




注:本文在oracle 19c版本下测试,其他数据库的写法差不多,也可以借鉴这个思路。
测试用表:
--生成测试用表,1000万记录:create table t10maswith t1 as (select /*+ materialize */ * from dba_objects)select /*+ leading(b) */rownum as id,a.*from t1 a,xmltable('1 to 1000') bwhere rownum<=1e7;--增加主键:alter table t10m add constraint pk_t10m primary key (id);--创建分页查询使用的索引(使用新方法后,这个索引就不需要了):--owner是谓词条件,id是order by条件create index idx_t10m_owner_id on t10m(owner,id);--OWNER字段的数据分布情况,sys用户对应的记录数最多:select owner,count(*) from t10m group by owner order by 2;OWNER COUNT(*)------------------------------ ----------APPQOSSYS 810SI_INFORMTN_SCHEMA 1072ORACLE_OCM 1078DBSFWUSER 1080ORDPLUGINS 1340OUTLN 1350DEMO 1474REMOTE_SCHEDULER_AGENT 1755OJVMSYS 2814DVF 2948OLAPSYS 3350HR 4556AUDSYS 6187DBSNMP 7965GSMADMIN_INTERNAL 28884LBACSYS 32562ORDDATA 36850CTXSYS 53332WMSYS 53730DVSYS 54270SYSTEM 63714ORDSYS 75978FRED 92594XDB 140913MDSYS 593754PUBLIC 1584712SYS 7150928
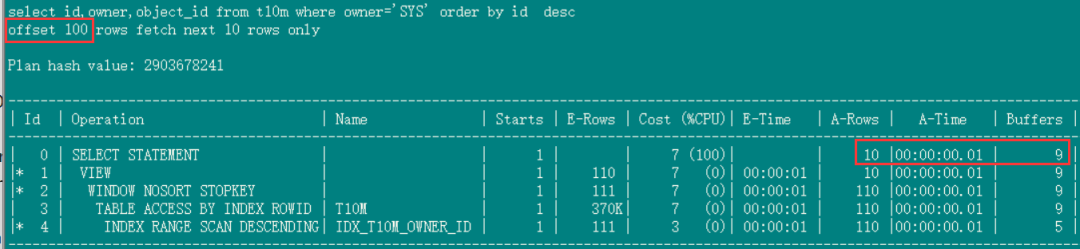
分页查询,最常用的写法是下面这样的(其中owner的条件是可变的,这里选了一个对应记录数最多的'SYS'值做演示,就像是论坛系统一个人气最旺的一个版块,owner'=其他值'就是访问其他不同的版块):
select id,owner,object_id
from t10m
where owner='SYS'
order by id desc
offset 100 rows fetch next 10 rows only;
(我这里没有使用oracle传统的rownum写法,而是使用了12c开始支持的offset fetch写法,这个写法跟mysql和postgresql的写法比较接近)。
这种写法,配合(owner,id)两字段联合索引,当offset后面的值较小时,效率非常高,随着offset值的逐渐增大,查询效率会越来越差。大部分论坛使用的分页就是这种方法。所以我们在浏览论坛的时候,查看前面几页的速度都比较快,如果要跳转到比较靠后的页,速度就比较慢了,就是这个原因。如下面所示:
靠前分页的速度,offset 100(几个毫秒):
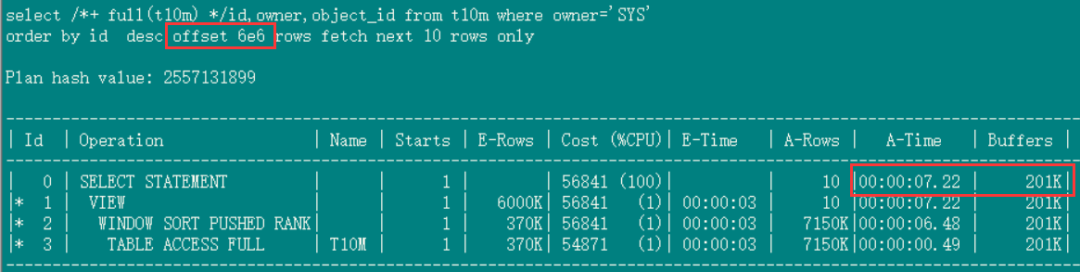
深度分页的速度,offset 600万(全表扫描,7.22秒):
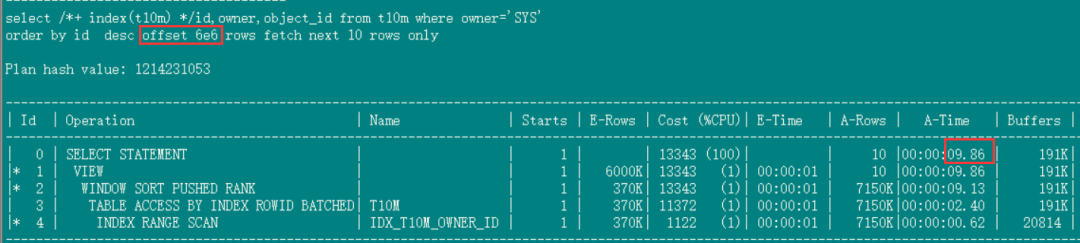
深度分页的速度,offset 600万(走索引更慢,9.86秒):
对于这种深度分页的优化,网上流传最多的是“记忆ID法”, 就是通过本次分页得到的最大(最小)id,查询“下一页”时再把这个值带进去,比如:
第一页:
select max(id) from t10m where owner='SYS';
返回10000000
select id,owner,object_id from t10m where owner='SYS' and id<=10000000 order by id desc fetch next 10 rows only;
假设这个结果集得到最小id为9999991,“下一页”的查询是:
依此类推。这个写法的效率非常高,但是有2个问题:
不好跳转,一般只会提供“下一页”的选择。
如果要得到总页数,需要全表扫描(或索引快速全扫描),这个时间比较长;
下面介绍2种方法,可以让类似论坛访问的任意页跳转也跟查询第一页一样高效。
方法1: 增加字段,填充字段,增加索引,改变写法:
--在表上增加一个字段owner_seq:
alter table t10m add owner_seq number ;
--为新字段赋值:(hint 也可以替换成parallel )
--增加索引
create index idx_t10m_owner_seq on t10m(owner,owner_seq);
--做完了上面操作后,页数的计算方法,非常高效(假设每页显示10条记录):
select ceil(((select max(owner_seq) from t10m where owner='SYS')-(select min(owner_seq) from t10m where owner='SYS')+1)/10) as page_num from dual;
SQL写法上的调整:
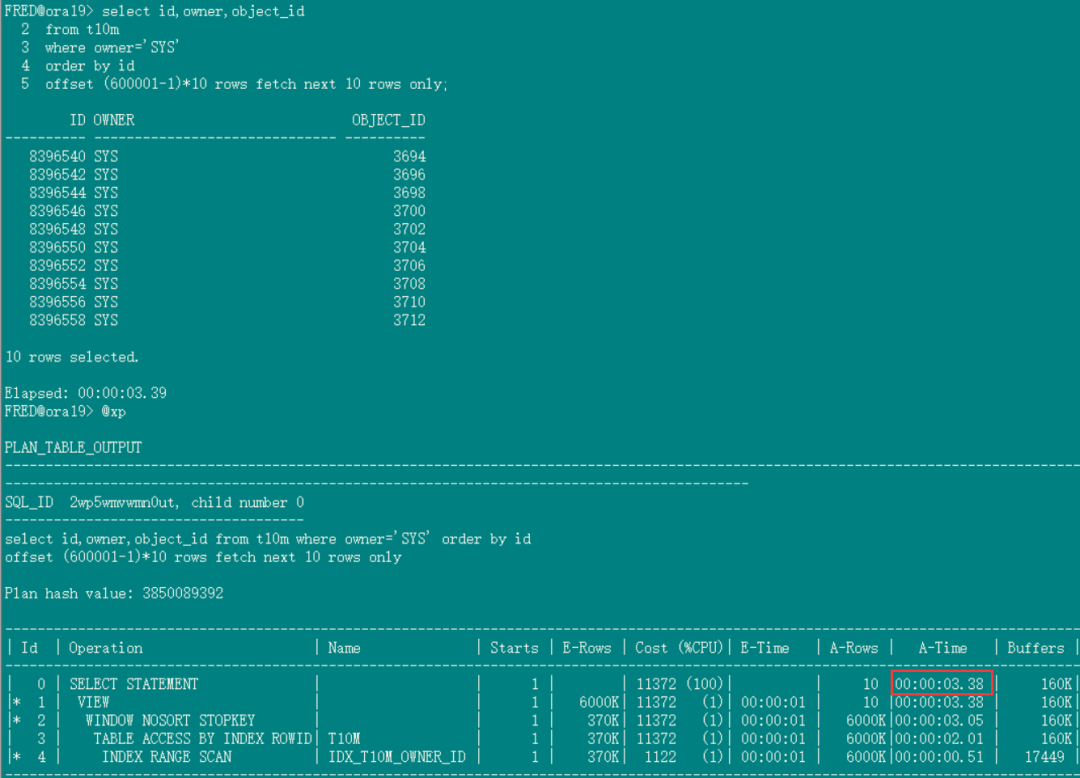
--如果原分页sql是升序,取第600001页(每页10条记录),执行时间3.38秒:
select id,owner,object_id
from t10m
where owner='SYS'
order by id
offset (600001-1)*10 rows fetch next 10 rows only;
对应的新sql写法(2步):
--1.先找到owner对应owner_seq最小值(可能存在删除历史数据),这个步骤耗时基本可以忽略不加:
select nvl(min(owner_seq),0) from t10m where owner='SYS';

--得到x(这里因为没有删除历史数据,x=1)
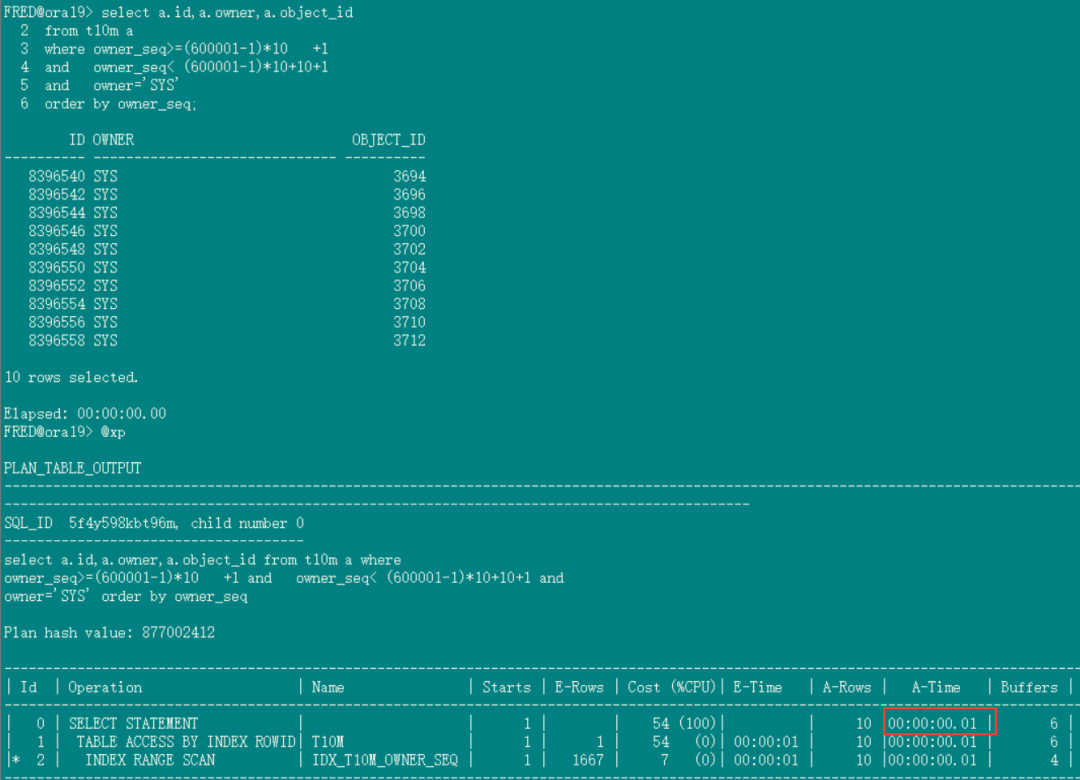
--2.带入x(红色的1)到下面sql,执行时间只需要几毫秒:
select a.id,a.owner,a.object_id
from t10m a
where owner_seq>=(600001-1)*10 +1
and owner_seq< (600001-1)*10+10+1
and owner='SYS'
order by owner_seq;
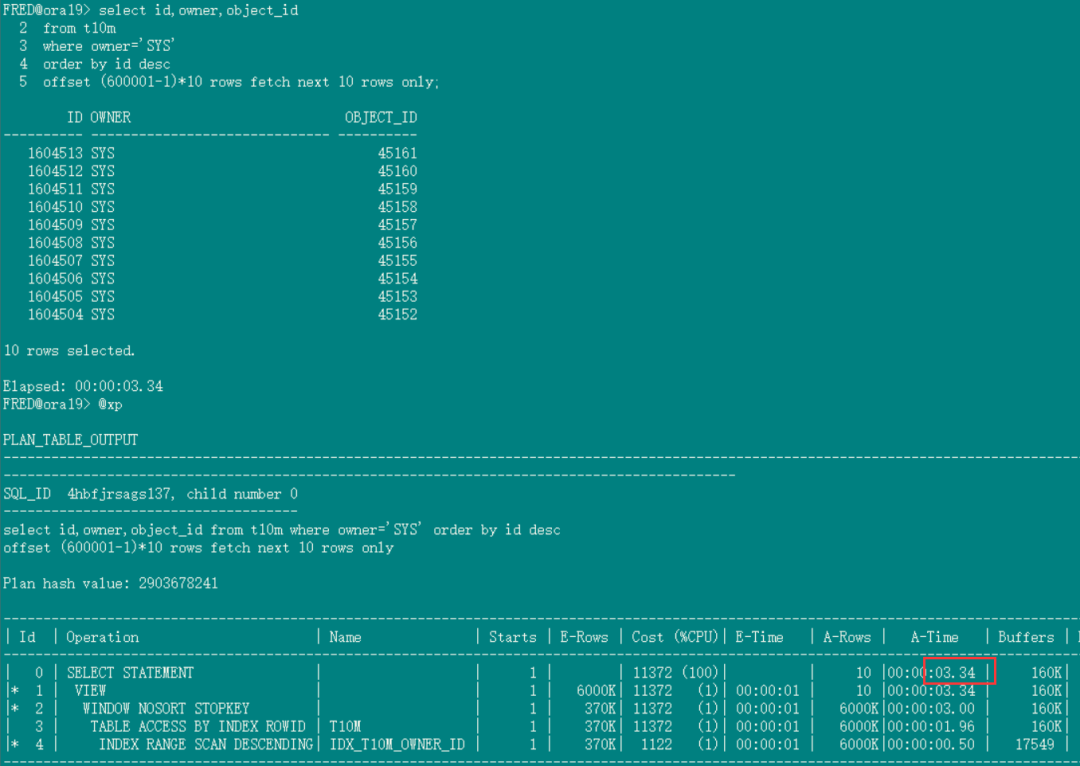
如果原SQL是降序分页,取第600001页(每页10条记录),执行时间3.34秒:
对应的新写法如下, 执行时间也是只有几毫秒,分2步:
1.第一步先取最大值,执行时间忽略不计:
select nvl(max(owner_seq),0) from t10m where owner='SYS';
--返回结果7150928
2.将结果带入下面SQL:
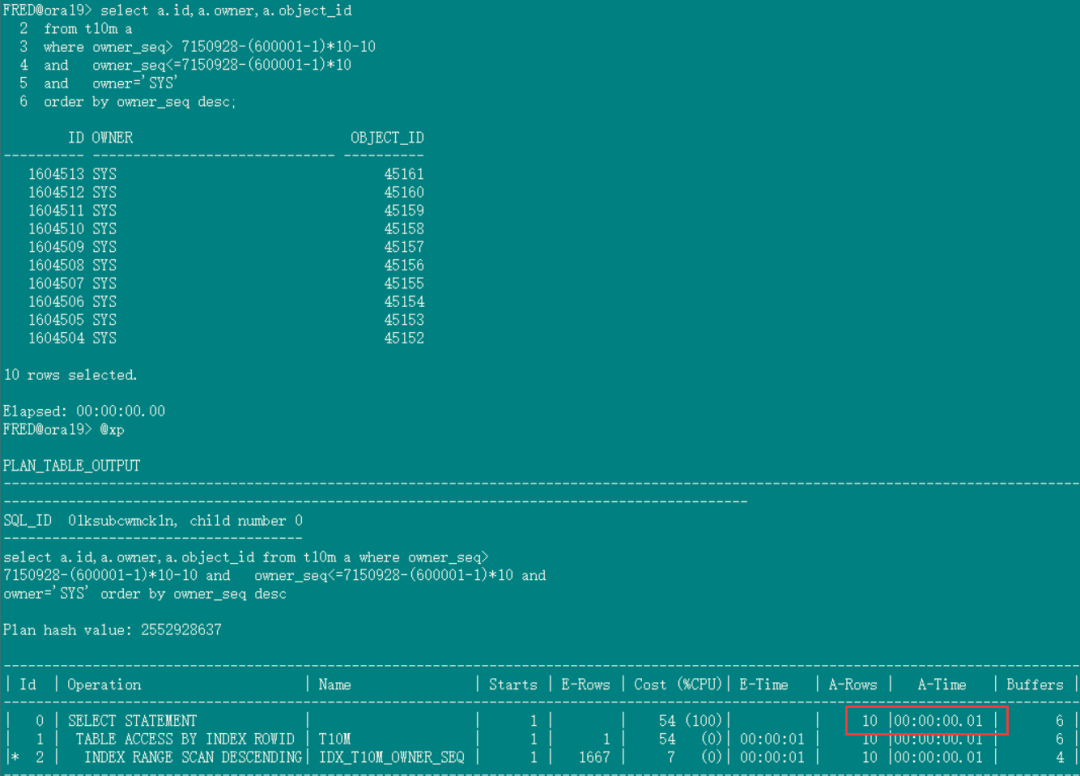
insert into t10m (id,owner,owner_seq) values(:id,:owner,(select nvl(max(owner_seq),0)+1 from t10m where owner=:owner));
方法2:创建物化视图
实现方法:
1.创建一个物化视图:

