




He3DB 是由移动云数据库团队研发的一款计算/存储分离的云原生数据库,He3DB通过计算/存储分离、数据冷热分层和压缩、智能中间件等技术,来保证高性能和低成本完美兼得,在获得高性能的同时,最大化的帮助客户节省数据库使用成本。
He3DB 在研发之初团队研读了大量云原生数据库相关论文,包括Aurora、PolarDB、Socrate、Taurus等发布的相关论文,通过论文我们能学习到各厂家关于云原生数据库的理解、实践时所要解决的问题、以及其产品设计的核心理念,这对He3DB 产品的设计、工程实践等启到有效的指导作用。因此为帮助更多人了解、学习云原生数据库的知识,团队推出本专栏,将分期解析云原生数据库领域的经典论文。
本期分享论文为:PolarDB Serverless: A Cloud Native Database for Disaggregated Data Centers
引言
云原生数据库PolarDB核心理念
首先谈谈我们对PolarDB设计理念的理解,如有不对欢迎批评指正。通过上期对Aurora论文的解读,我们了解到Aurora研发启动时间相对较早,他们认为云环境下网络是数据库发展的瓶颈,因此创新性提出 “Log is database” 的理念(He3DB 也是基于此理念设计开发),通过减少网络传输的数据量以提高数据库读写性能。
而PolarDB研发之初是新兴硬件爆发期,如RDMA、SPDK等,PolarDB积极拥抱新硬件,打造了高性能存储引擎PolarStore、高速网络通道,他们认为在新硬件加持下网络传输不再是数据库系统发展的瓶颈,老旧的操作系统不能发挥新硬件的优势而成为瓶颈点,因此做了大量系统内核、文件系统的优化改造,以达到极致性能。
Serverless
为帮用户节省成本,Serverless成为各产品演进中的必要一环,但要做好Serverless并非易事;我们可以将云数据库发展分为三个阶段:云托管1.0时代、云原生2.0时代、Serverless 3.0时代。云托管1.0主要实现将传统数据库搬迁上云,提供服务,其弹性伸缩以单机为粒度,无法对存储、计算资源单独扩容,会造成一定资源浪费;云原生2.0时代,将数据库设计与云基础设施融合实现存算分离,能对存储与计算资源分别扩缩容,而今天介绍的论文中PolarDB进一步解耦,依靠高速硬件加持对计算层进一步解耦,实现CPU、内存、存储的三层解耦架构,各层能分别动态扩缩,具有极大的灵活性,更好的节省用户使用成本,下面让我们一起看看PolarDB如何实现这一架构设计及面临的问题困难。
论文解读
INTRODUCTION
论文简介部分,首先通过横向对比引出三层解耦架构,如下三幅图。
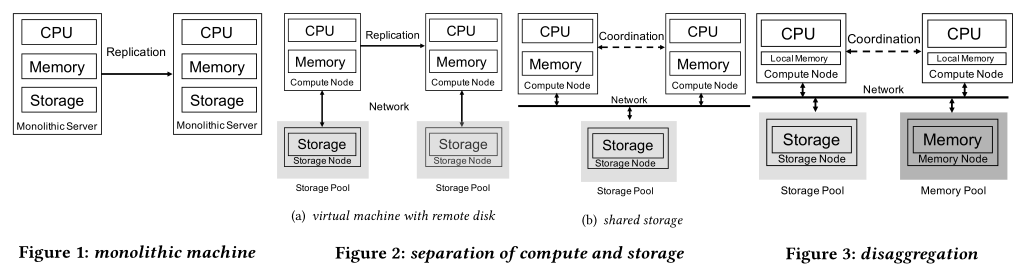
这种架构下将内存池化形成共享内存池,内存池中统一维护Page数据的生命周期,比如新增只读节点时只需扩展CPU资源,不会造成内存资源的线性扩展;三层之间通过网络连接通信,好处显而易见,但这种架构也带来一些挑战:
- 如何保证数据的正确性
(1)当内存池中数据页更新时需保证各计算节点本地缓存的数据页失效,保证各节点读到最新的数据页(使用全局缓存失效机制保证);
(2)读写节点在更新索引页时,保证其他读节点不能查看到中间结果(通过全局锁保证);
(3)多节点间通过同步ReadView,避免读节点读取到未提交事务所写的页;
- 如何保证数据库性能
(1)通过优化RDMA、计算下推等措施,解决网络延迟带来的性能下降;
- 如何保证系统的高可用
(1)解耦的同时带来系统运维的复杂性,文中各资源节点都具备独立容灾能力,从而避免因单点故障引起整个系统的崩塌。
BACKGROUND
本章节首先回顾了PolarDB的架构设计及各组件的交互流程,如下图所示,相信了解PolarDB的同学并不陌生,这里简述下流程,PolarDB按组件可以分为四层:
-
代理层(Proxy)
作为客户端链接的统一入口,主要实现读写分离、负载均衡等能力;
-
计算层(读写/只读节点)
一写多读架构,分为读写与只读节点,只读节点可以横向扩展;
-
文件系统层(PolarFS)
在分布式存储只上构建统一的文件操作接口供计算层使用;
-
高性能存储(PolarStore)
分布式存储;
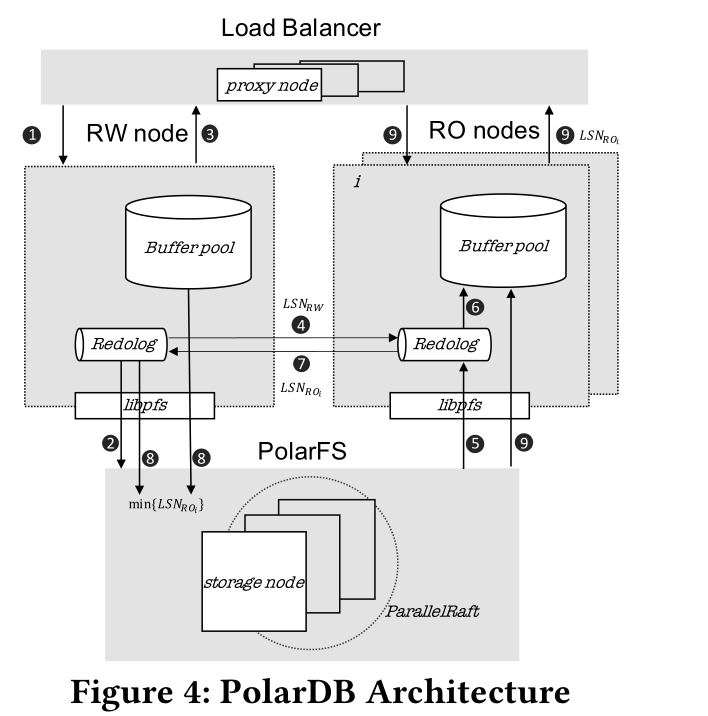
图中把PolarFS与PolarStore做了合并,所述流程大致为:
(1)Proxy接收SQL写请求,转发至读写节点处理;
(2)读写节点生成redolog并将日志持久化到存储层;
(3)返回给客户端,SQL执行成功;
(4)将日志序列号(LSN)同步给只读节点;
(5)从PolarFS读取最新的redolog;
(6)在Bufferpool中回放日志生成数据页;
(7)只读节点将当前以回放的LSN信息返回给读写节点;
(8)读写节点可以根据所有只读节点的最小LSN信息发起清理PolarFS中redolog的操作,并且将BufferPool中最小LSN之前的脏页刷至PolarFS;
(9)只读节点接收读请求后,若Bufferpool中没有所需的数据页则从PolarFS中读取并返回客户端;
其次介绍了DDC(Disaggregated Data Center),大致讲解了阿里云可以依靠RDMA构建出高速低延迟的数据中心,并讲解了数据中心的拓扑结构以及部署规划等,这部分不是重点,不做过多说明,感兴趣的可以查看原文。
论文正是基于以上架构进行演进,进一步对计算层解耦,引入共享内存池设计,形成三层解耦架构,具备更好的扩展性。
DESIGN
内存池的挑战
引入分布式共享内存,虽然能有效提高内存利用率、节省内存成本,但不可避免的带来性能、一致性方面的问题:
(1)虽然有RDMA加持,但相对本地内存,远程内存带来的网络开销更大;
文中是通过本地内存缓存和数据预取技术解决,后续具体说明。
(2)原读写、只读节点各自维护的Page数据被存放到共享内存池中,需要有跨节点的互斥的机制保证读写一致性;
文中通过RDMA CAS、乐观锁等减少对全局锁的使用,以提升性能;
(3)频繁刷脏会造成网络带宽压力过大
文中通过写日志到存储层,存储层内生成数据页,避免刷脏操作(log is database思想)。
内存池管理
在介绍内存池如何存储、管理数据页前先介绍几个概念:
- slab:内存分配的基本单位,大小1G;
- Page Array(PA):slab由PA组成,PA是一块地址连续的内存,包含多个16KB的数据页,节点启动时,存放PA的内存地址都会注册到RDMA网卡上,所以存储在PA中的数据页可以通过RDMA被计算节点访问;第一个slab所在的节点也被成为home node,home node相对于其他节点会额外存储一些元数据信息;
- Page Address Table(PAT)
PAT是一个hash表,用来存储每个数据页的位置(slab node id和物理地址)以及每个页的引用计数; - Page Invalidation Bitmap(PIB)
一个位图,对于PAT的每条数据,都会对应一个PIB,0表示内存池中的该页是最新版本,1表示读写节点在本地缓存中更新了该页并且还没更新至远程存储中,因此不是最新版本。对于每个只读节点都会有一个本地的PIB来表示RO节点上的本地缓存是否是过期; - Page Reference Directory(PRD)
也是一个映射表,对PAT表每条数据,都会保存一个记录节点列表,表示这些节点已经获得了Page的引用,即曾经使用page_read来把页缓存到该节点的本地缓存中,PIB和PRD来共同实现缓存一致性; - Page Latch Table(PLT)
对PAT每每条数据管理一个对应Page Latch(PL),PL是一个全局物理锁,用于跨节点的读写并发控制,专门用于B+ tree的并发控制,保证所有节点都是访问同一个状态,而不会观察到中间状态。
有以上铺垫后再看内存池中分配Page的过程就容易许多:
(1)数据库的进程向home node发送page_register请求,请求会注册到PAT中;
(2)如果页面不存在,则home node负责遍历所有现存的slab来找一个空闲区域最大的slab。如果所有slab都没有空闲区域了,会找那些引用计数为0的Page来淘汰掉,淘汰算法采用LRU;
(3)写入后,把page位置信息记录到PAT,并且返回page的远程地址和PL;
内存池扩缩容的时候,对应的操作:
-
扩容
home node请求DBaaS(管控平台)分配新的slab,扩展实例的buffer pool大小、PAT、PIB和PRD;
-
缩容
Page通过LRU进行淘汰,无用的slab被垃圾回收。
本地缓存管理
因访问共享内存池需要额外的网络开销,相对访问本地内存性能会下降,同时可能导致CPU可能会陷入busy wait等待数据从网卡读取至CPU的cache line,所以有必要将page数据缓存到本地内存,同时论文中给出本地内存的大小设置公式: min{ 1/8∗Size(remote_memory), 128 GB},这种设置下能得到较好的性能。
如果要访问的数据页不在内存池上,进程实例会直接通过libpfs接口从PolarFS读取数据页到本地缓存,然后通过librmem接口写到远程内存,存储节点和内存节点不会发生直接的交互。当然也不是所有从存储层读取的数据页都要写入到内存层,例如全表扫,加载的数据页被再次访问的可能性不大,反而会影响其他热点数据造成缓存效果下降。
为提高本地内存的命中率,预取策略是一种有效的手段,论文中提出名为Batched Key PrePare(BKP)的方法,核心是从解耦合的内存池、存储层预读取Page来减少远程网络IO。具体原理如下示例:
select name, address, mail from employee where age > 17
age字段存在二级索引,其余字段必须从主键索引拿数据,MySQL执行该query的时候,典型的过程是首先从二级索引扫描哪些符合条件的一级索引,然后去读基表;根据主键索引读基表是一个随机读的过程,可以用BKP来进行优化。BKP在存储引擎层实现,接口会接受预取时的一组key,当调用接口的时候,存储引擎会后台启动一个预取任务,从内存池层或存储层获取数据,更详细的流程论文并没有提到。
同样当本地缓存写满后也是通过LRU进行淘汰,没有修改过的数据页可以直接释放;而修改过的数据页则需要被回写到内存层才能被释放,同时还要注意清除该页的引用计数。
缓存一致性
在PolarDB中每个数据库进程的buffer pool只有该进程能够访问。只读节点不能够直接访问读写节点buffer pool上的最新数据,只能通过获得最新的redo log然后通过在自己的buffer pool中回放才能得到读写节点修改过后的数据。
而在本文的PolarDB Serverless中,读写节点可以把修改后的数据写回到远程的内存池,只读节点就不需要回放redo log来获取最新数据了。但是如果每次修改数据后都把数据页传回远程内存池,这会增大网络传输的开销,因此读写节点的改动会先缓存在本地内存,不会马上同步到远程的内存层。若读写节点修改了本地缓存,那么只读节点如何知道自己的本地缓存对应的page已经失效了呢?即如何维护多节点之间本地缓存的一致性?
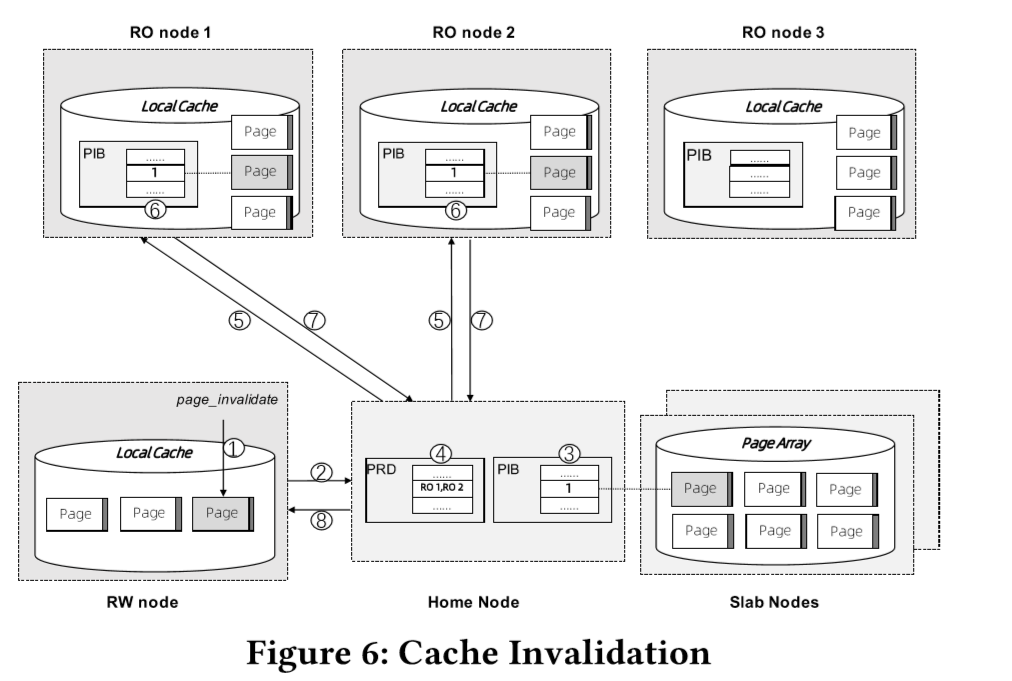
文中给出了如上图流程的解法:
(1)当读写节点修改本地缓存的page后,调用page_invalidate接口;
(2)将信息发送给Home node;
(3)在PIB中将page对应位设置为1,表示该page数据已在读写节点本地修改还未同步至内存池中;
(4)根据PRD引用信息,获取哪些只读节点本地缓存中存在此page数据;
(5-7)向这些只读节点发送请求,将节点内的PIB对应该page的位置为1,表示页失效;只读节点设置PIB位的操作是一个阻塞操作,当所有节点操作完毕才返回成功,如果有只读节点响应超时,则由DBaaS平台负责将超时节点剔除集群,从而保证操作成功;
(8)所有操作成功后,返回接口响应。
另外为保证事务的一致性,PolarDB中事务会被划分为多个mini-transactions(MTR),每个MTR由一组连续的redo log记录组成。因此每次MTR中的redo log要flush到PolarFS的时候,就需要使用page_invalidate设置MTR中的修改的Page数据在本地缓存过期。
Page Materialization Offloading
为解决刷脏造成的读写节点或内存节点与PolarFS之间大量的网络IO开销,文中参考“Log is database”的思想,将数据页回放过程下推,参考微软Socrates的实现将日志和数据页分开存储在不同的chunk中,首先把redo log持久化在log chunks内,然后异步发送至page chunks,并将logs回放更新page数据。
与Scorates不同的是,为了尽可能重用PolarFS中的组件和最小化改动,logs只发送到存储leader节点的page chunk中,leader节点完成page的回放并且通过Parallel Raft达成多副本中data chunks的一致性,虽然以上操作方式会额外增加时延,但这不是主要的流程,而且是异步操作。
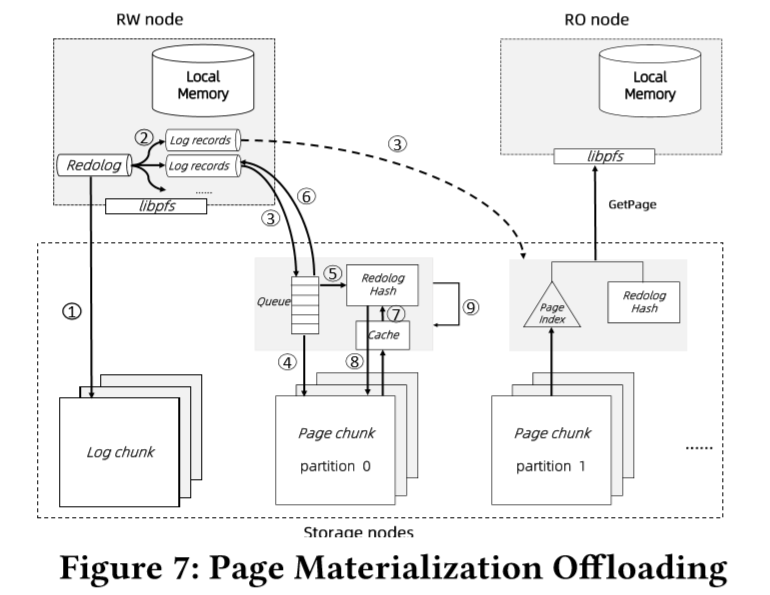
上图展示了整个处理过程:
(1)事务提交前,读写节点会把redo log的改动flush到log chunks中,当log chunks的数据复制到三副本后,可以开始提交事务;
(2)读写节点会把redolog记录的变更分解为若干条log record,根据每个log record对应的page,把记录发送到对应的page chunk;
(3-4)每一个page chunk维护一个大小约为10GB的partition,只会接受与其page相对应的log record,当page chunk的leader收到log records后,会立刻把log records持久化;
(5)并将log records插入到内存的redolog hash表内,key为page id;
(6)向读写节点返回redolog写入成功,在第6步执行成功前,读写节点会始终在本地缓存持有对dirty page的引用,dirty page在远程内存池中也不会被淘汰,在写入成功后可以淘汰dirty page。
(7)从缓存或page chunk中读取老版本page数据,使用redolog hash中的log records进行数据页回放,得到新页;
(8)将新页写至page chunk的新位置;
(9)因此一段时间内存储层会有多个版本的数据页,能够支持快速回滚,后台进程也会回收无用的redo logs及旧版本数据页。
总结
以上就是我对PolarDB Serverless论文核心内容的理解,主要介绍了论文背景,共享内存池、本地缓存的设计及如何保证他们之间数据的一致性,最后介绍了log is database思想在PolarDB Serverless中的应用,可以了解到实现内存层的解耦是一件复杂的事情,需要考虑很多一致性的问题,要使得解耦后达到高性能又是另外一项艰巨任务,需要从多维度进行性能优化,PolarDB Serverless为我们探索出一条可行之路,具有很好的启明作用;除此之外论文还重点介绍了集群扩缩容、容灾恢复、性能调优、性能测评等方面内容,证明了系统在各方面都有优异的表现,因篇幅有限,对这些模块感兴趣的伙伴可以查阅原文 。
我们在研发He3DB 时,通过软件的方式实现了另外一种维度的联邦内存池,有兴趣的同学可以查看此文 的分享,同时欢迎各位同学与我们交流,一起探讨云原生数据库方向的相关技术。
