




点击上方蓝字关注我们

1
文章背景
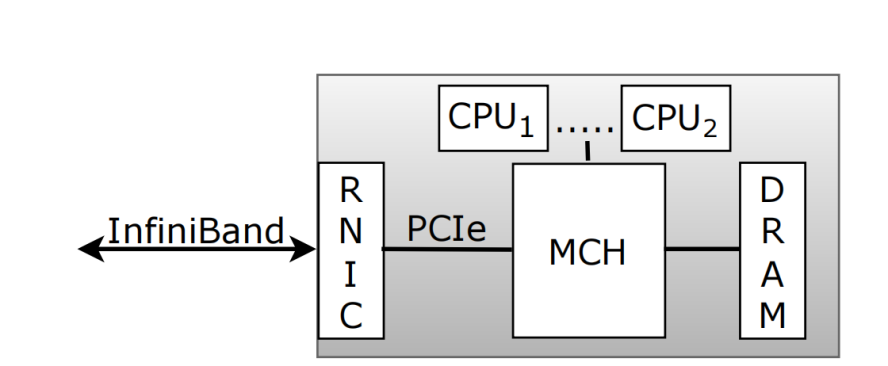
2
单侧RDMA悲观同步实现
2.1
RDMA原子操作性能

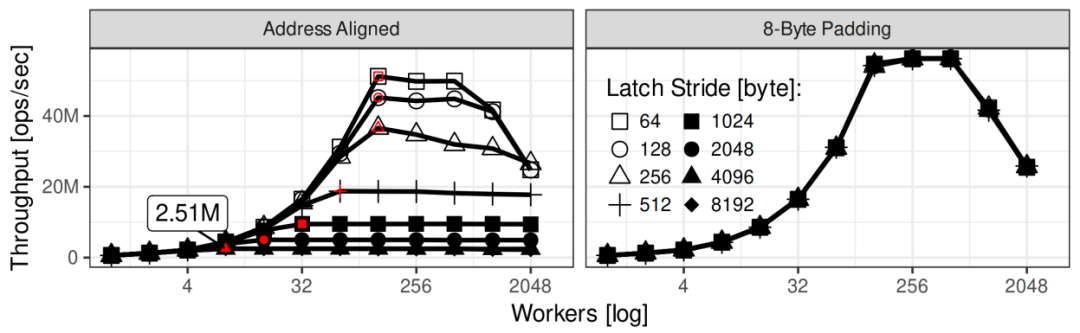

2.2 优化悲观闩锁实现

3
单侧RDMA乐观同步实现
3.1 简单的乐观同步实现
3.2 PCIe的顺序保证
消息的顺序, 单个消息内的数据包的顺序, DMA 顺序。

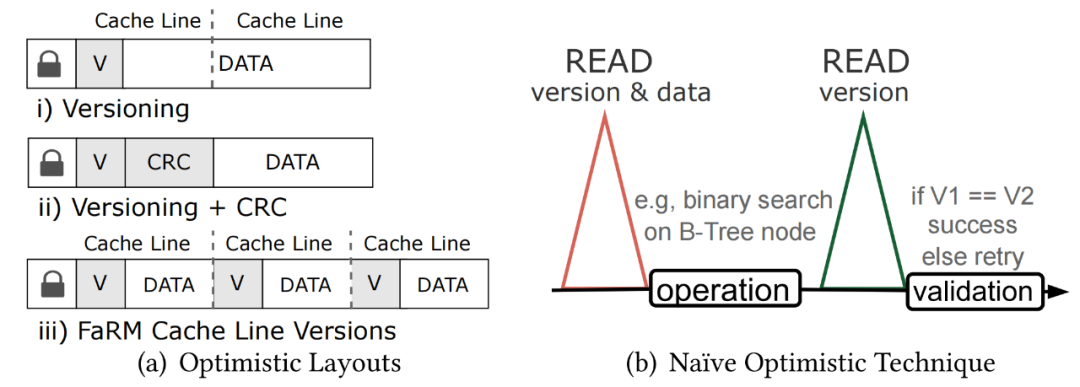
版本控制(两次读,分别获取版本和数据)。这种技术与朴素实现没有太大区别;然而,它要求在开始时需要执行两次串行的RDMA读取。第一个RDMA读仅针对锁和版本,并且仅第二个读才是获取数据。有人或许会想到,是否可以使用类似图5中重叠执行,来屏蔽两次RDMA读的开销。很遗憾,由于读操作很可能在PCIe甚至是网络中重新排序这个优化无法在读操作场景中实现。正确的实现如图7a所示。
CRC+版本控制。该方案通过使用数据校验和来检测不一致性,例如,CRC64,允许工作线程以高概率正确的方式验证数据。如果有并发写入,则损坏的数据不匹配CRC。因此,在最好的情况下,只需一次 RDMA 读取。然而,缺点是(1)CRC的生成是通过计算来实现的,代价昂贵并且(2)它只是基于概率性的。 给每个缓存行附加一个版本信息,从而规避一个额外的专门读取版本与闩锁信息的RDMA操作。附加的代价就是需要检测每个缓存行的版本信息是否一致以及额外的存储空间。
4
总结
单次 RDMA 读取中的缓存行顺序没有保障; 重叠的RDMA读几乎同样没有顺序上的保障; 谨慎的对待将 RDMA 写与RDMA 原子操作相结合的设计。在某些情况下缺乏原子性并不会破坏语义,且可以产生更好的性能; 数据对齐影响 RDMA 原子可扩展性; 乐观同步在高竞争情况下表现最佳; 乐观同步方案有不可忽略的开销; 系统设计者在优先考虑生产稳定性时应倾向于简单的悲观同步,直到社区成功探索了RDMA 读写的明确定义以及相关内存语义。

文章转载自KunlunBase 昆仑数据库,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
