为便于读者理解,接下来以“企业级数据管理”与“一站式数据开发”两个核心需求为线索,拨开大数据应用平台层层迷雾。篇幅原因,这里仅对一种可行的架构设计思路、实现原理与各功能模块之间的交互关系进行解析,具体技术选型与编码实现等方案千千万,大家可自行发挥。
2、如何满足“一站式数据开发”需求?
再三思索,故事还是先从“一站式数据开发”的需求讲起。“一站式数据开发”的目的,一方面是为降低用户在做数据开发时的技术门槛,另一方面是为简化数据开发、测试与发布上线的流程,支持敏态开发。
“一站式数据开发”能力是直接面向用户的,因此,用户接口必须友好。首先需设计一个WEB UI界面,用于提供可视化的数据开发接口,例如,可在界面上以“托拽”数据开发算子的方式进行作业流的编排(一个完整作业流可根据业务需求由数据采集、数据集成ETL和数据挖掘各阶段的操作算子组成),以及配置作业相关描述信息(包括作业流中每部操作的数据源与数据目的信息、作业执行触发条件等信息)。前端界面会将用户编排的作业流与作业描述相关信息,以参数的形式传递给后端程序进行统一格式处理。这部分前端+服务端的业务逻辑,我们给它起名为“数据开发”组件。
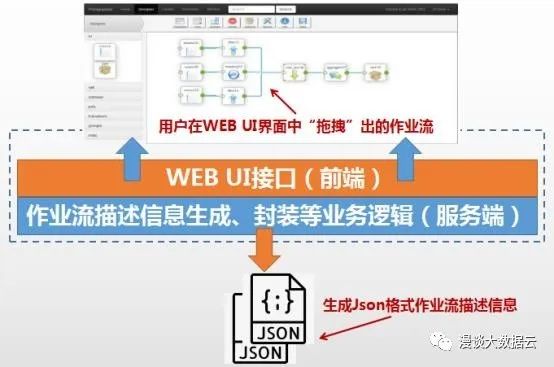
“数据开发”组件示意图
树叶长得再高,终将落叶归根。作业也亦是如此,我们已经知道作业流生长于海拔8848米的“数据开发”WEB界面中,但终将被调度到Hadoop等基础技术平台上来运行。在被调度到Hadoop平台之前它将经历什么样的风吹雨打呢?接下来要介绍的是全局调度功能模块,我们暂且将其命名为“集中调度”组件。简单描述“集中调度”就是,心中一本账,身后仨跟班。一本账是指,一个数据库记录着从“数据开发”传递过来的所有作业流的描述信息,“集中调度”对每个作业流的描述信息进行解析,生成具体的作业流执行计划与调度计划。这里为使架构设计更加合理,实现一个轻量级的“集中调度”组件,作业流中具体作业(例如Hadoop Yarn的计算作业)的生成与调度工作,不必由“集中调度”自身的业务逻辑来完成。“仨跟班”的意义便在于此,支持以插件化的形式,为“集中调度”安排“跟班”,“集中调度”依据具体的作业类型与调度接口,交由相应的“跟班”完成“最后一公里”的工作即可,以此,从架构方面,更好地支持多类型作业的集中调度。上文所说的“仨跟班”是指,对数据开发场景进行分类,支持数据采集、数据集成与数据挖掘三类作业调度的插件。例如,数据采集作业可直接依赖于自定义脚本方式实现,该脚本可能会被调度到大数据基础技术平台的K8S容器中执行,因此,这部分物理作业的组装生成与调度提交逻辑将由“数据采集”插件完成,“数据采集”插件作为“集中调度”组件的触手之一,以K8S客户端的身份与基础技术平台进行交互。再例如,假设我们设计数据集成与数据挖掘场景的部分算子是依赖于Spark计算框架的,包含这部分算子的物理作业将会被“数据集成”和“数据挖掘”插件组装、生成并提交至Hadoop平台执行,在此,两个插件同样是以Hadoop客户端的身份与基础技术平台进行交互。
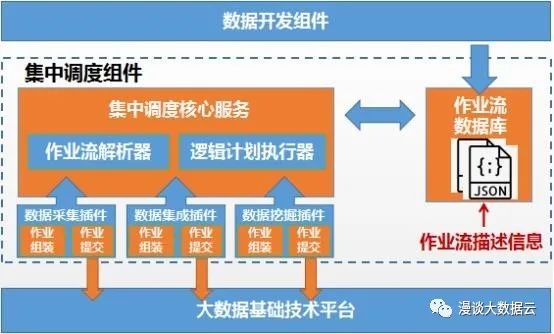
“集中调度”组件示意图
上文介绍了大数据应用平台是如何通过“数据开发”与“集中调度”两个核心组件来实现“一站式数据开发”能力的。总结来说,“数据开发”组件通过对用户提供WEB UI接口,以拖拽的形式,简化了用户在进行数据开发时的技术门槛。“集中调度”组件,以插件化的方式封装了相关算子与底层API接口,实现作业流在开发完成后,即可被“集中调度”组件按周期或可配置的触发条件调度至相应环境中,实现敏捷发布上线。
3、如何形成“企业级数据管理”能力?
接下来,我们将围绕“企业级数据管理”能力展开分析。“企业级数据管理”的本质是统一元数据管理。从企业数据管理与共享的需求角度来看,企业内的业务数据是否统一集中存储似乎并不重要,重要的而是能否找到一个支点,撬动(打通、共享)企业内的业务数据(注释1:这里“企业内业务数据”的说法范围过大,但为保证阅读连贯性,先与上文保持一致,后续文章给出解释),这个支点我们先定其名为“数据管理”组件。单从技术上讲,将企业内所有库表的元数据进行周期甚至实时同步至一个点上,进行统一元数据的存储、管理与应用并非难事。企业内授权用户,可通过这个点去查看整个企业的数据信息与数据分布等情况,进而去申请使用自己感兴趣的业务数据,以实现企业级数据共享(注释2:用户在申请使用目标数据时,并非一定要把其重新拷贝到本地,这样会造成企业数据冗余,带来管理不便的同时也增加存储硬件成本,后续文章给出一种数据共享的具体方案)。
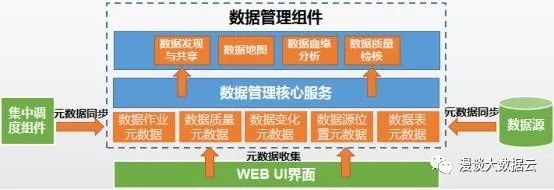
“数据管理”组件示意图
上文介绍的“企业级数据管理”的本质来看,其要解决的主要问题是如何将企业内所有库表的元数据进行统一收集、存储、管理和应用。下面,针对“数据管理”组件的本质,给出一种可行的设计思路。首先,“数据管理”组件也是直接面向用户的,需要自己独立的WEB UI接口。除此之外,它也需要记账,从基本功能(数据发现与共享)出发,需要两本核心账,分别记录不同种类的元数据。因为“数据管理”需要周期或实时同步企业内所有库表(后文简称为数据源)的元数据,所以第一本核心账要记录自己所辖范围内有所有数据源,即每个数据源的位置信息(IP地址+端口号+库名),该元数据可通过用户在UI界面上手动配置获取,我们称这个配置过程为“数据源注册”。知道了有哪些数据源之后,第二本帐,要记录的是每个数据源中所有表的元数据(例如表名、表字段,字段约束、字段描述以及表权限等描述信息),这本核心帐中的内容可从数据源中同步过来。“数据管理”组件基于上述两本核心帐,已为用户提供数据发现与共享的基本功能(基于元数据的一种应用),用户可通过查询元数据来找到自己感兴趣的业务数据,以及其所在的位置。
企业级的“数据管理”组件还应具备数据地图、血缘分析和数据质量管理等高级功能,这些功能的实现还需要依赖更多不同种类的元数据。功能虽高级,但实现思路和原理没有差别,依然是通过各种方式,收集功能相关的元数据信息,基于这些元数据进行应用开发。例如,数据地图功能需要第三本账,记录数据源中业务数据的移动和变化情况,该信息需实时同步给“数据管理”组件,以使用户可实时查询所有业务数据的分布情况。数据质量管理功能需要第四本张,分别从技术角度和业务角度记录数据质量规则的技术元数据和业务元数据,利用该元数据对数据源中的业务数据进行质量检核,质量规则元数据可通过用户根据业务需求自行配置获得。数据血缘分析功能需要第五本账,记录所有数据对象被加工处理的过程元数据。通过对数据作业的描述信息进行分析,可以找到以任何数据对象为起点的所有相关元数据对象以及这些元数据之间继承与生成关系,以形成数据血缘图谱。
“数据管理”组件的设计思路与实现原理,总体来讲,首先是要统一各方面元数据的存储于管理,进而再利用这些元数据实现数据发现、数据共享等基本功能,与数据地图、数据质量检核等高级功能。
4、初见大数据云平台
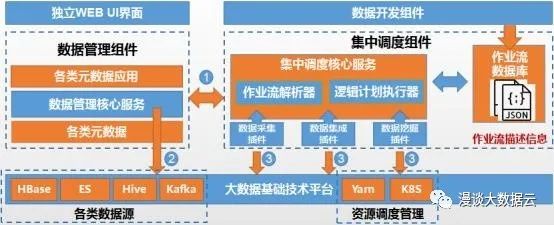
大数据云平台综合示意图
上图所示内容构成大数据云平台的基本架构,现对各组件间的交互(图中数字标号)进行简要描述。上图标号1,为“数据管理”与“集中调度”组件间的交互过程,第一类交互场景是源于“集中调度”组件需依赖“数据管理”组件的数据源权限信息,对不同用户(注释3:此处严格来说应为租户,为便于理解,本文先不涉及资源控制与隔离相关内容,仅从权限控制角度进行讲解,因此使用“用户”一词)的数据加工作业进行数据访问权限控制。例如,用户A有一个数据集成作业,该作业对Hive1数据源中T1表数据进行ETL处理,再将处理后的结果数据写入到Hive2数据源的T2表中,“集中调度”组件在生成此作业执行计划之前,会与“数据管理”组件进行交互,以验证用户A是否具备两个目标表的访问权限。第二类交互场景是指“数据管理”组件需依赖“集中调度”组件向自己实时同步数据采集与集成的作业信息,以保证任何数据源中的数据发生移动或变化时,“数据管理”组件都可实时获知。
上图标号2是指“数据源注册”的交互过程,用户将数据源的位置信息配置在“数据管理”组件中,以实现“注册”。注册后“数据管理”组件将以数据源客户端的身份与数据源进行交互。例如,一个Hive数据源进行“注册”后,即可在“数据管理”组件中对该Hive源进行建表等操作,该操作实质是由“数据管理”组件在程序中调用Hive提供的客户端接口实现的。
上图标号3的交互过程是指,“集中调度”组件的各插件,根据自身要提交的作业的类型,以相应客户端的身份与基础技术平台进行交互,交互原理与标号2相同。
从功能完整性方面考虑,大数据云平台除以上核心架构外,一般还具备统一的数据服务能力与可视化展示功能。数据服务将底层不同技术产品的多种数据访问接口进行封装,对外提供统一的SQL数据查询接口,以满足用户的数据查询与导出需求。数据可视化功能模块也可集成在大数据云平台中,以满足用户的一站式数据开发与结果展示需求。在进行交互设计时,数据可视化可依赖于数据服务,将需展示的结果数据进行查询并导出到本地。
结束语:
至此,读者应对大数据云平台的全貌有了直观认识,其实并没有想象的那么复杂与神秘。本文中多次提到了一个概念,即“云”平台,但一直未体现出“云”的意义。文章“领土”,将针对大数据云平台多租户资源隔离与控制进行专题介绍,讲述大数据平台被“云”化的过程。如您对本系列文章感兴趣,可扫描二维码关注公众号。






