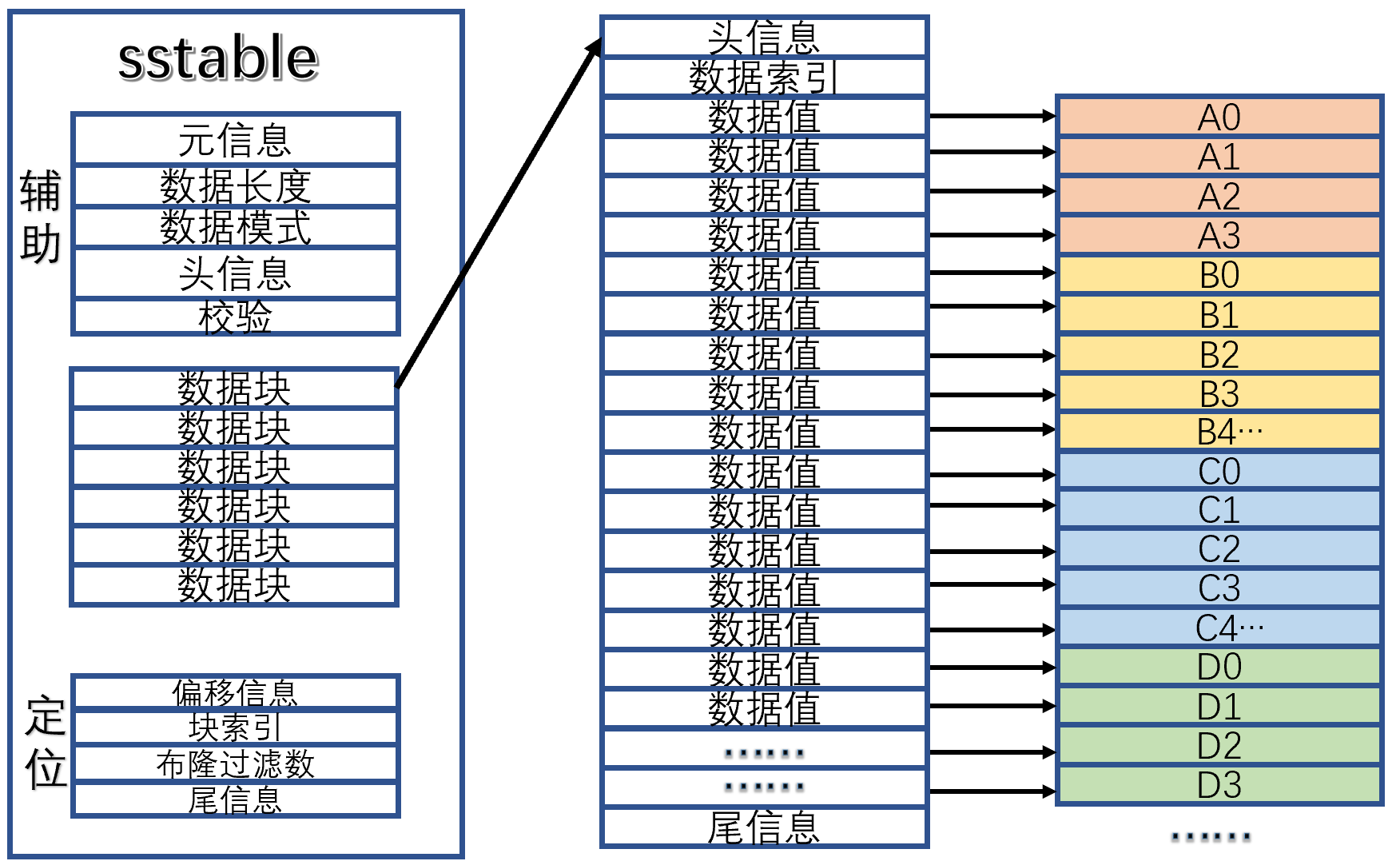
sstable有三个区域,一个是辅助区域,主要是定义内部具体数据位置和检索引,一个是定位区域,主要是sstable的外部文件检索,一个是数据区域,主要是里面保存的数据。
Doris的数据区域都是按列式排列的数据,辅助区域都是KEY式索引以及信息校验,定位区域是sstable的全局管理信息块。
OceanBase的数据区域则是先按行组划分,再按列组划分。OceanBase和Doris的最大的不同是sstable的生成时机,生成sstable是一个昂贵的开销。OceanBase会把增量数据放在memtable,满足阀值或者定时触发才形成一个sstable,称之为转储。根据sstable的大小,固态数据还会与增量数据合并成一个大的sstable。
Doris没有OB的机制,虽然有后台持续不断对sstable进行合并优化,但是工作效率慢。
总结
- insert 不友好,每一条插入都会形成一个sstablle文件,虽然Doris有后台线程合并文件,但是工作很慢。
- 批量倒入友好,即使很大的数据导入,也是高浓度压缩,紧缩凑合在一个文件上。
- Doris对数据的特征会做校验和,如果是相同的文件,不会额外占有空间。
