




多表关联查询
多维查询和即席查询底座下免不了多表查询,复杂的业务分析洞察免不了多表查询,多表查询是什么?简单的多表查询下面是星型,星型大多数情况是一个大表和多个小表关联,普通的多表查询是雪花模型,即两个事实表关联多个小表,复杂多表查询是星座模型 内含多个大事实表关联。
Clickhouse早已经放弃雪花模型和星座模型,目前仅支持星型模型,一般复杂一点的SQL操作都用了,TPC-H和TPC-DS基准测试都无法支持。
Doris比Clickhouse支持更多的SQL操作,内部JOIN操作有4种模式 Shuffle join、Bucket Shuffle join 、Broadcast join 、Colocate Join。
内部JOIN原理
多表查询与单表查询是不同的问题,单表是一元计算,而多表是两元计算。两元计算要提高性能,一个方法提高硬件配置CPU、内存、网络, 例如CPU绑核多线程并发,扩大网络为10000提高带宽传输 , 或者软硬件件结合的方式 ,例如向量化处理,首先CPU实现单指令多数据集,再实现较多的算子向量化。
还有一个策略办法计算贴 近存储,这是 Doris的秘决,通过计算贴 近存储去理解Doris的运算方式 。假如A表要G与B表进行关联,有下面4种策略。
- 预先干预,两个表的数据已经在同一个节点,不需要跨网络传输,直接本地计算。Colocate Join
- 计算前,把其中一个表的数据全量放到另外一个表上面,避够太多无谓的网络传输。Broadcast join
- 计算前,一个表的数据保持不动,另一个表把数据分散打到固定表上面,减少网络传输。Bucket Shuffle join
- 计算时, 两个表各自把数据打散后,网络上东奔西走按照特征合并,再向上汇总。 Shuffle join
Shuffle join
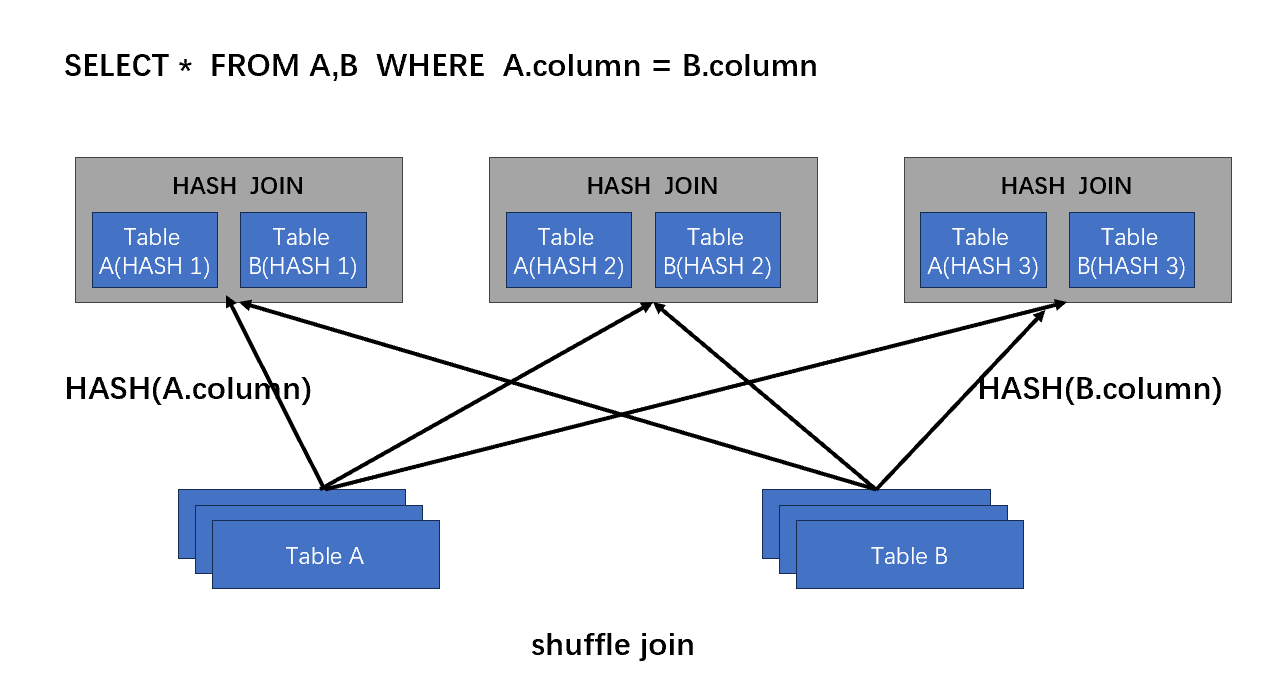
shuffle join是最传统的内部join方式,最早可以追溯到单机运行的 nestd loop join、merge join、hash join。shuffle join就是基于hash join的基础上发展起来的,不同的是shuffle必须有网络传输。
- 首先,AB两表根据连接操作的键(关联列),通过hash将输入数据集按键进行分组,这将导致将具有相同键值的记录划分到同一个分区中。
- 然后,将每个分区的数据通过网络传输到合适的计算节点,以便将具有相同键值的记录聚集在一起。
- 在目标计算节点上,对具有相同键值的记录进行合并操作。
- 最后,合并的结果可以存储在一个新的数据集中,或者用于进一步的计算或输出。
Bucket Shuffle
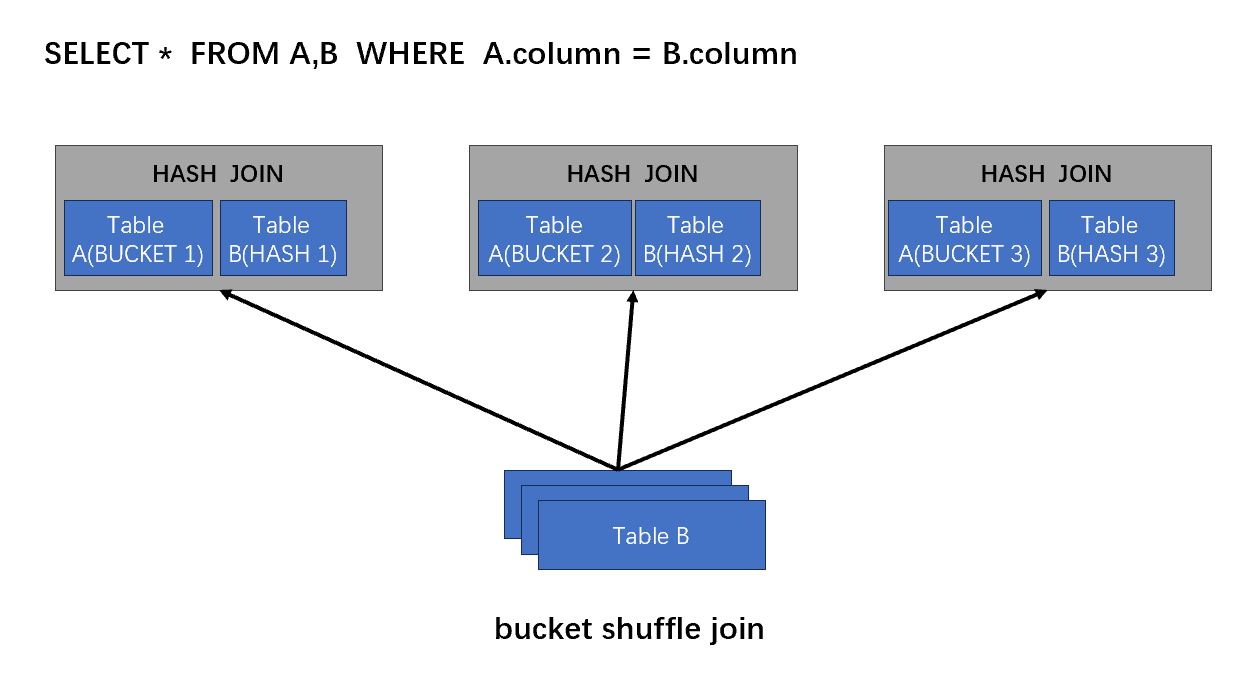
Bucket Shuffle join是Shuffle的升级,保持一个表不动,并把表的数据粒度最细,并且数据有序摆放。另外一个表【一般是较少的表】,小表主动做HASH分发,去匹配大表
- 首先,AB两表根据连接操作的键(关联列),较小表通过hash将输入数据集按键进行分组,这将使具有相同键值的记录划分到同一个分区中。
- 小表分区分区的数据通过网络传输到大表已经整理好的的数据上面,相同键值的记录聚集在一起。
- 目标计算节点上,对具有相同键值的记录进行合并操作。
- 合并的结果可以存储在一个新的数据集中,或者用于进一步的计算或输出。
Broadcast join
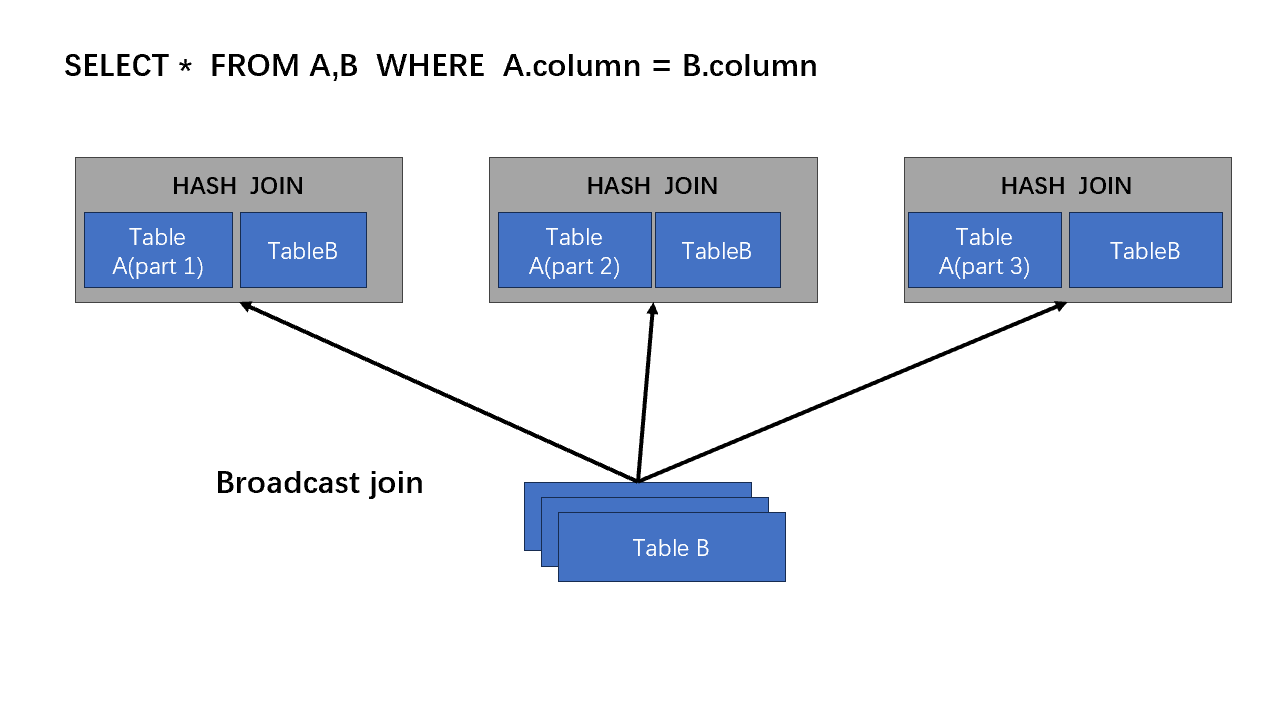
hadoop时代就用的分布式JOIN好方法,流传至今,Broadcast join依然是一个工程好方法。
Broadcast join是一个对内存要求很高的方法,因为它会提前把小表全放到目标计算点的内存里面。
- 首先,AB两表根据连接操作的键(关联列),小表发到所有的计算节点上面,保存到目标计算节点的内存。
- 目标计算节点上,两表的数据都在同一个位置了,根据相同的键值进行合并操作。
- 合并的结果可以存储在一个新的数据集中,或者用于进一步的计算或输出。
Colocate Join
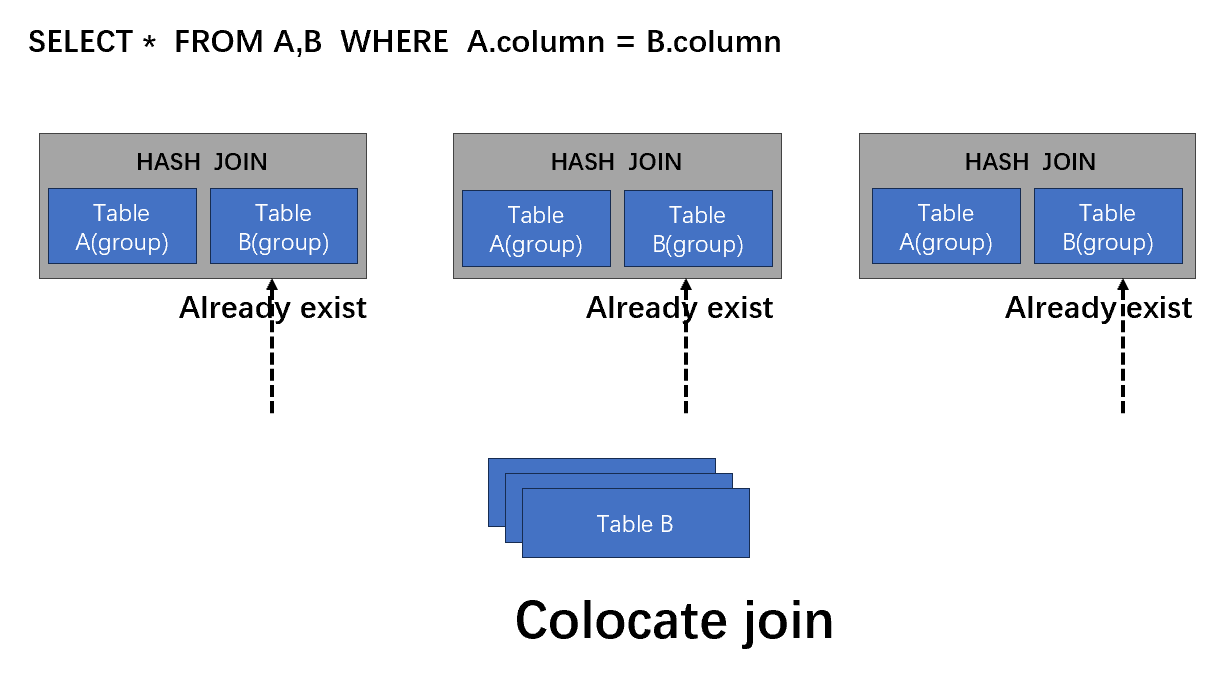
Colocate join其实是预计算的方式,必须要对业务有所洞悉,笔者看了Doris的建表,感觉还算友好。
- 首先,AB两表根据连接操作的键(关联列),大表小表已经同在一个节点。
- 计算节点上,根据相同的键值进行合并操作。
- 合并的结果向上汇总,直接输出结果。
附几段实战
Doris默认会使用broadcast join的方式
例如以下例子,优先会使用table12表的user_id列广播到每一个计算节点上面。
select sum(table12.cost) from table12 join table11 where table12.user_id = 10000;
显示braodcast join的方式
select sum(table12.cost) from table12 join [broadcast] table11 where table12.user_id = 10000;
显示 shuffle join的方式
select sum(table12.cost) from table12 join [shuffle] table11 where table12.user_id = 10000;
设置bucket shuffle join的方式
set enable_bucket_shuffle_join = true;
定义colocate,预先干预数据存储分布
CREATE TABLE tbl2 (
`k1` datetime NOT NULL COMMENT "k1",
`k2` int(11) NOT NULL COMMENT "k2",
`v1` double SUM NOT NULL COMMENT "v1"
) ENGINE=OLAP
AGGREGATE KEY(`k1`, `k2`)
DISTRIBUTED BY HASH(`k2`) BUCKETS 8
PROPERTIES (
"colocate_with" = "group1"
);
CREATE TABLE IF NOT EXISTS tbl1 (
`k1` date NOT NULL COMMENT "k1",
`k2` int(11) NOT NULL COMMENT "k2",
`v1` int(11) SUM NOT NULL COMMENT "v1"
) ENGINE=OLAP
AGGREGATE KEY(`k1`, `k2`)
PARTITION BY RANGE(`k1`)
(
PARTITION p1 VALUES LESS THAN ('2023-02-28'),
PARTITION p2 VALUES LESS THAN ('2023-03-31')
)
DISTRIBUTED BY HASH(`k2`) BUCKETS 8
PROPERTIES (
"colocate_with" = "group1"
);
