




HBase(一)之架构概念及基础环境搭建
简介
HBase的原型是Google的BigTable论文,受到了该论文思想的启发,目前作为Hadoop的子项目来开发维护,用于支持结构化的数据存储。
官方网站:http://hbase.apache.org
2006年Google发表BigTable白皮书 2006年开始开发HBase 2008年北京成功开奥运会,程序员默默地将HBase弄成了Hadoop的子项目 2010年HBase成为Apache顶级项目 现在很多公司基于HBase开发出了定制版,比如阿里云HBase 总结:
HBase是构建在HDFS之上的分布式、面向列的存储系统,在需要实时读写、随机访问的超大规模数据集时,可以使用HBase。
关系型数据库(RDBMS)目前存在的问题
建表限定列数量,无法动态随意扩展 MySQL单表数据量500W左右,数量小 MySQL单表数据量过大时,横向切分(手动开发、复杂、稳定性低、效率低) MySQL单表的列过多,影响表的CRUD效率(MySQL单表列不能超过30个) MySQL单表的列过多,纵向切分(手动开发、复杂、稳定性低) MySQL数据库允许空值,空值的空间被占用(海量数据面前,空间浪费) MySQL数据库中每个单元格,只能保存一个值(一个版本)
为什么需要HBase
# 海量数据存储
支持单表百亿行、百万列(MySQL实战最大值500万行,30列)
# 实时查询
秒级、毫秒级读写
HBase特点
# 1. 容量大
HBase单表百亿行数据,百万列。
# 2. 面向列
HBase存储是面向列,可以在数据存在以后动态增加新列和数据,并支持列数据的独立操作。
# 3. 多版本
HBase每个数据,可以同时保存多个版本,按照时间戳去标记。
# 4. 稀疏性
HBase每条数据的增删,并不是要操作所有的列,列可以动态增加,可以存在大量空白单元格,不会占用磁盘空间,这对于海量数据来讲,非常重要。
# 5. 扩展性
底层使用HDFS,存储能力可以横向、纵向扩展。
# 6. 高可靠性
底层使用HDFS,拥有replication的数据高可靠性。
# 7. 高性能
表数据达到一定规模,HBase使用"自动分区",具备主键索引,缓存机制,使得HBase海量数据查询能达到毫秒级。
HBase和关系型数据库(RDBMS)对比
| HBase | 关系型数据库 |
|---|---|
数据库以region的形式存在 | 数据库以「Table」的形式存在 |
使用行键(row key) | 支持「主键」(Primary Key) |
| 使用行表示一条数据 | 一条数据用「row」代表 |
使用列 column、列族 column family | 「column」代表列数据的含义 |
使用HBase shell命令操作数据 | 使用「SQL」操作数据 |
| 数据文件可以基于HDFS,是分布式文件系统, 可以任意扩展,数据总量取决于服务器数量 | 数据总量依赖于单体服务器的配置 |
| 不支持事务、不支持ACID | 支持「事务」和ACID |
| 不支持表连接 | 支持「join」表连接 |
HBase表逻辑结构
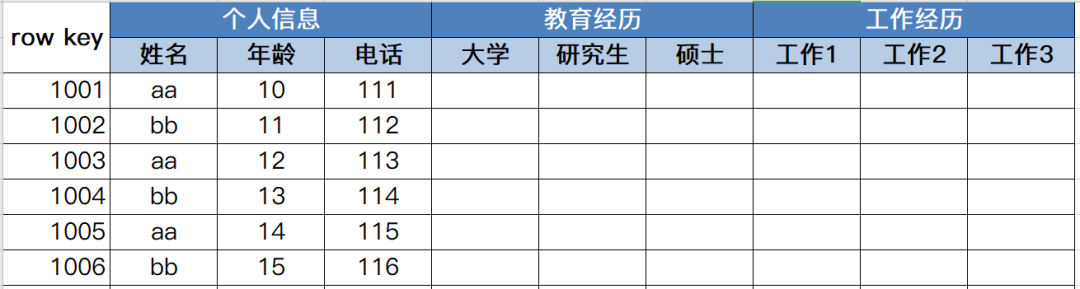
数据相关概念
# namespace 命名空间
hbase管理表的结构,相当于Database,在HDFS中对应一个文件夹
# table 表
hbase管理数据的结构,相当于table,在HDFS中对应一个文件
# column 列
列,每个列对应一个单元格
# column family 列族
包含多个列,一组拥有相关业务含义的列组成1个列族
表中数据的列,要属于某个列族,所有的列的访问格式(列族:列名)
# rowkey 主键
类似于id,用来标记和检索数据的主键key
# cell 单元格
rowkey+列族+列,唯一确定一条数据
# timestamp 时间戳
时间戳,每个单元格可以保存多个值,每个值有对应的时间戳,每个cell中,不同版本的数据倒序排序,排在最前面的是最新数据
HBase架构体系(物理结构)
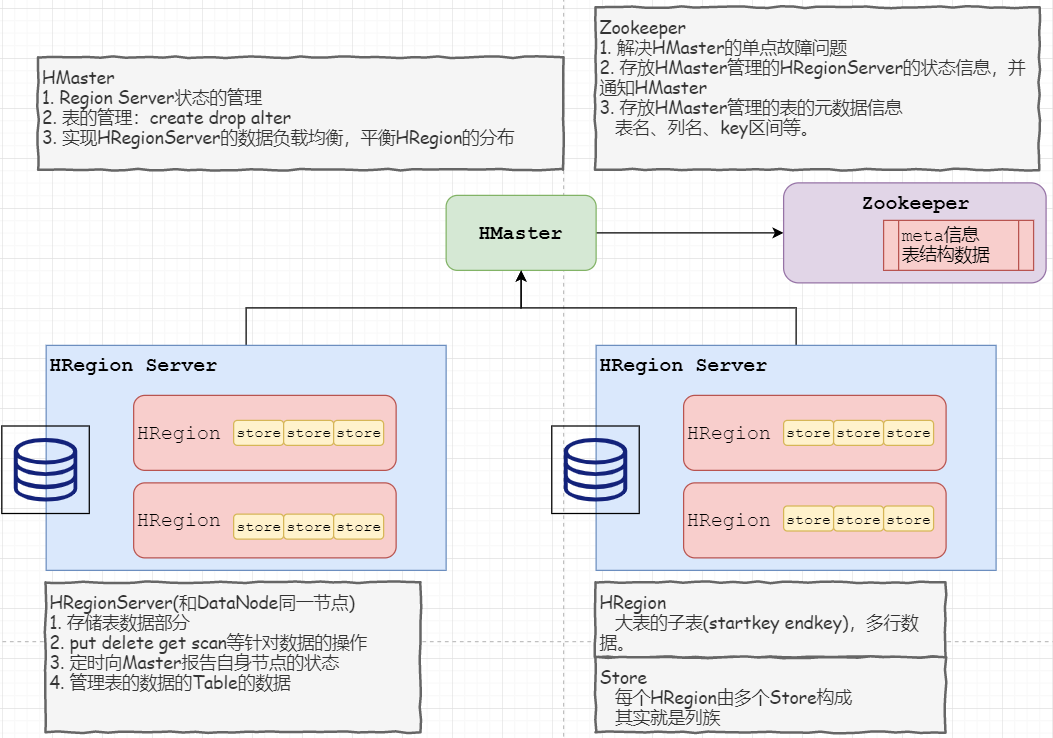
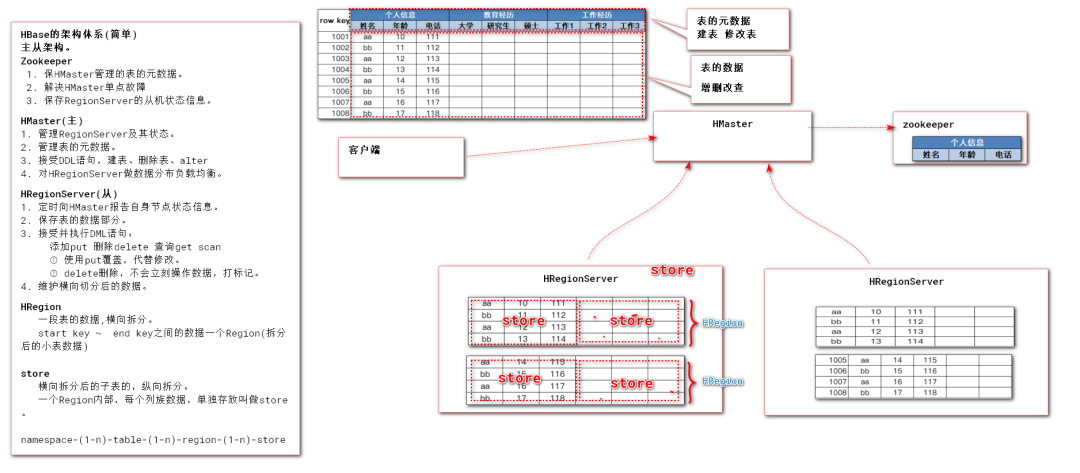
架构相关概念
「HRegionServer」
HRegionServer(和DataNode同一节点)
1. 存储表数据部分
2. put delete get scan等针对数据的操作
3. 定时向HMaster报告自身节点的状态
4. 管理表的数据的Table的数据
「HMaster」
HMaster
1. Region Server状态的管理
2. 表的管理:create drop alter
3. 实现HRegionServer的数据负载均衡,平衡HRegion的分布
「Zookeeper」
Zookeeper
1. 解决HMaster的单点故障问题
2. 存放HMaster管理的HRegionServer的状态信息,并通知HMaster
3. 存放HMaster管理的表的元数据信息
表名、列名、key区间等
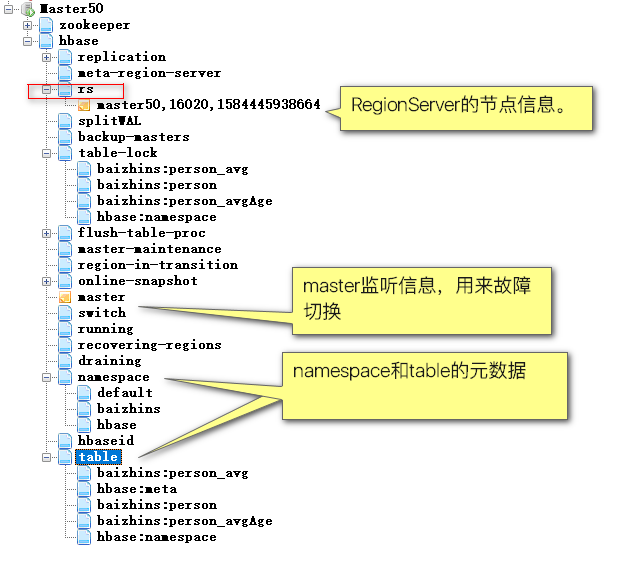
「HRegion」
HRegion
1. 表的横向切片的物理表现,大表的子表(startKey~endKey),多行数据。
2. 为了减小单表操作的大小,提高读写效率。
「Store」
Store
1. 表的纵向切分的物理表现,按照列族作为切分。
2. 按照列族查询,仅需要检索一定范围内的数据,减少全表扫描。
HBase单机版安装
下载
地址:https://mirrors.tuna.tsinghua.edu.cn/apache/hbase/
准备
安装并配置hadoop [root@hbase30 installs]# jps
3440 Jps
3329 SecondaryNameNode
3030 NameNode
3134 DataNode
安装并配置zookeeper [root@hbase30 installs]# jps
3329 SecondaryNameNode
3509 QuorumPeerMain
3030 NameNode
3595 Jps
3134 DataNode
[root@hbase30 installs]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/installs/zookeeper3.4/bin/../conf/zoo.cfg
Mode: standalone
设置日期同步(当HBase主机时间和网络时间不一致时需要设置) # 查看linux系统时间
[root@hbase30 installs]# date
# 重启chronyd服务,同步系统时间。
[root@hbase30 installs]# systemctl restart chronyd
[root@hbase30 installs]# date
2021年 11月 16日 星期二 19:23:10 CST
安装
# 1. 安装hbase
1. 解压HBase
[root@hbase30 modules]# tar zxvf hbase-1.5.0-bin.tar.gz -C /opt/installs/
2. 配置环境变量
#JAVA
export JAVA_HOME=/opt/installs/jdk1.8
export PATH=$PATH:$JAVA_HOME/bin
# HADOOP
export HADOOP_HOME=/opt/installs/hadoop2.9.2/
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# zookeeper
export PATH=$PATH:/opt/installs/zookeeper3.4/bin/
# HBase
export HBASE_HOME=/opt/installs/hbase1.5
export PATH=$PATH:$HBASE_HOME/bin
3. 加载profile配置
source /etc/profile
# 2. 初始化配置文件
# 1 -------------------hbase-env.sh--------------------
# 配置Java_home
export JAVA_HOME=/opt/installs/jdk1.8
# 注释掉如下2行
# export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m -XX:ReservedCodeCacheSize=256m"
# export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m -XX:ReservedCodeCacheSize=256m"
# 禁用内置zookeeper
export HBASE_MANAGES_ZK=false
# 2. -------------------hbase-site.xml-------------------------
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hbase30:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hbase30</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/installs/zookeeper3.4/data</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>
# -------------------配置regionservers(regionserver所在节点的ip) -------------------
hbase30
# 3. 启动hbase
1. 启动HMaster
[root@hadoop10 installs]# hbase-daemon.sh start master
# 关闭
[root@hadoop10 installs]# hbase-daemon.sh stop master
2. 启动HRegionServer
[root@hadoop10 installs]# hbase-daemon.sh start regionserver
# 关闭
[root@hadoop10 installs]# hbase-daemon.sh stop master
# 4. 验证访问
1. java进程查看
[root@hbase30 installs]# jps
4688 NameNode
5618 HMaster
5730 HRegionServer
4819 DataNode
3509 QuorumPeerMain
6150 Jps
4984 SecondaryNameNode
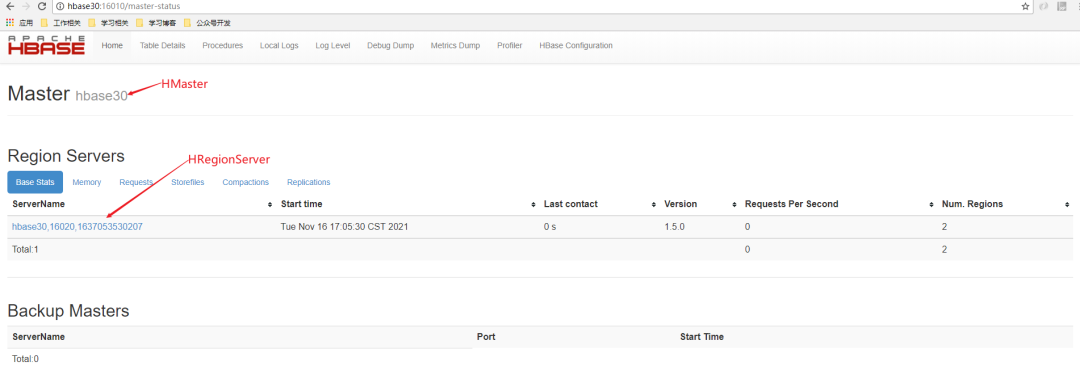
2. HMaster WebUI查看
http://ip:16010
3. 进入客户端
hbase shell
hbase(main):001:0>


文章转载自第二范式,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
