





今年 3 月,在阿里云瑶池数据库峰会上,阿里云与飞轮科技正式达成战略合作协议,双方旨在共同研发名为阿里云瑶池数据库 SelectDB 版(以下简称:瑶池数据库 SelectDB 版)的新一代实时数据仓库,为用户提供在阿里云上的全托管服务。经过 5 个月的共同努力,阿里云 SelectDB 的首个版本已于 8 月 20 日正式上线,用户可以在阿里云上便捷地使用SelectDB数仓服务,以满足海量数据极速实时、融合统一、简单易用的分析处理需求。
 今年3月,阿里云数据库事业部负责人李飞飞与飞轮科技COO连林江现场签约
今年3月,阿里云数据库事业部负责人李飞飞与飞轮科技COO连林江现场签约SelectDB是飞轮科技基于Apache Doris内核打造的聚焦于企业大数据实时分析需求的企业级产品。飞轮科技初创团队由Apache Doris项目核心成员以及百度智能云初创成员组成。同时有多位创始人为社区 PMC 成员或 Committer,主导发布了Apache Doris诸多版本。
在飞轮科技和社区的共同推动下,Apache Doris已在全球范围内拥有广泛的用户群体。目前,全球中大型企业用户已突破 2000 家 ,覆盖金融、互联网、能源、制造、通信、物流等数十个行业, 赢得了数万名用户的喜爱。在社区活跃度方面,目前项目已在 GitHub 获得近 10000 Star,汇集国内外近 600 名社区开发者,月度活跃贡献者数量连续数月位居全球大数据开源项目榜首,已成长为全球大数据领域最活跃的开源项目之一。
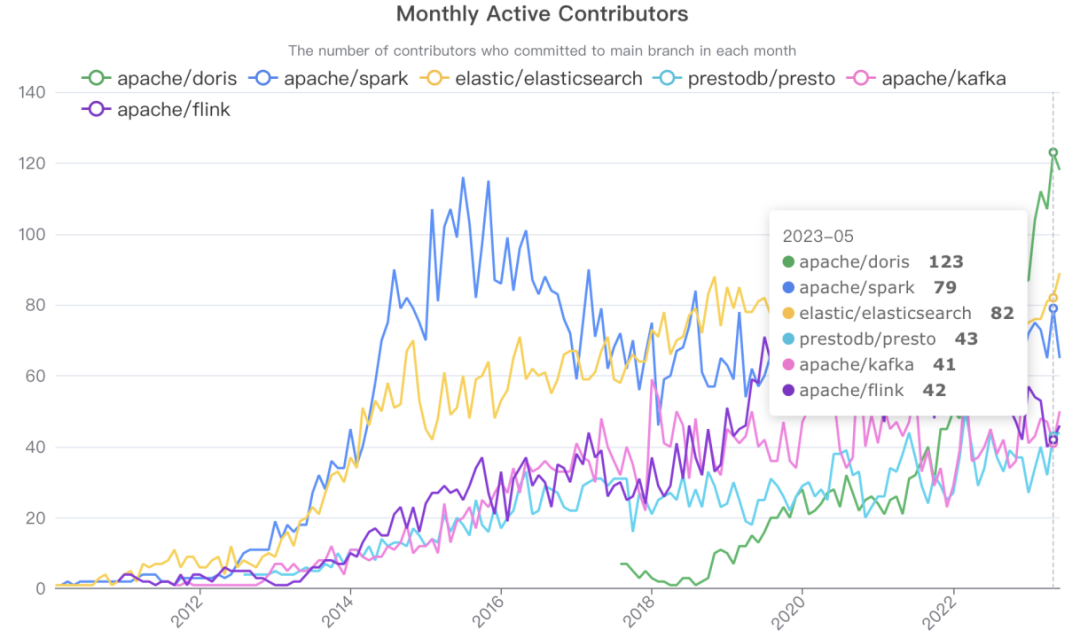 在全球大数据开源项目排行中活跃贡献者数连续10+月位列Top 1,超越Spark最活跃时期
在全球大数据开源项目排行中活跃贡献者数连续10+月位列Top 1,超越Spark最活跃时期本次阿里云和飞轮科技联合推出的阿里云瑶池数据库 SelectDB 版,不仅延续了Apache Doris性能优异、架构精简、稳定可靠、生态丰富等核心特性,同时融入了云服务随需而用的特性,通过云原生存算分离的创新架构,为企业带来分钟级弹性伸缩、高性价比、简单易用、安全稳定的一键式云上实时分析体验。

扫码申请
瑶池数据库 SelectDB 版的核心优势
01 极致的查询性能
▶︎在宽表聚合场景下,使用 SSB-FLAT 测试,SelectDB 是 ClickHouse 的 3.4 倍,是 Presto 的 92 倍,是业界标杆产品 Snowflake 的 6 倍。
▶︎在多表关联场景下,使用 TPC-H SF100 测试,SelectDB 的性能可达到 Redshift 的 1.5 倍,ClickHouse 的 49 倍,同时是业界标杆产品 Snowflake 的 2.5 倍。
▶︎在高并发点查场景下,使用 YCSB 测试集,SelectDB 在 10 列测试中,主键高并发点查能力提升 20 倍;在 100 列测试中,主键高并发点查吞吐是某云产品 H 的 2.5 倍,非主键高并发点查吞吐是某云产品 H 的 11 倍。
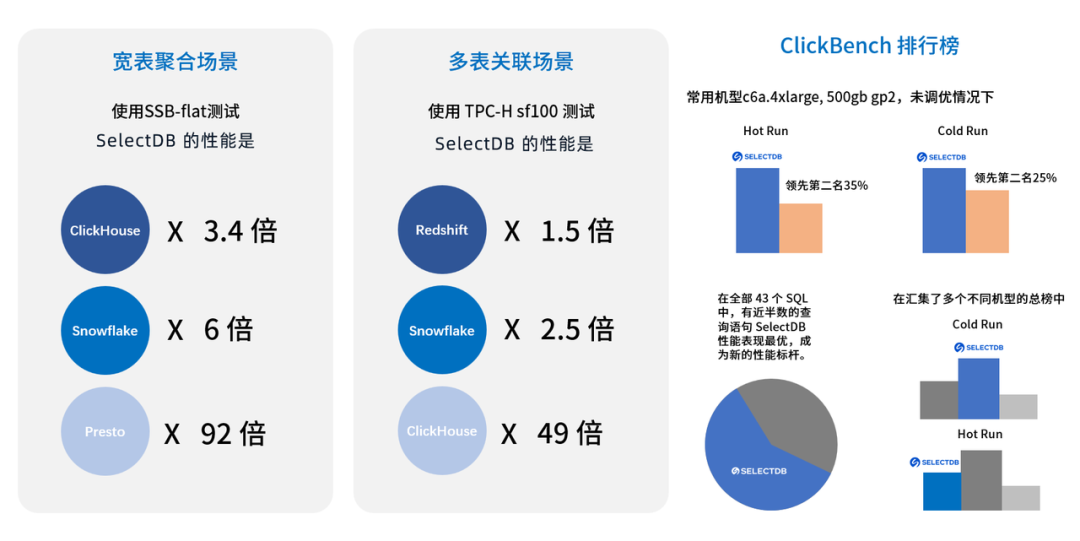
SelectDB如此卓越的性能主要得益于以下“黑科技”的支持:
▶︎更智能的全新查询优化器:SelectDB 采取更先进的 Cascades 框架、基于丰富的统计信息,实现了更智能化的自适应调优,在绝大多数场景无需任何调优和 SQL 改写即可实现极致的查询性能,同时对复杂 SQL 支持得更加完备,可完整支持 TPC-DS 全部 99 个 SQL。
▶︎MPP执行模型和自适应的并行执行引擎:SelectDB 采取 MPP 并行执行模型,可以充分利用节点间和节点内的并行计算能力,同时引入了自适应的 Pipeline 执行模型,由数据驱动控制流变化、减少了线程频繁创建和销毁带来的开销,实现了阻塞操作的异步化和资源池化以及更加系统资源的灵活分配,提升了 SelectDB 对于 CPU 多机多核的资源利用率,在混合负载场景下获得更高效的执行效率。
▶︎向量化执行引擎和执行算子优化:SelectDB 实现了全面向量化,包括查询、导入、Schema Change、Compaction、数据导出、UDF等,通过向量化减少虚函数调用与Cache Miss、进一步利用 SIMD 指令,充分发挥现代 CPU 的计算能力。同时通过对执行算子的优化,在宽表聚合和多表关联场景都获得了更高的查询性能。
02 存算分离全新架构
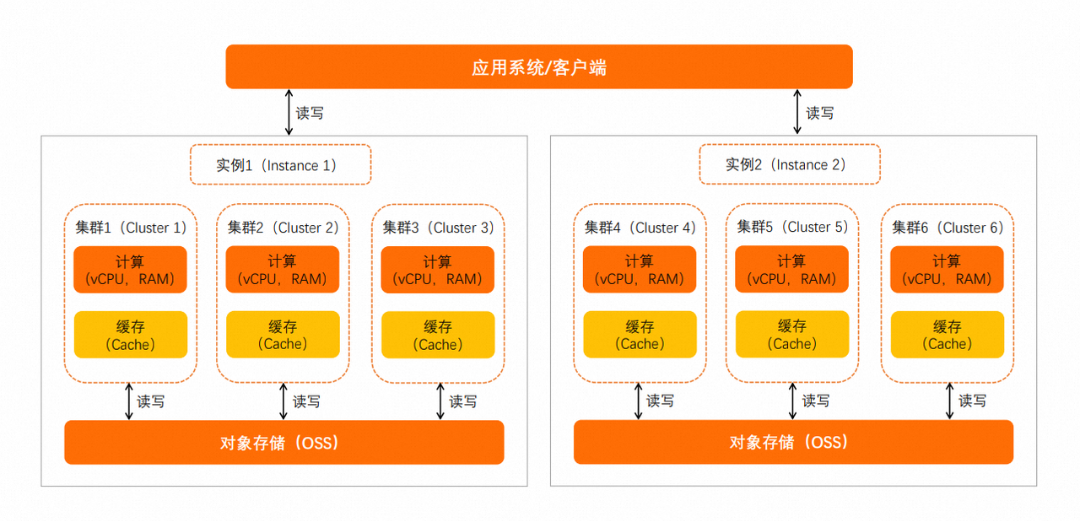 瑶池数据库 SelectDB 版云原生存算分离架构
瑶池数据库 SelectDB 版云原生存算分离架构03 融合统一的分析体验
瑶池数据库 SelectDB 版可以提供融合统一的解决方案,可满足用户在多种典型的数据处理与分析场景的需求,在一套系统中即可完成点查询、报表分析、即席查询、ETL/ELT 等多种查询负载。同时,SelectDB在 ETL/ELT 场景性能表现优异,在相同资源下,其速度是 Hive 的 54 倍、Spark 的 12 倍。
与此同时,融合统一的特性离不开联邦查询能力和对半结构化数据的支持:
04 极简易用的使用体验
阿里云瑶池数据库 SelectDB 版为用户提供了极简易用的使用体验,具体表现在以下几个方面:
1. 提供丰富的导入方式:瑶池数据库 SelectDB 版提供了丰富易用的数据导入方式,包括Stream Load、OSS Load 以及为打通周边大数据生态进行连接导入的 Connector插件等,可以满足用户实时小批量数据导入和批量数据导入和集成的需求。
2. 高效的数据更新能力:支持主键表(Unique Key)进行高效的数据更新,并对 Upsert、条件更新/条件删除、部分列更新、分区覆盖等各类更新提供了完备的支持,不仅满足高效灵活的数据更新需求,还可以对海量可变的数据更新提供支持。
3. 支持MySQL连接协议:瑶池数据库 SelectDB 版支持MySQL连接协议。用户可以使用MySQL Client、JDBC 和 DBeaver来连接使用阿里云数据库SelectDB版,对于用户来说节省了很多学习成本,简单易用。
05 丰富的企业级特性
阿里云瑶池数据库 SelectDB 版是一款面向企业、开箱即用的生产级数据仓库。在企业生产中,数据安全的保障至关重要,对此瑶池数据库 SelectDB 版提供一系列企业特性支持,可以有效帮助企业安全、稳定地进行复杂的数据管理。
1. 严格可靠的安全体系:基于阿里云平台已有的安全防护体系,SelectDB提供了更多安全特性,例如 IP 地址白名单、VPC 私网连接、权限与角色多维度访问控制、Global/Catalog/Database/Table 多级权限控制、SQL 黑名单机制限制查询访问、控制台敏感操作二次认证等。
2. 多层级的资源隔离:支持在阿里云账号、VPC、子网、实例、集群等多层级进行网络或资源隔离,避免相互之间影响,可以独立稳定运行。例如:每个阿里云账号可以创建多个 SelectDB 数仓实例,相互之间资源和数据完全隔离。每个 SelectDB 数仓实例可以创建多个计算集群,在共享的同一份数据上分别支撑不同的工作负载(如导入、查询、ETL/TLT等),读写性能互不影响。
3. 完善的监控告警机制:SelectDB与阿里云应用实时监控服务(ARMS)、云监控服务(CloudMonitor)联合实现了监控告警机制,提供多维度、可视化、实时的基础资源监控和查询性能监控信息。用户可以随时查看多达 18 项监控指标的历史数据曲线,用以辅助排查定位问题或优化配置;也可以设置阈值告警规则,随时随地接收告警短信或邮件,及时掌握数仓运行的异态,快速响应处理解决,避免或减少负面影响。
01 在线高并发报表与分析
主要服务在线业务、大量用户实时访问的在线高并发报表与分析,典型场景包括广告营销报表、保险客户分析、物流实时看板、交易明细查询等。
传统解决方案面临的挑战包括数据从产生到可见的延时高(小时级),查询响应速度慢并发低(仅支持数十并发),同时易发生数据丢失或重复,服务可用性差等问题。
▶︎支持在线扩容、升级自动副本均衡,支持多集群互备容灾,可实现服务高可用。
▶︎可支撑单机 3 万 QPS 的高并发,查询延时 99 分位 200ms 以内。
02 用户画像与行为分析
通过用户画像分析,可以洞察用户的行为、兴趣、需求等信息,更好地把握用户的生命周期,为企业提供精细化的营销和服务;通过用户行为分析,可以实现个性化、精细化的运营,以更加灵活的方式触达用户,提升用户的体验。
传统解决方案面临的挑战包括计算分析过程复杂,难以实时响应查询;表结构不灵活,不适应灵活的业务变化(如添加或删除列);同时,当用户数据发生变化时,原有数据无法实时更新。
▶︎通过写时合并技术(MOW),可支持画像场景的宽表列实时更新。
▶︎在千亿数据的用户画像分析场景下,可实现秒级人群预估、秒级10标签圈人和秒级100标签人群圈选。
03 日志存储与分析
典型场景:
日志对于保障系统、业务稳定性至关重要,常用于故障排查、监控告警等,企业需要构建统一的日志存储与分析平台。常见的日志种类有服务器日志、业务日志、网络设备日志、物联网日志等。
现状分析:
面对庞大的日志数量,日志场景需要同时实现高吞吐写入和实时可见性。且随着时间的推移,日志的规模不断增长,因此降低存储成本成为一个挑战。此外,日志场景往往还需要快速的文本检索能力,以便按关键字进行匹配查询,以满足故障排查等场景的快速响应需求。
如何解决:
▶︎利用倒排索引快速精准定位匹配的数据,结合时序存储模型特点和 TopN 查询的动态剪枝算法,显著提升日志检索与分析性能。
方案收益:
瑶池数据库 SelectDB 版相较于传统方案,能够实现 4.2 倍的写入性能提升和 2.3 倍的查询性能提升,同时磁盘资源占用显著下降,空间占用仅是传统方案 1/5。
04 统一数据分析平台
典型场景:
大数据分析平台可以帮助企业有效地收集内部各种数据,为企业的各个领域(销售、营销、客户服务、运营、财务等)提供数据支持,促进企业决策的科学化和精细化。
现状分析:
传统的大数据平台解决方案包含多种组件,以及多个数据湖查询引擎和数据仓库系统。这些组件的组合可以满足客户的复杂大数据分析需求,包括 ETL、在线报表、即席分析和日志分析等。然而,这种解决方案存在复杂性高、性价比低、实时性差和开放性弱等问题。
如何解决:
▶︎可以通过 SQL 请求实现增量式导入数据湖中的数据,同时通过一套数据仓库系统即可满足 ETL、在线报表、日志分析等多种场景需求。
▶︎通过瑶池数据库 SelectDB 版的联邦查询能力,实现统一的数据湖查询加速方案,可跨多个数据源进行数据查询,满足用户更高效、更灵活的数据处理需求。
▶︎兼容开源 Apache Doris,保证开放性,用户可以继续使用 Apache Doris,并且无缝衔接到瑶池数据库 SelectDB 版。
方案收益:
▶︎可大幅降低计算存储冗余和架构复杂性,同时运维成本非常低、几乎不需要运维投入,不仅如此,使用成本也大幅降低,仅是原方案的 1/5。
▶︎在查询性能方面,相比 Presto 有 3~5 倍的速度提升;在数据 ETL 方面,性能相比 Spark 有 8+ 倍的速度提升。
目前,阿里云瑶池数据库 SelectDB 版正处于邀测阶段,欢迎有需要的企业免费试用体验。您可以点击文末「阅读原文」或扫描下方二维码,登录阿里云账号后提交试用申请表。随后我们将与您建立联系,详细沟通对接试用事宜。
扫码申请



 点击阅读原文申请瑶池数据库 SelectDB 版试用
点击阅读原文申请瑶池数据库 SelectDB 版试用