




CoCo的全称是Common Objects in Context,是微软团队提供的一个可以用来进行图像识别的数据集,包括检测、分割、关键点估计等任务,目前用的比较多的是Coco2017数据集。
Coco2017数据集是一个包含有大量图像和标注数据的开放数据集,它是微软公司在COCO项目基础上发展而来。这个数据集主要包含了种场景下的图片,包括人物、动物、物品等各种目标。同时,它还包含了很多不同的属性,例如场景描述、图像的模糊度、遮挡程度等信息。这些数据为计算机视觉领域的图像识别、目标检测及语义分割等任务提供了有力的支持.
Coco2017数据集是目前在图像识别领域中使用最广泛的开放数据集之一,其结果被广泛应用于物体识别、物体定位、物体分割、人体姿态估计等领域。CO02017数提集的贡献在于提供了大规模的真实世界的图像和标注数据,以便研究人员可以基于这些数据提出更为有效的图像处理算法。
Coco2017数据集是具有80个类别的大规模数据集,其数据分为三部分:训练、验证和测试,每部分分别包含 118287, 5000 和 40670张图片,总大小约25g。其中测试数据集没有标注信息,所以注释部分只有训练和验证的。
Coco2017数据集文件组织如下:
├── coco2017: 数据集根目录
├── train2017: 所有训练图像文件夹(118287张)
├── test2017: 所有测试图像文件夹(40670张)
├── val2017: 所有验证图像文件夹(5000张)
└── annotations: 对应标注文件夹
├── instances_train2017.json: 对应目标检测、分割任务的训练集标注文件
├── instances_val2017.json: 对应目标检测、分割任务的验证集标注文件
├── captions_train2017.json: 对应图像描述的训练集标注文件
├── captions_val2017.json: 对应图像描述的验证集标注文件
├── person_keypoints_train2017.json: 对应人体关键点检测的训练集标注文件
└── person_keypoints_val2017.json: 对应人体关键点检测的验证集标注文件夹
我们主要用到的是instances_train2017.json
COCO的标注文件分为如下5个部分
annotation = {
'info': {},
'licenses': [],
'images': [],
'annotations': [],
'categories': []
}
info:该字典包含有关数据集的元数据,对于官方的 COCO 数据集,如下:
{
"description": "COCO 2017 Dataset",
"url": "http://cocodataset.org",
"version": "1.0",
"year": 2017,
"contributor": "COCO Consortium",
"date_created": "2017/09/01"
}
licenses:是数据集中图像许可的链接,例如知识共享许可,images字典中的每个图像都应该指定其许可证的"id"
"licenses": [
{"url": "http://creativecommons.org/licenses/by-nc-sa/2.0/","id": 1,"name": "Attribution-NonCommercial-ShareAlike License"},
{"url": "http://creativecommons.org/licenses/by-nc/2.0/","id": 2,"name": "Attribution-NonCommercial License"},
...
]
image:包含有关图像的元数据
"license":来自该"licenses" 部分的图像许可证的 ID
"file_name": 图像目录中的文件名
"coco_url": 在线托管图像副本的 URL
"height", "width": 图像的大小
"flickr_url": 图片再flickr网站上的URL
"date_captured": 拍照的时间
"images": [
{
"license": 3,
"file_name": "000000391895.jpg",
"coco_url": "http://images.cocodataset.org/train2017/000000391895.jpg",
"height": 360,
"width": 640,
"date_captured": "2013–11–14 11:18:45",
"flickr_url": "http://farm9.staticflickr.com/8186/8119368305_4e622c8349_z.jpg",
"id": 391895
},
{}
]
annotations:是数据集最重要的部分,是对数据集中所有目标信息的介绍
"segmentation":分割掩码像素列表;这是一个扁平的对列表,因此我们应该采用第一个和第二个值(图片中的 x 和 y),然后是第三个和第四个值,以获取坐标;需要注意的是,这些不是图像索引,因为它们是浮点数——它们是由 COCO-annotator 等工具从原始像素坐标创建和压缩的
"area":分割掩码内的像素数
"iscrowd":注释是针对单个对象(值为 0),还是针对彼此靠近的多个对象(值为 1);对于实例分割,此字段始终为 0 并被忽略
"image_id": ‘images’ 字典中的 ‘id’ 字段;就是图片的名称去除了后缀名
"bbox":边界框,即对象周围矩形的坐标(左上x,左上y,宽,高),[x, y, width, height]
"category_id":对象的类,对应"类别"中的"id"字段
"id": 注释的唯一标识符;
{"segmentation": [[298.13,384.52,295.14,383.33,292.15,381.83,289.76,382.73,287.97,386.61,287.67,390.2,287.67,393.78,286.47,397.37,284.68,400.66,283.48,402.15,279.9,402.45,277.51,402.75,275.72,405.88,271.23,406.18,263.17,404.69,259.88,402.59,263.46,399.31,269.14,397.81,271.53,393.93,273.92,389.45,276.01,383.77,279.6,378.69,282.29,374.21,284.68,372.12,284.98,368.23,285.58,364.64,287.97,360.46,289.46,358.07,293.64,353.89,296.93,351.5,299.92,347.31,302.61,346.42,304.4,346.72,305.9,351.5,306.49,357.47,307.09,359.27,306.49,363.15,304.7,366.44],[328.31,383.77,329.5,387.95,327.71,390.34,327.71,394.53,329.2,397.81,329.8,399.61,332.49,400.2,334.88,402.89,336.97,404.09,341.16,404.69,344.44,406.18,348.33,406.18,349.82,404.69,349.82,402.89,347.43,401.4,345.94,399.61,343.55,398.11,342.95,394.53,342.35,390.64,342.35,385.86,339.96,382.87,339.36,380.78,338.47,377.49,336.97,376.3]],
"area": 1326.2539999999997,
"iscrowd": 0,
"image_id": 469888,
"bbox": [259.88,346.42,89.94,59.76],
"category_id": 1,
"id": 524441},
categories:类别信息
supercategory表示当前这个类别的大类
id表示当前这个类别的编号,总共80个类,编号从1-80,编号0表示背景
name表示当前这个类别的名字
"categories": [
{"supercategory": "person","id": 1,"name": "person"},
{"supercategory": "vehicle","id": 2,"name": "bicycle"},
{"supercategory": "vehicle","id": 3,"name": "car"}
]
预训练模型是深度学习架构,是在大规模数据集上训练的模型,可用于特定的机器视觉任务。这些模型通常包含在机器学习框架中,并由研究人员或工业界专家进行训练。这种训练不容易执行,并且通常需要大量资源,超出许多可用于深度学习模型的人可用的资源
以下是如何在机器视觉中使用预训练模型的一些步骤:
1、选择适当的预训练模型:选择与您的问题和数据集相关的预训练模型。例如,如果您正在处理图像分类问题,则可以使用预训练的卷积神经网络(CNN),如ResNet,VGG或Inception。
2、下载预训练模型:下载选择的预训练模型及其权重。许多机器学习框架都提供了可在代码中使用的预训练模型。您还可以从预训练模型的网站或存储库中下载它们。
3、载入预训练模型:在您的代码中导入预训练模型,并将其加载到内存中。许多机器学习框架都提供了使用预训练模型的简单API。
4、使用预训练模型进行特征提取:使用预训练模型的前几层作为特征提取器。您可以将图像通过这些层传递,并使用输出作为输入来训练新的分类器或回归器。
5、微调预训练模型:微调预训练模型的某些层以适应您的数据集。通过微调,您可以调整模型以更好地适应您的特定任务。
6、评估预训练模型:在您的数据集上评估预训练模型的性能。您可以使用一些常见的评估指标,如准确性、精确度、召回率和F1分数等来评估模型的性能。
总的来说,使用预训练模型可以为机器视觉任务提供快速和高效的解决方案,并可以通过微调进行个性化定制,以适应您的特定应用场景
例如:
# 获取预训练模型
import torchvision
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
# 下载到本地后的路径如下:
# 目录为:C:\Users\<USERNAME>\.cache\torch\hub\checkpoints
# 文件名为:fasterrcnn_resnet50_fpn_coco-258fb6c6.pth
让我们看一下使用fasterrcnn_resnet50_fpn的coco预训练模型进行预测的代码吧
一、获取预训练模型
from PIL import Image
import matplotlib.pyplot as plt
import torch
import torchvision.transforms as T
import torchvision
import torch
import numpy as np
import cv2
# 判断GPU设备是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 获取预训练模型
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
model.to(device)
# 下载到本地后的路径如下:
# 目录为: C:\Users\<USERNAME>\.cache\torch\hub\checkpoints
# 文件名为: fasterrcnn_resnet50_fpn_coco-258fb6c6.pth
# print(model)
# 进入测试模式
model.eval()
# coco2017 数据集的标签名称
COCO_INSTANCE_CATEGORY_NAMES = [
'__background__', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'N/A', 'stop sign',
'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'N/A', 'backpack', 'umbrella', 'N/A', 'N/A',
'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball',
'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket',
'bottle', 'N/A', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl',
'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza',
'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'N/A', 'dining table',
'N/A', 'N/A', 'toilet', 'N/A', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'N/A', 'book',
'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush'
]
# coco2017 数据集的中文标签名称
# COCO_INSTANCE_CATEGORY_NAMES = [
# '__background__','人','自行车','汽车','摩托车','飞机','公共汽车',
# '火车','卡车','船','红绿灯','消防栓','N/A','停车标志',
# '停车收费表','长椅','鸟','猫','狗','马','羊','牛',
# '大象','熊','斑马','长颈鹿','N/A','背包','雨伞','不适用',
# '手提包','领带','手提箱','飞盘','滑雪板','单板滑雪板','运动球',
# '风筝','棒球棍','手套','滑板','冲浪板','网球拍',
# '瓶子','不适用','酒杯','杯子','叉子','刀子','勺子','碗',
# '香蕉','苹果','三明治','橙子','西兰花','胡萝卜','热狗','披萨',
# '甜甜圈','蛋糕','椅子','沙发','盆栽','床','N/A','餐桌',
# 'N/A','N/A','马桶','N/A','电视','笔记本电脑','鼠标','遥控器','键盘','手机',
# '微波炉','烤箱','烤面包机','水槽','冰箱','N/A','书本',
# '钟','花瓶','剪刀','泰迪熊','吹风机','牙刷']
二、传入图片和阈值,返回预测内容
# 根据图片和阈值设定,输出预测内容
def get_prediction(img_path, threshold):
'''
:param img_path: 预测图片文件名
:param threshold: 阈值
:return: pred_boxes, pred_class 预测框和预测分类
'''
img = Image.open(img_path)
# 转换一个PIL库的图片或者numpy的数组为tensor张量类型;转换从[0,255]->[0,1]
transform = T.Compose([T.ToTensor()])
# 图片转换
img = transform(img)
img = img.to(device)
# 模型预测
pred = model([img])
# 预测包括三个部分,boxes、labels、scores
# [{'boxes': tensor([[1.1113e+02, 8.4461e+01, 4.0692e+02, 5.0461e+02],
# [2.8157e+02, 2.4684e+02, 6.2560e+02, 5.3950e+02],
# [2.9438e+02, 2.0463e+02, 3.1350e+02, 3.2968e+02],
# [3.8507e-01, 1.0417e+02, 1.4831e+01, 1.3017e+02],
# [1.7608e+02, 1.9169e+02, 5.4610e+02, 5.2282e+02],
# [2.4491e+02, 2.0588e+02, 3.1300e+02, 4.7806e+02],
# [5.5205e+02, 3.1549e+02, 6.2130e+02, 3.4714e+02],
# [0.0000e+00, 1.0479e+02, 8.5166e+00, 1.3413e+02],
# [3.7277e+02, 1.1830e+02, 4.1221e+02, 1.3755e+02],
# [5.8022e+02, 1.1460e+02, 6.5659e+02, 1.4573e+02],
# [2.2094e+02, 2.0134e+02, 3.0731e+02, 3.5078e+02],
# [3.0305e+02, 2.0455e+02, 3.1621e+02, 2.8274e+02],
# [2.8874e+02, 2.1453e+02, 3.0633e+02, 3.3093e+02],
# [2.3883e+02, 2.2992e+02, 3.2658e+02, 4.6183e+02],
# [0.0000e+00, 1.1889e+02, 7.3096e+00, 1.3432e+02]],
# grad_fn=<StackBackward0>),
# 'labels': tensor([ 1, 18, 32, 3, 18, 32, 34, 3, 3, 3, 32, 32, 32, 31, 3]),
# 'scores': tensor([0.9991, 0.9967, 0.6231, 0.3783, 0.1957, 0.1950, 0.1809, 0.1321, 0.1220,0.1191, 0.0969, 0.0943, 0.0821, 0.0580, 0.0520],
# grad_fn=<IndexBackward0>)}]
# 类别提取
# 将类别从tensor转换为numpy,再转换为list,再获取Label名称
pred_class = [COCO_INSTANCE_CATEGORY_NAMES[i] for i in list(pred[0]['labels'].cpu().numpy())]
# ['person', 'dog', 'tie', 'car', 'dog', 'tie', 'frisbee', 'car', 'car', 'car', 'tie', 'tie', 'tie', 'handbag', 'car']
# 坐标提取
# 将坐标从tensor转换为numpy,再转换为list和tuple的坐标类型
pred_boxes = [[(i[0], i[1]), (i[2], i[3])] for i in list(pred[0]['boxes'].cpu().detach().numpy())]
# [[(111.12502, 84.460846), (406.91946, 504.6124)],
# [(281.57077, 246.84302), (625.60187, 539.4996)],
# [(294.3781, 204.63043), (313.49683, 329.68488)],
# [(0.3850731, 104.16944), (14.830844, 130.17395)],
# [(176.08134, 191.68524), (546.09674, 522.81537)],
# [(244.90976, 205.88275), (312.99918, 478.05914)],
# [(552.053, 315.48618), (621.2953, 347.13797)],
# [(0.0, 104.79019), (8.516584, 134.1295)],
# [(372.76917, 118.29688), (412.20602, 137.54626)],
# [(580.2152, 114.59604), (656.58606, 145.73427)],
# [(220.93695, 201.3379), (307.31238, 350.78308)],
# [(303.04803, 204.54793), (316.20798, 282.73712)],
# [(288.7375, 214.53268), (306.3312, 330.93005)],
# [(238.83302, 229.91945), (326.582, 461.82977)],
# [(0.0, 118.89231), (7.309639, 134.32108)]]
# 得分提取
pred_score = list(pred[0]['scores'].cpu().detach().numpy())
# [0.9990747, 0.9967301, 0.62309444, 0.3783163, 0.19568485, 0.19499916, 0.18086173, 0.13209558,
# 0.121989585, 0.11910359, 0.09686677, 0.094305165, 0.08210311, 0.05797666, 0.052047584]
# 找出符合相似度要求的个数
pred_t = [pred_score.index(x) for x in pred_score if x > threshold][-1]
# 根据符合条件的个数获取标注框和标注类别
pred_boxes = pred_boxes[:pred_t + 1]
# [[(111.12502, 84.460846), (406.91946, 504.6124)], [(281.57077, 246.84302), (625.60187, 539.4996)]]
pred_class = pred_class[:pred_t + 1]
# ['person', 'dog']
return pred_boxes, pred_class
三、对预测对象进行可视化展示
def object_detection_api(img_path, threshold=0.5, rect_th=3, text_size=3, text_th=3):
boxes, pred_cls = get_prediction(img_path, threshold)
# 用opencv读取文件
img = cv2.imread(img_path)
# 转换为RGB图像
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 根据标注框数量进行遍历
for i in range(len(boxes)):
# 根据坐标绘出目标
cv2.rectangle(img, (int(boxes[i][0][0]),int(boxes[i][0][1])), (int(boxes[i][1][0]),int(boxes[i][1][1])), color=(0, 255, 0),
thickness=rect_th)
# cv2.rectangle(img, boxes[i][0], boxes[i][1],color=(0, 255, 0), thickness=rect_th)
# cv2.error: OpenCV(4.8.0) :-1: error: (-5:Bad argument) in function 'rectangle'
# 标注类别
cv2.putText(img, pred_cls[i], (int(boxes[i][0][0]),int(boxes[i][0][1])), cv2.FONT_HERSHEY_SIMPLEX, text_size, (0, 255, 0),
thickness=text_th)
# cv2.putText(img,pred_cls[i], boxes[i][0], cv2.FONT_HERSHEY_SIMPLEX, text_size, (0,255,0),thickness=text_th)
# cv2.error: OpenCV(4.8.0) :-1: error: (-5:Bad argument) in function 'putText'
# plt.figure(figsize=(20, 30))
plt.imshow(img)
plt.show()
四、定义主函数,并开始预测
if __name__ == '__main__':
pic_name='photo2.jpg'
import datetime
for i in range(1,10):
threshold=i/10.0
begintime=datetime.datetime.now()
object_detection_api(pic_name, threshold=threshold)
endtime = datetime.datetime.now()
duration=endtime-begintime
begintime=begintime.strftime('%Y-%m-%d %H:%M:%S.%f')[:-3]
endtime = endtime.strftime('%Y-%m-%d %H:%M:%S.%f')[:-3]
print('time={},threshold={},begintime={},endtime={},duration={}'.format(i,threshold,begintime,endtime,duration))
以下是待预测的原始图片

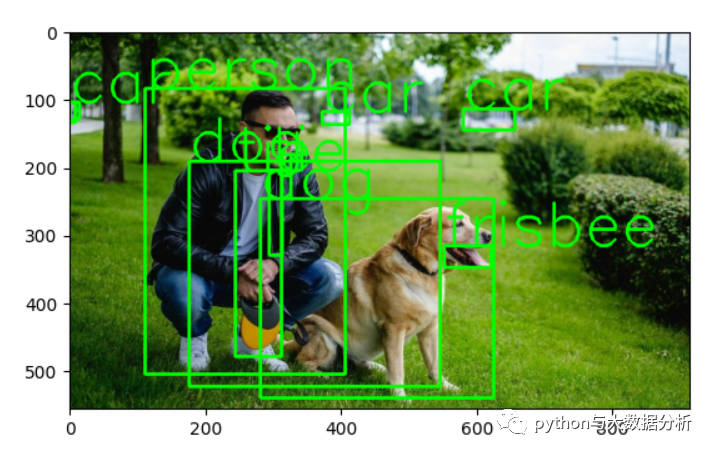
以下是阈值设定为0.1时的预测输出可视化
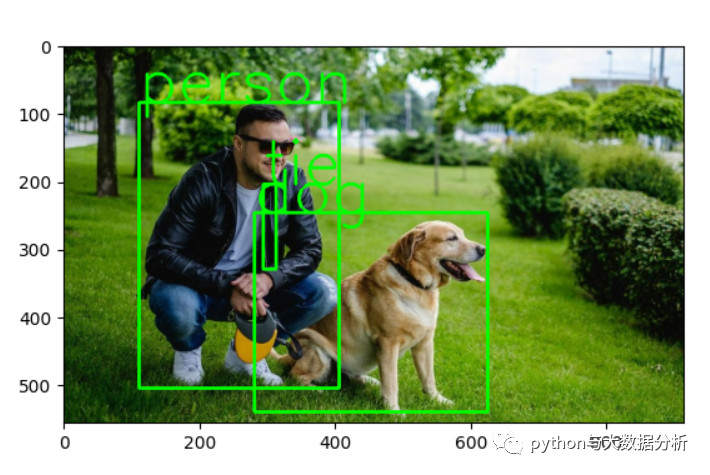
以下是阈值设定为0.5时的预测输出可视化
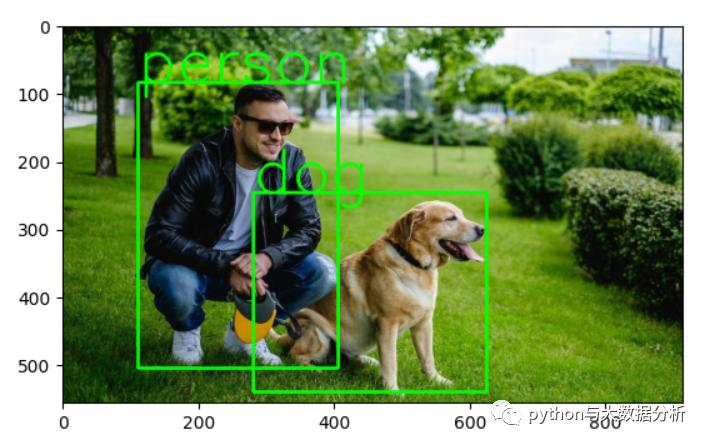
以下是阈值设定为0.9时的预测输出可视化,显然最后这个预测是最准确的。
以下是print(model)的输出,可以看到模型包括backbone、fpn、rpn、roi_heads等几个组成部分
FasterRCNN(
(transform): GeneralizedRCNNTransform(
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
Resize(min_size=(800,), max_size=1333, mode='bilinear')
)
(backbone): BackboneWithFPN(
(body): IntermediateLayerGetter(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): FrozenBatchNorm2d(64, eps=0.0)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(64, eps=0.0)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(64, eps=0.0)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(256, eps=0.0)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): FrozenBatchNorm2d(256, eps=0.0)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(64, eps=0.0)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(64, eps=0.0)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(256, eps=0.0)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(64, eps=0.0)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(64, eps=0.0)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(256, eps=0.0)
(relu): ReLU(inplace=True)
)
)
(layer2): Sequential(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(128, eps=0.0)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(128, eps=0.0)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(512, eps=0.0)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): FrozenBatchNorm2d(512, eps=0.0)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(128, eps=0.0)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(128, eps=0.0)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(512, eps=0.0)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(128, eps=0.0)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(128, eps=0.0)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(512, eps=0.0)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(128, eps=0.0)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(128, eps=0.0)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(512, eps=0.0)
(relu): ReLU(inplace=True)
)
)
(layer3): Sequential(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=0.0)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=0.0)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=0.0)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): FrozenBatchNorm2d(1024, eps=0.0)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=0.0)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=0.0)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=0.0)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=0.0)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=0.0)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=0.0)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=0.0)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=0.0)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=0.0)
(relu): ReLU(inplace=True)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=0.0)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=0.0)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=0.0)
(relu): ReLU(inplace=True)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=0.0)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=0.0)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=0.0)
(relu): ReLU(inplace=True)
)
)
(layer4): Sequential(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(512, eps=0.0)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(512, eps=0.0)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(2048, eps=0.0)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): FrozenBatchNorm2d(2048, eps=0.0)
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(512, eps=0.0)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(512, eps=0.0)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(2048, eps=0.0)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(512, eps=0.0)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(512, eps=0.0)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(2048, eps=0.0)
(relu): ReLU(inplace=True)
)
)
)
(fpn): FeaturePyramidNetwork(
(inner_blocks): ModuleList(
(0): Conv2dNormActivation(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
)
(1): Conv2dNormActivation(
(0): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
)
(2): Conv2dNormActivation(
(0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
)
(3): Conv2dNormActivation(
(0): Conv2d(2048, 256, kernel_size=(1, 1), stride=(1, 1))
)
)
(layer_blocks): ModuleList(
(0-3): 4 x Conv2dNormActivation(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
(extra_blocks): LastLevelMaxPool()
)
)
(rpn): RegionProposalNetwork(
(anchor_generator): AnchorGenerator()
(head): RPNHead(
(conv): Sequential(
(0): Conv2dNormActivation(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
)
)
(cls_logits): Conv2d(256, 3, kernel_size=(1, 1), stride=(1, 1))
(bbox_pred): Conv2d(256, 12, kernel_size=(1, 1), stride=(1, 1))
)
)
(roi_heads): RoIHeads(
(box_roi_pool): MultiScaleRoIAlign(featmap_names=['0', '1', '2', '3'], output_size=(7, 7), sampling_ratio=2)
(box_head): TwoMLPHead(
(fc6): Linear(in_features=12544, out_features=1024, bias=True)
(fc7): Linear(in_features=1024, out_features=1024, bias=True)
)
(box_predictor): FastRCNNPredictor(
(cls_score): Linear(in_features=1024, out_features=91, bias=True)
(bbox_pred): Linear(in_features=1024, out_features=364, bias=True)
)
)
)
以下是在GPU和CPU下的预测输出效率,大致上是十倍的速度差距
GPU执行时间
time=1,threshold=0.1,begintime=2023-09-07 14:29:37.003,endtime=2023-09-07 14:29:40.323,duration=0:00:03.319326
time=2,threshold=0.2,begintime=2023-09-07 14:29:40.323,endtime=2023-09-07 14:29:40.755,duration=0:00:00.432050
time=3,threshold=0.3,begintime=2023-09-07 14:29:40.755,endtime=2023-09-07 14:29:41.179,duration=0:00:00.424381
time=4,threshold=0.4,begintime=2023-09-07 14:29:41.179,endtime=2023-09-07 14:29:41.633,duration=0:00:00.453787
time=5,threshold=0.5,begintime=2023-09-07 14:29:41.633,endtime=2023-09-07 14:29:42.077,duration=0:00:00.444630
time=6,threshold=0.6,begintime=2023-09-07 14:29:42.078,endtime=2023-09-07 14:29:42.548,duration=0:00:00.469273
time=7,threshold=0.7,begintime=2023-09-07 14:29:42.549,endtime=2023-09-07 14:29:42.984,duration=0:00:00.434861
time=8,threshold=0.8,begintime=2023-09-07 14:29:42.984,endtime=2023-09-07 14:29:43.449,duration=0:00:00.465333
time=9,threshold=0.9,begintime=2023-09-07 14:29:43.449,endtime=2023-09-07 14:29:43.912,duration=0:00:00.462794
CPU执行时间
time=1,threshold=0.1,begintime=2023-09-07 14:29:03.452,endtime=2023-09-07 14:29:10.600,duration=0:00:07.147012
time=2,threshold=0.2,begintime=2023-09-07 14:29:10.600,endtime=2023-09-07 14:29:17.792,duration=0:00:07.192556
time=3,threshold=0.3,begintime=2023-09-07 14:29:17.793,endtime=2023-09-07 14:29:23.851,duration=0:00:06.058052
time=4,threshold=0.4,begintime=2023-09-07 14:29:23.851,endtime=2023-09-07 14:29:29.414,duration=0:00:05.562427
time=5,threshold=0.5,begintime=2023-09-07 14:29:29.414,endtime=2023-09-07 14:29:35.003,duration=0:00:05.589819
time=6,threshold=0.6,begintime=2023-09-07 14:29:35.003,endtime=2023-09-07 14:29:40.435,duration=0:00:05.431289
time=7,threshold=0.7,begintime=2023-09-07 14:29:40.435,endtime=2023-09-07 14:29:45.634,duration=0:00:05.199502
time=8,threshold=0.8,begintime=2023-09-07 14:29:45.634,endtime=2023-09-07 14:29:50.869,duration=0:00:05.234431
time=9,threshold=0.9,begintime=2023-09-07 14:29:50.869,endtime=2023-09-07 14:29:56.805,duration=0:00:05.936862
如果我们想对视频文件或摄像头进行预测,可以使用以下代码
from PIL import Image
import matplotlib.pyplot as plt
import torch
import torchvision.transforms as T
import torchvision
import torch
import numpy as np
import cv2
# 判断GPU设备是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 获取预训练模型
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
model.to(device)
# 下载到本地后的路径如下:
# 目录为: C:\Users\<USERNAME>\.cache\torch\hub\checkpoints
# 文件名为: fasterrcnn_resnet50_fpn_coco-258fb6c6.pth
# print(model)
# 进入测试模式
model.eval()
# coco2017 数据集的标签名称
COCO_INSTANCE_CATEGORY_NAMES = [
'__background__', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'N/A', 'stop sign',
'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'N/A', 'backpack', 'umbrella', 'N/A', 'N/A',
'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball',
'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket',
'bottle', 'N/A', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl',
'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza',
'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'N/A', 'dining table',
'N/A', 'N/A', 'toilet', 'N/A', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'N/A', 'book',
'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush'
]
# coco2017 数据集的中文标签名称
# COCO_INSTANCE_CATEGORY_NAMES = [
# '__background__','人','自行车','汽车','摩托车','飞机','公共汽车',
# '火车','卡车','船','红绿灯','消防栓','N/A','停车标志',
# '停车收费表','长椅','鸟','猫','狗','马','羊','牛',
# '大象','熊','斑马','长颈鹿','N/A','背包','雨伞','不适用',
# '手提包','领带','手提箱','飞盘','滑雪板','单板滑雪板','运动球',
# '风筝','棒球棍','手套','滑板','冲浪板','网球拍',
# '瓶子','不适用','酒杯','杯子','叉子','刀子','勺子','碗',
# '香蕉','苹果','三明治','橙子','西兰花','胡萝卜','热狗','披萨',
# '甜甜圈','蛋糕','椅子','沙发','盆栽','床','N/A','餐桌',
# 'N/A','N/A','马桶','N/A','电视','笔记本电脑','鼠标','遥控器','键盘','手机',
# '微波炉','烤箱','烤面包机','水槽','冰箱','N/A','书本',
# '钟','花瓶','剪刀','泰迪熊','吹风机','牙刷']
if __name__ == '__main__':
model.eval()
cap = cv2.VideoCapture(0)
transform = T.Compose([T.ToTensor()])
while True:
ret, frame = cap.read()
image = frame
frame = transform(frame)
frame = frame.to(device)
pred = model([frame])
# 检测出目标的类别和得分
pred_class = [COCO_INSTANCE_CATEGORY_NAMES[i] for i in list(pred[0]['labels'].cpu().numpy())]
pred_boxes = [[(i[0], i[1]), (i[2], i[3])] for i in list(pred[0]['boxes'].cpu().detach().numpy())]
pred_score = list(pred[0]['scores'].cpu().detach().numpy())
# 只保留识别的概率大约 0.5 的结果。
pred_index = [pred_score.index(x) for x in pred_score if x > 0.5]
for index in pred_index:
box = pred_boxes[index]
cv2.rectangle(img=image, pt1=[int(box[0]), int(box[1])], pt2=[int(box[2]), int(box[3])],
color=(0, 0, 225), thickness=3)
texts = pred_class[index] + ":" + str(np.round(pred_score[index], 2))
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(image, texts, (int(box[0]), int(box[1])), font, 1, (200, 255, 155), 2, cv2.LINE_AA)
cv2.imshow('摄像头', image)
cv2.waitKey(10)
最后欢迎关注公众号:python与大数据分析

