




前言
表膨胀的原理和危害,想必各位已经十分熟悉,相反,索引膨胀各位可能就相对生疏,今天让我们聊一聊索引膨胀。
索引膨胀
索引和表类似,随着不断的增删改也会膨胀,因为索引中还引用了表中不可见的死元组,索引分裂、合并导致的碎片等等。
另外索引页的复用机制和堆表也不一样,比如 Btree,因为索引的内容是有序的,只有符合顺序的条目才能插入到相应的页面中,因此索引也需要定期检查膨胀率并进行重建。当然社区也在每个版本中针对索引膨胀的问题进行完善,比如
- 当索引扫描遇到指向表中死元组的条目时,会标记为 “killed”,后续的索引扫描会跳过这些条目
- 12 版本引入的 reindex concurrently 和 pg_stat_progress_create_index 视图,另外 The maximum size of an item that can be indexed using btree has decreased by 8 bytes!
 

-
13 版本引入的 deduplication ,借鉴了GIN 索引的做法,将相同的 Key 指向的行的 CTID 链起来
-
14 版本引入的 bottom-up index deletion,在索引页即将分裂之前删除指向死元组的索引条目,避免分裂

这也让我想起了之前学徒 ① 群有位朋友提到的案例,即删完数据的空间 vacuum 之后不能有效复用,空间一直上涨,版本是 12.8,操作如下👇🏻
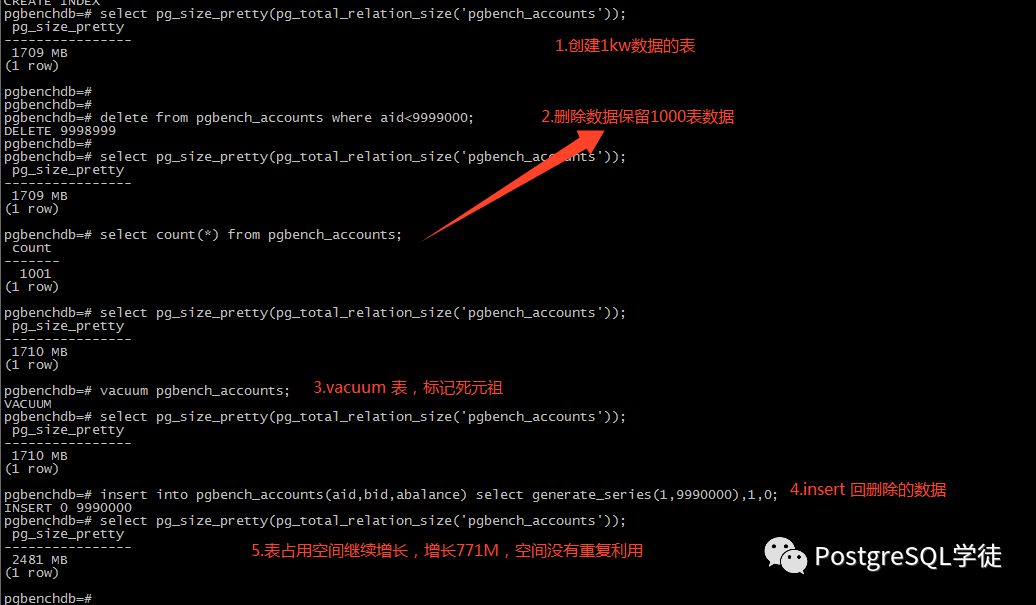
原因想必各位已经清楚,其实严格来说,PostgreSQL 从 13 版本以后索引的膨胀问题才算得到了大幅改善,各位可以实测一下 12 和 14 版本的差异,十分明显,这也是为什么要升级的原因之一。
虽然社区一直针对索引膨胀的问题进行修复,但是这并不能根治,因为索引结构也注定这个问题是无法避免的,因此我们还是需要定期巡检并及时重建索引。但是,如何衡量索引的膨胀率?何时做?怎么做?这一系列的问题想必也困扰着我们,此处推荐一个工具——pg_index_check,自动处理与重建索引。
Utility for automatical rebuild of bloated indexes (a-la smart autovacuum to deal with index bloat) in PostgreSQL.
Uncontrollable index bloat on frequently updated tables is a known issue in PostgreSQL. The built-in autovacuum doesn’t deal well with bloat regardless of its settings. pg_index_watch resolves this issue by automatically rebuilding indexes when needed.
该工具纯 SQL 开发,由于基于 reindex concurrently 实现,所以要求版本是 12 以上,使用很方便,配合定时任务,比如:
00 00 * * * psql -d postgres -AtqXc "select not pg_is_in_recovery();" | grep -qx t || exit; psql -d postgres -qt -c "CALL index_watch.periodic(TRUE);"
这样便会每天午夜自动执行索引重建,不过建议和 pg_dump 等维护性操作错开,重建的历史会记录在 history 表中。
小试牛刀
让我们简单测一下
postgres=# create table test_bloat(id int,info text);
CREATE TABLE
postgres=# create index on test_bloat(id);
CREATE INDEX
postgres=# create index on test_bloat(info);
CREATE INDEX
postgres=# insert into test_bloat select n,md5(random()::text) from generate_series(1,10000000) as n;
INSERT 0 10000000
postgres=# delete from test_bloat where id < 5000000;
DELETE 4999999
调用一下
[postgres@xiongcc pg_index_watch]$ nohup psql -d mydb -qt -c "CALL index_watch.periodic(TRUE);" >> index_watch.log nohup: ignoring input and redirecting stderr to stdout [postgres@xiongcc pg_index_watch]$ psql -1 -d mydb -c "SELECT * FROM index_watch.history LIMIT 20" ts | db | schema | table | index | size_before | size_after | ratio | tuples | duration ---------------------+----------+--------+------------------+-----------------------+-------------+------------+-------+---------+---------- 2023-09-06 16:34:11 | postgres | public | test_bloat | test_bloat_info_idx | 729 MB | 282 MB | 2.59 | 4861 kB | 00:00:42 2023-09-06 16:34:01 | postgres | public | test_bloat | test_bloat_id_idx | 214 MB | 107 MB | 2.00 | 4903 kB | 00:00:08 2023-09-06 16:33:26 | postgres | public | pgbench_accounts | pgbench_accounts_pkey | 214 MB | 214 MB | 1.00 | 9766 kB | 00:00:25 (3 rows)
可以看到,会很清晰地记录重建过程。其它更多使用方法各位读者就自行探索吧。
小结
索引膨胀的危害和表膨胀危害类似,会导致缓冲区利用率下降,增加规划时间,影响写入性能等,所以也同样需要关注,pg_index_check 可以自动化管理与重建膨胀索引,当然也是采用 reindex concurrently,类似 CIC,所以也可能会留下无效索引。
参考
https://github.com/dataegret/pg_index_watch
