





点击上方蓝字关注我们

01
Hadoop体系虽然在目前应用非常广泛,但架构繁琐、运维复杂度过高、版本升级困难,且由于部门原因,数据中台需求排期较长,我们急需探索敏捷性开发的数据平台模式。在目前云原生架构的普及和湖仓一体化的大背景下,我们已经确定了将Doris作为离线数据仓库,将TiDB(目前已经应用于生产)作为实时数据平台,同时因为Doris具有 on MySQL 的odbc能力,所以又可以对外部数据库资源进行整合,统一对外输出报表
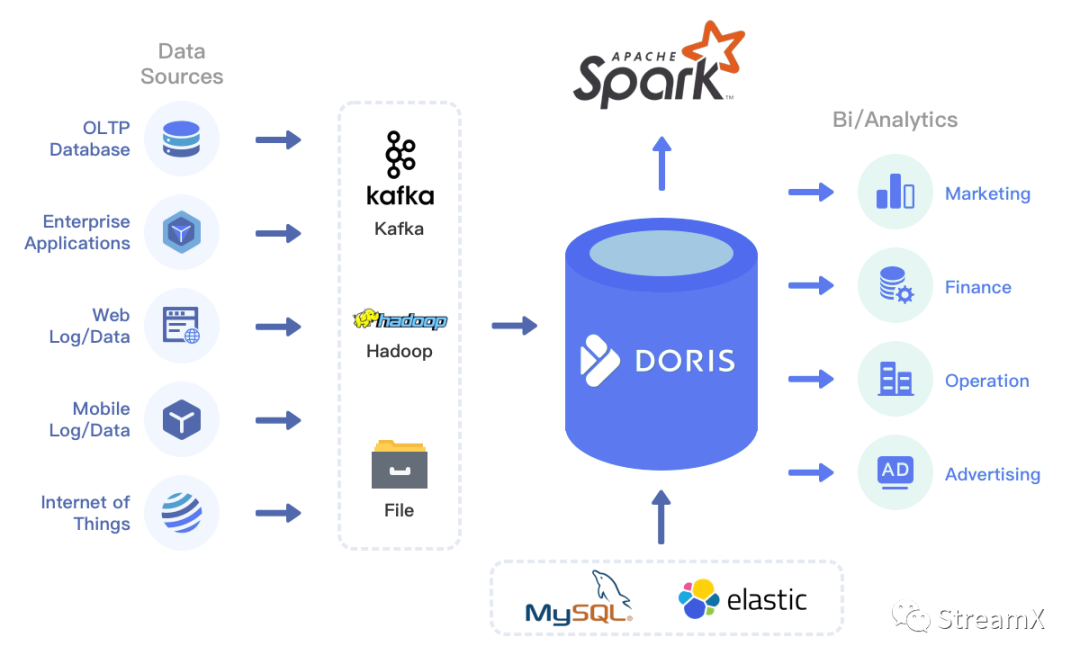
使用Spark on K8s client 客户端模式做离线数据处理 使用Flink on K8s Native-Application/Session 模式做实时任务流管理
任务运行监控怎么处理? 使用Cluster模式还是Nodeport暴露端口访问Web UI? 提交任务能否简化打包镜像的流程? 如何减少开发压力?
03
以上的这些其实都是需要解决的问题,如果单纯的使用命令行去提交每个任务,是不现实的,任务量大了,会变得不可维护。如何解决这些问题变成一个不得不面对的问题。

简化镜像构建

引入低代码平台StreamX
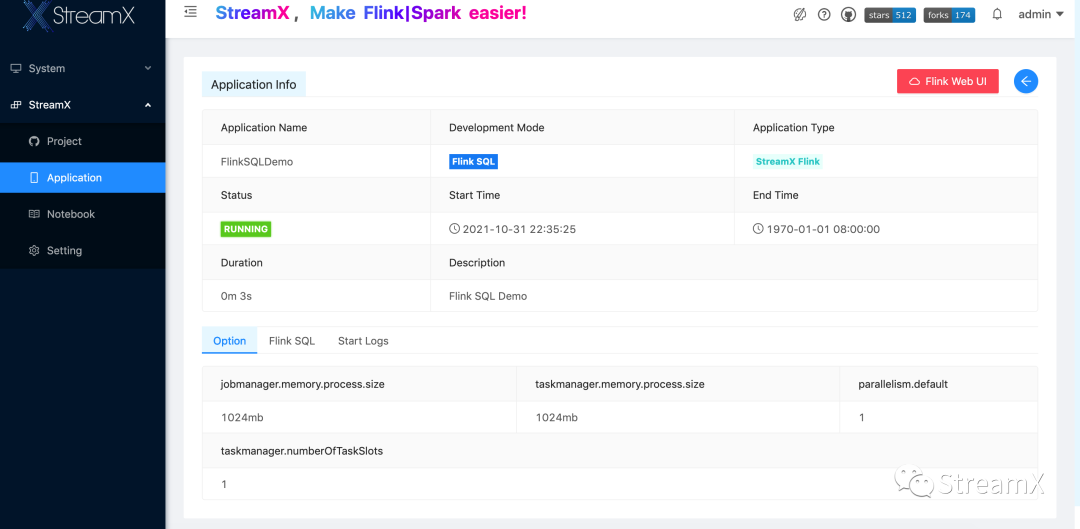
完善的Sql校验功能 实现了自动build/push镜像 使用自定义类加载器,通过Child-first 加载方式 解决了YARN和K8s两种运行模式、支持了自由切换Flink多版本 与Flink-Kubernetes进行深度整合,提交任务后返回WebUI,通过remote rest api + remote K8s ,追踪任务执行状态 同时支持了Flink1.2、1.3、1.4等版本
(StreamX K8S部署演示视频)
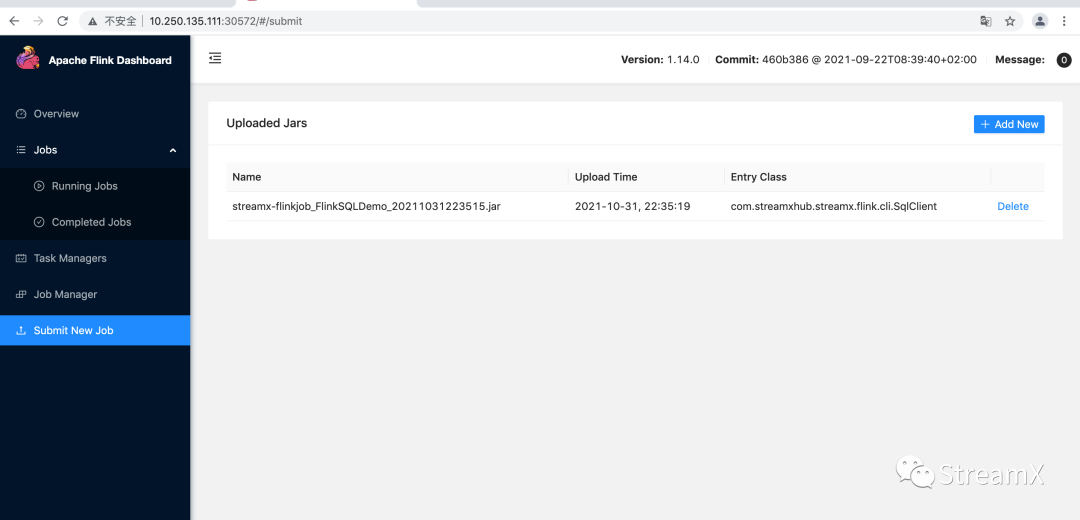
K8s Native Application 模式
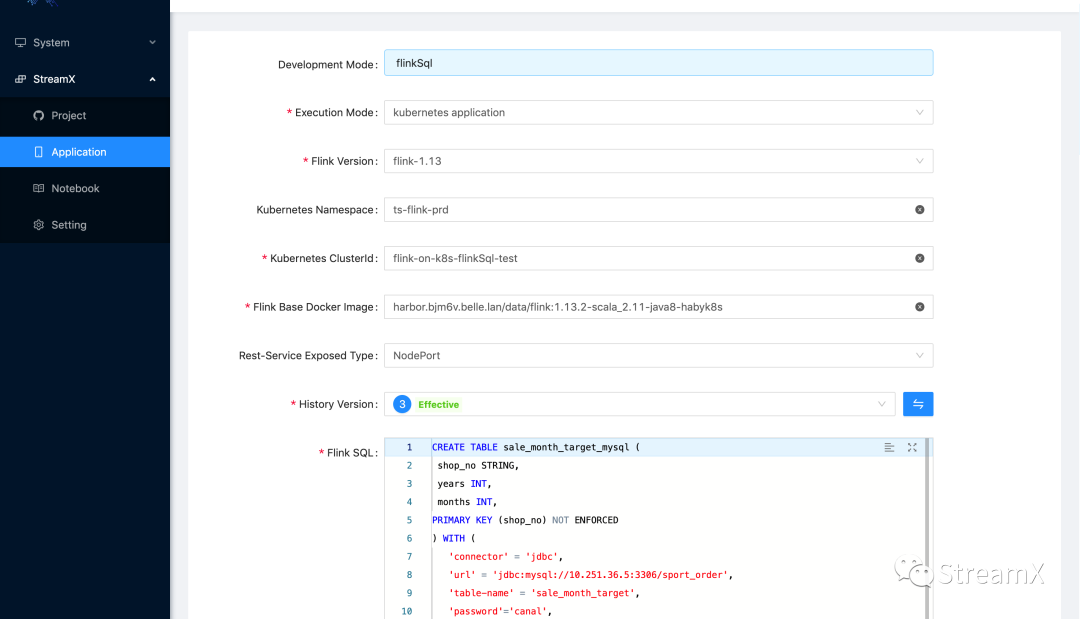
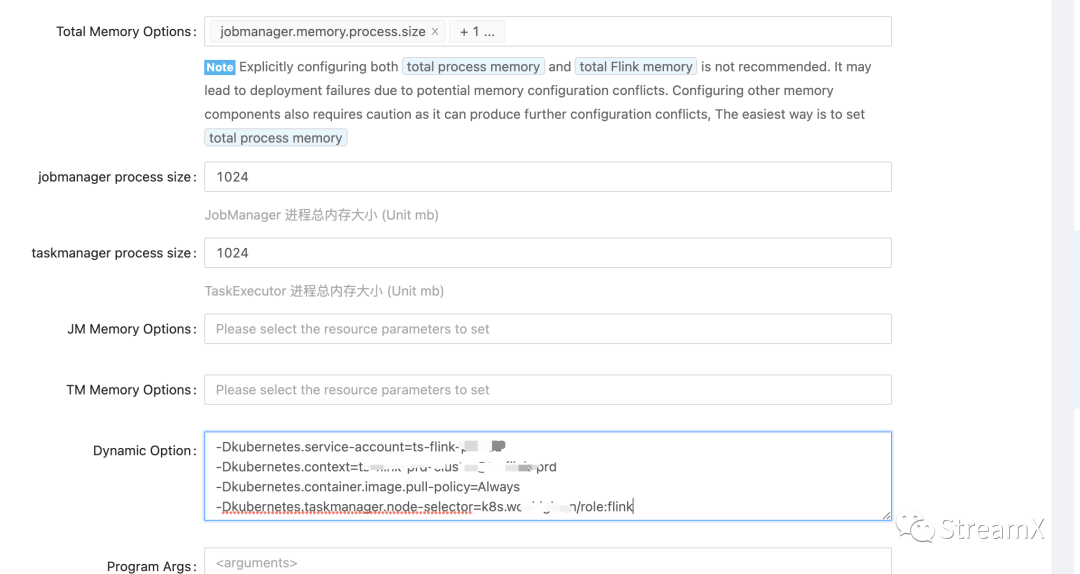
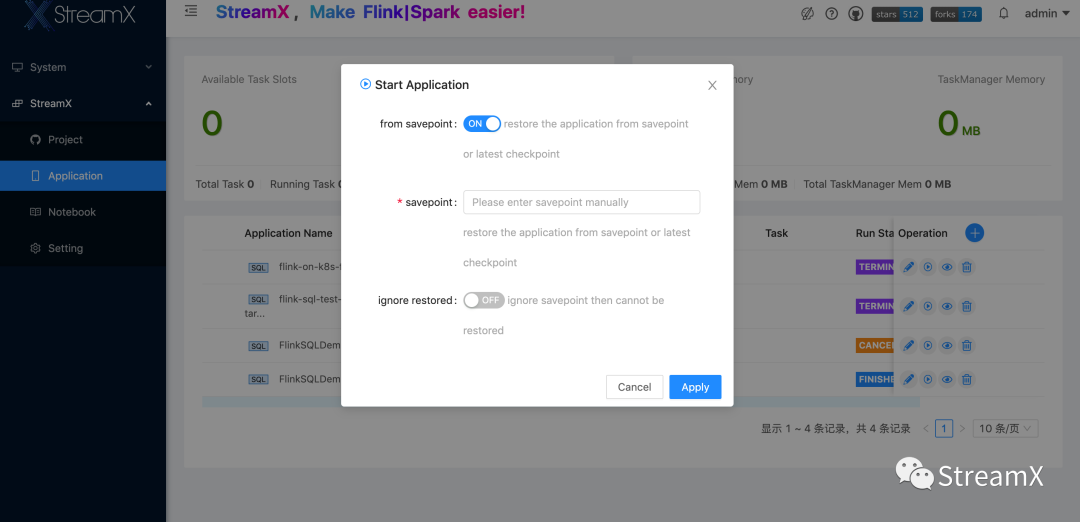
下面是K8s Application模式下具体提交流程
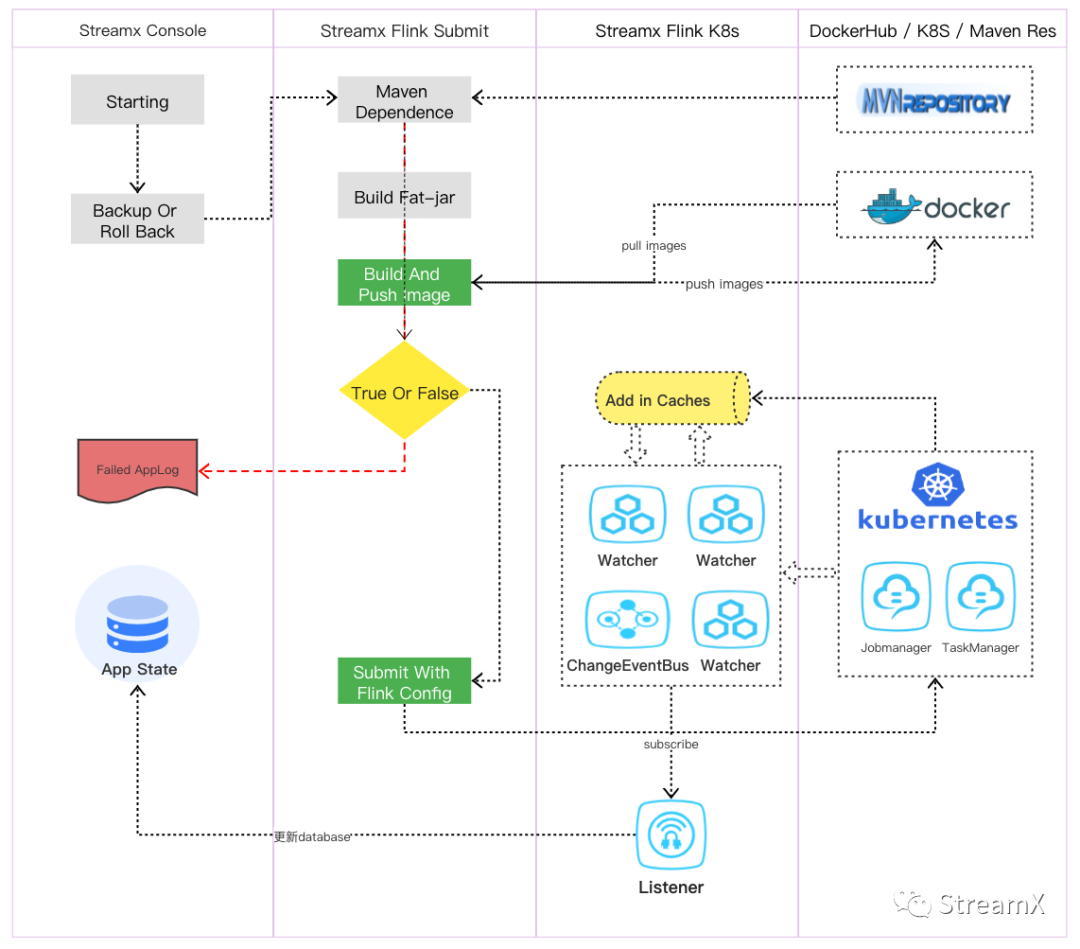
(以上是依据个人理解绘制的任务提交流程图,如有错误,敬请谅解)
K8s Native Session 模式
./kubernetes-session.sh \-Dkubernetes.cluster-id=flink-on-k8s-flinkSql-test \-Dkubernetes.context=XXX \-Dkubernetes.namespace=XXXX \-Dkubernetes.service-account=XXXX \-Dkubernetes.container.image=XXXX \-Dkubernetes.container.image.pull-policy=Always \-Dkubernetes.taskmanager.node-selector=XXXX \-Dkubernetes.rest-service.exposed.type=Nodeport
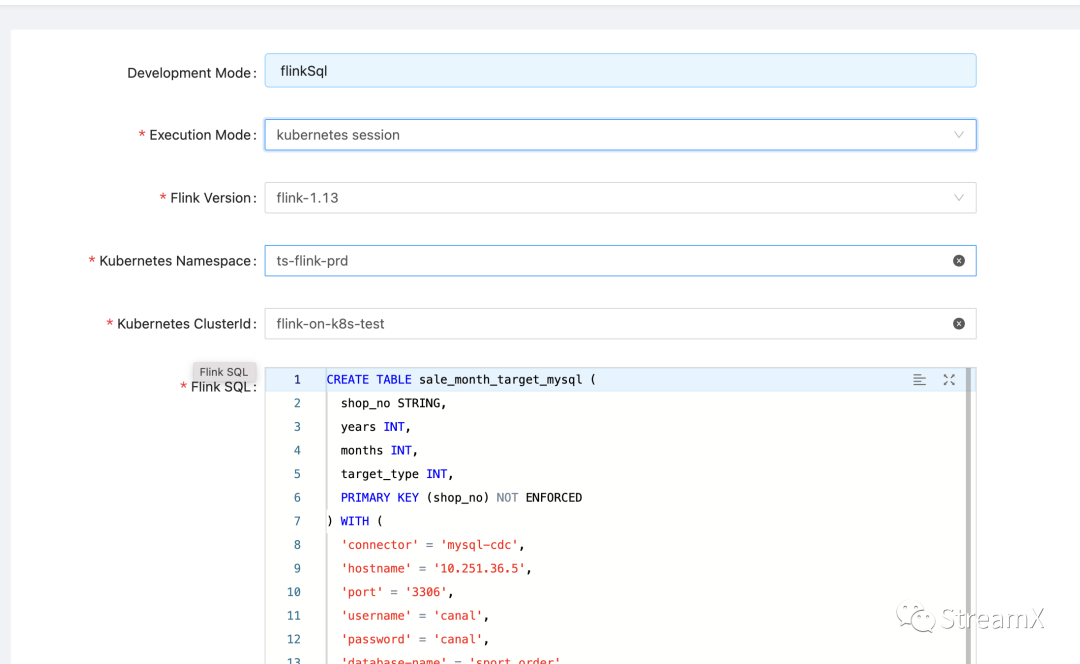
Custom Code模式
04
改进意见
资源管理还有待加强 多文件系统jar包等资源管理功能尚未添加,任务版本功能有待加强。 前端buttern 功能还不够丰富 比如任务添加后续可以增加复制等功能按钮。 任务提交日志也需要可视化展示 任务提交伴随着加载class文件,打jar包,build镜像,提交镜像,提交任务等过程,每一个环节出错,都会导致任务的失败,但是失败日志往往不明确,或者因为某种原因导致异常未正常抛出,没有转换任务状态,用户会无从下手改进。
未来规划
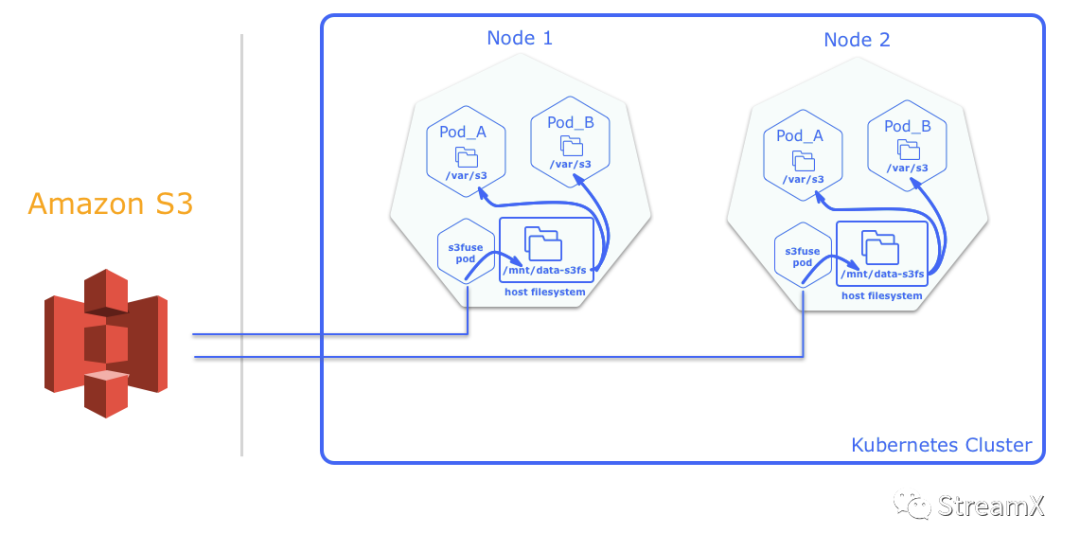
我们会继续跟进doris,并将业务数据 + 日志数据统一入doris,通过Flink实现湖仓一体; 我们也会逐步将探索StreamX同dolphinscheduler 2.x进行整合,完善dolphinscheduler离线任务,逐步用Flink 替换掉Spark,实现真正的流批一体; 基于我们自身在s3上的探索积累,fat-jar包 build 完成之后不再构建镜像,直接利用Pod Tempelet挂载pvc到Flink pod中的目录,进一步优化代码提交流程; 将StreamX持续应用到我们生产中,并汇同社区开发人员,共同努力,增强StreamX在Flink流上的开发部署能力与运行监控能力,努力把StreamX打造成一个功能完善的流数据 DevOps。

往期推荐
end

点个在看你最好看
文章转载自 锋哥聊DORIS数仓,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
