




前言
今天下午,同事找到我说:
有一个远程备库,通过 ps 发现很多查询都是等待的状态,全部被 startup 进程阻塞了
这个案例乍一听就是流复制冲突,但是上去看了一下,发现又有所不同,以往的流复制冲突典型场景是在备库上执行长时间的查询,由于涉及的记录有可能在主库上被更新或删除,主库上对更新或删除数据的老版本进行 vacuum 后,从库上也会执行这个操作,从而与从库上依旧需要这些老版本的查询产生冲突,然后现象就是 startup waiting。
但是这次的现象完全不同,startup 进程正常,而 SELECT waiting。开了眼了,让我们一起分析一下这个有趣案例。
分析
现象前面已经提及,可以看到与我们以往遇到的 recovery conflict 有很大不同 👇🏻 这次换成了 startup 进程在运行,select waiting。
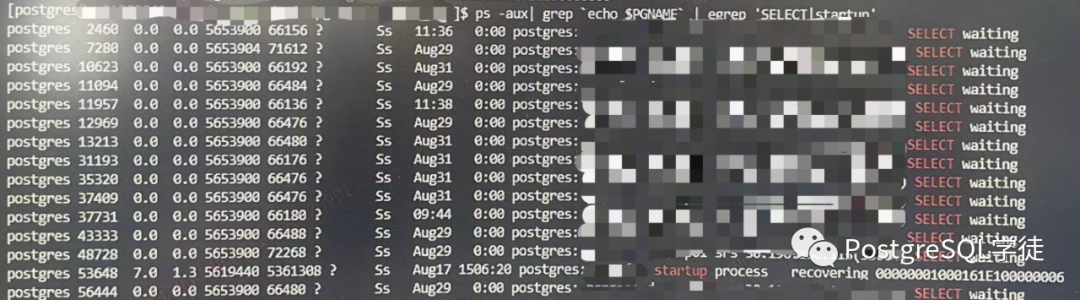
而这些等待的查询,检查锁队列,发现都被 53648 进程阻塞,而 53648 正是 startup 进程。
waiter | holder | root_holder | path | deep
--------+--------+-------------+--------------+------
56444 | 53648 | 53648 | 56444->53648 | 1
12969 | 53648 | 53648 | 12969->53648 | 1
2460 | 53648 | 53648 | 2460->53648 | 1
11957 | 53648 | 53648 | 11957->53648 | 1
11094 | 53648 | 53648 | 11094->53648 | 1
35320 | 53648 | 53648 | 35320->53648 | 1
13213 | 53648 | 53648 | 13213->53648 | 1
37409 | 53648 | 53648 | 37409->53648 | 1
7280 | 53648 | 53648 | 7280->53648 | 1
48728 | 53648 | 53648 | 48728->53648 | 1
10623 | 53648 | 53648 | 10623->53648 | 1
31193 | 53648 | 53648 | 31193->53648 | 1
43333 | 53648 | 53648 | 43333->53648 | 1
37731 | 53648 | 53648 | 37731->53648 | 1
(14 rows)
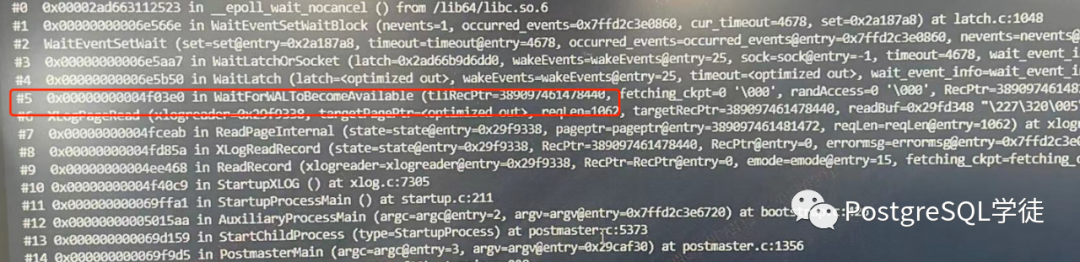
startup 进程的堆栈显式了一个有趣的地方——WaitForWALToBecomeAvailable,让我们后面再回过来说这个。
这些阻塞的查询位于远程备库,主要跑一些鸡零狗碎的监控采集信息,
SELECT
*
FROM (
SELECT
n.nspname,
c.relname,
a.attname,
a.atttypid,
a.attnotnull
OR (t.typtype = 'd'
AND t.typnotnull) AS attnotnull,
a.atttypmod,
a.attlen,
t.typtypmod,
row_number() OVER (PARTITION BY a.attrelid ORDER BY a.attnum) AS attnum,
nullif (a.attidentity, '') AS attidentity,
NULL AS attgenerated,
pg_catalog.pg_get_expr(def.adbin, def.adrelid) AS adsrc,
dsc.description,
t.typbasetype,
t.typtype
FROM
pg_catalog.pg_namespace n
JOIN pg_catalog.pg_class c ON (c.relnamespace = n.oid)
JOIN pg_catalog.pg_attribute a ON (a.attrelid = c.oid)
JOIN pg_catalog.pg_type t ON (a.atttypid = t.oid)
LEFT JOIN pg_catalog.pg_attrdef def ON (a.attrelid = def.adrelid
AND a.attnum = def.adnum)
LEFT JOIN pg_catalog.pg_description dsc ON (c.oid = dsc.objoid
AND a.attnum = dsc.objsubid)
LEFT JOIN pg_catalog.pg_class dc ON (dc.oid = dsc.classoid
AND dc.relname = 'pg_class')
LEFT JOIN pg_catalog.pg_namespace dn ON (dc.relnamespace = dn.oid
AND dn.nspname = 'pg_catalog')
WHERE
c.relkind IN ('r', 'p', 'v', 'f', 'm')
AND a.attnum > 0
AND NOT a.attisdropped
AND n.nspname LIKE 'public'
AND c.relname LIKE '%') c
WHERE
TRUE
AND attname LIKE '%'
ORDER BY
nspname,
c.relname,
attnum;
让我们检查下具体是哪个对象获取不到锁,根据 granted 为 false 找到表的 oid 即可
[postgres:5xxx@xxx] [09-01.16:43:54]=# select * from pg_locks where granted = 'f';
locktype | database | relation | page | tuple | virtualxid | transactionid | classid | objid | objsubid | virtualtransaction | pid | mode | granted | fastpath
----------+----------+------------+------+-------+------------+---------------+---------+-------+----------+--------------------+-------+-----------------+---------+----------
relation | 17037 | 3504782500 | | | | | | | | 7/10 | 56444 | AccessShareLock | f | f
relation | 17037 | 3504782500 | | | | | | | | 9/96 | 12969 | AccessShareLock | f | f
relation | 17037 | 3504782500 | | | | | | | | 16/518 | 2460 | AccessShareLock | f | f
relation | 17037 | 3504782500 | | | | | | | | 17/38 | 11957 | AccessShareLock | f | f
relation | 17037 | 3504782500 | | | | | | | | 8/479 | 11094 | AccessShareLock | f | f
relation | 17037 | 3504782500 | | | | | | | | 11/324 | 35320 | AccessShareLock | f | f
relation | 17037 | 3504782500 | | | | | | | | 12/73 | 13213 | AccessShareLock | f | f
relation | 17037 | 3504782500 | | | | | | | | 10/7693 | 37409 | AccessShareLock | f | f
relation | 17037 | 3504782500 | | | | | | | | 4/22513 | 7280 | AccessShareLock | f | f
relation | 17037 | 3504782500 | | | | | | | | 5/108 | 48728 | AccessShareLock | f | f
relation | 17037 | 3504782500 | | | | | | | | 14/11 | 10623 | AccessShareLock | f | f
relation | 17037 | 3504782500 | | | | | | | | 6/32964 | 31193 | AccessShareLock | f | f
relation | 17037 | 3504782500 | | | | | | | | 3/75326 | 43333 | AccessShareLock | f | f
relation | 17037 | 3504782500 | | | | | | | | 15/2224 | 37731 | AccessShareLock | f | f
(14 rows)
Time: 5.789 ms
[postgres:5xxx@xxx] [09-01.16:44:03]=# select 3504782500::regclass;
regclass
-----------------
d_cx_fct_xxx
(1 row)
Time: 0.442 ms
[postgres:5xxx@xxx] [09-01.16:44:10]=# select * from d_cx_fct_xxx limit 1;
---此处夯住
可以看到,全都是在申请 d_cx_fct_xxx 表上的 AccessShareLock,我手动查询发现也被阻塞了。那么为什么会这样?根据冲突矩阵,AccessShareLock 只跟 AccessExclusiveLock 冲突,即只跟最重的 8 级锁冲突,默认是 startup 回放了一条 AccessExclusiveLock?
那让我们用 pg_waldump 解析一下 WAL,看看有没有和这个表相关的 record
[postgres@xxx /postgres/data/pg_wal]$ pg_waldump 00000001000161E100000006 | grep 3504782500 | more
rmgr: Standby len (rec/tot): 66/ 66, tx: 0, lsn: 161E1/C6913010, prev 161E1/C6912FB8, desc: LOCK xid 1019377916 db 17037 rel 3504782500 xid 1019377916 db 17037 rel 3504782508 xid 1019377916 db 17037 rel 3504782510
pg_waldump: FATAL: error in WAL record at 161E1/CFF97338: unexpected pageaddr 161BC/FF98000 in log segment 00000000000161E100000006, offset 268009472
我去!居然报错了,提示了一条不知所以然的错误,以前从未见过。不过这不重要,我们能很清晰地看到有一条 XLOG_STANDBY_LOCK 相关的信息,然后接着解析就报错了,典型场景就是 DDL

为什么会这样?这让我想起了在 29 号发生的一起网络故障
在 8.29 号的时候,网络曾出现过问题,一条链路丢包持续增长,很多业务库都产生了大量延迟,直到 8.30 号网络组才将错误链路给隔离,隔离之后,延迟逐渐追平,这个远程库也未能幸免,流复制断掉了!
感觉大概率和这个网络故障有关,传到一半尿了。远程备库看不了,那让我们去主库上看看这条日志,因为是 29 号的,早就被回收了,但好在还有归档,让我们也解析一下
[postgres@xxx /postgres/data/archlog]$ pg_waldump 00000001000161E100000006 | grep 3504782500 | more
rmgr: Standby len (rec/tot): 66/ 66, tx: 0, lsn: 161E1/C6913010, prev 161E1/C6912FB8, desc: LOCK xid 1019377916 db 17037 rel 3504782500 xid 1019377916 db 17037 rel 3504782508 xid 1019377916 db 17037 rel 3504782510
rmgr: Standby len (rec/tot): 66/ 66, tx: 0, lsn: 161E1/D6DC6960, prev 161E1/D6DC6890, desc: LOCK xid 1019377916 db 17037 rel 3504782500 xid 1019377916 db 17037 rel 3504782508 xid 1019377916 db 17037 rel 3504782510
rmgr: Standby len (rec/tot): 66/ 66, tx: 0, lsn: 161E1/D9786E18, prev 161E1/D9786DC0, desc: LOCK xid 1019377916 db 17037 rel 3504782500 xid 1019377916 db 17037 rel 3504782508 xid 1019377916 db 17037 rel 3504782510
这次就很清晰了,主库上有三条相关的日志,而远程备库上接收到了一条就嗝屁了。。去日志里搜一下,果然,在 29 号的时候做了 DDL,总共做了三次。
2023-08-29 08:07:12.453 CST,"xxx","xxx",32517,"xxx",64ed2ddc.7f05,4,"SELECT",2023-08-29 07:29:32 CST,35/13664671,1019377916,LOG,00000,"duration: 2260126.984 ms plan:
Query Text: truncate table d_cx_fct_xxx;
insert into d_cx_fct_xxx ...
至此,现象已经很明了了,主库给备库发送 record,结果这个时候网络抽风了,发送了一条就因丢包断了,导致只发送了一条,更尴尬的是,发送过来了一条最重的 DDL
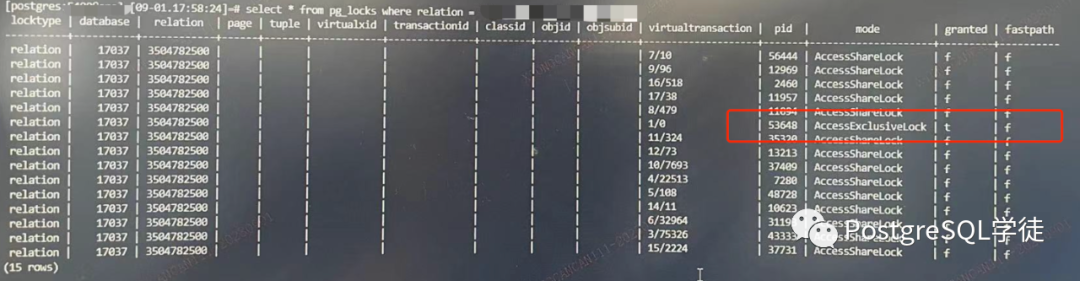
很清晰,53648 获取了 AccessExclusiveLock,而 53648 正是 startup 进程。
小结
这个案例说巧也巧,startup 回放到最重的 DDL 之后就嗝屁了,流复制断掉,导致只要涉及到这个表就会阻塞,不人工介入的话就会永远卡在这里,真是令人直抓脑壳,当然解决办法也简单,重建 😎
回到刚刚说的 WaitForWALToBecomeAvailable,代码里很清晰,读取包含指定位点的 WAL
/*
* Open the WAL segment containing WAL location 'RecPtr'.
*
* The segment can be fetched via restore_command, or via walreceiver having
* streamed the record, or it can already be present in pg_wal. Checking
* pg_wal is mainly for crash recovery, but it will be polled in standby mode
* too, in case someone copies a new segment directly to pg_wal. That is not
* documented or recommended, though.
*
* If 'fetching_ckpt' is true, we're fetching a checkpoint record, and should
* prepare to read WAL starting from RedoStartLSN after this.
*
* 'RecPtr' might not point to the beginning of the record we're interested
* in, it might also point to the page or segment header. In that case,
* 'tliRecPtr' is the position of the WAL record we're interested in. It is
* used to decide which timeline to stream the requested WAL from.
*
* 'replayLSN' is the current replay LSN, so that if we scan for new
* timelines, we can reject a switch to a timeline that branched off before
* this point.
*
* If the record is not immediately available, the function returns false
* if we're not in standby mode. In standby mode, waits for it to become
* available.
*
* When the requested record becomes available, the function opens the file
* containing it (if not open already), and returns XLREAD_SUCCESS. When end
* of standby mode is triggered by the user, and there is no more WAL
* available, returns XLREAD_FAIL.
*
* If nonblocking is true, then give up immediately if we can't satisfy the
* request, returning XLREAD_WOULDBLOCK instead of waiting.
*/
static XLogPageReadResult
WaitForWALToBecomeAvailable(XLogRecPtr RecPtr, bool randAccess,
bool fetching_ckpt, XLogRecPtr tliRecPtr,
TimeLineID replayTLI, XLogRecPtr replayLSN,
bool nonblocking)
WAL 可能来自归档拷贝或人为拷贝,PostgreSQL 在读取 WAL 文件时会进行验证,可防止弄错文件,比如检查 WAL 页面头中记录的页地址是否正确,此例中发现后续的 record 没有之后,就会阻塞等待
If the record is not immediately available, the function returns falss. if we’re not in standby mode. In standby mode, waits for it to become available.
参考
https://aws.amazon.com/cn/blogs/china/manage-long-running-read-queries-on-amazon-aurora-postgresql-compatible-edition/
https://developer.aliyun.com/article/463915
