




数据分析处理技术是一项巨大的软件系统工程,架构演变经历了单体、主备、分布式等阶段的迭代后,现在数据处理分析架构来来回回这几种。数据分析的基本构成由数据采集传输、数据清洗转换、数据存储、数据处理等环节组成,分析完最好能够马上推到应用端。下面我们我们探索一下各种数据分析架构的优点和缺点。
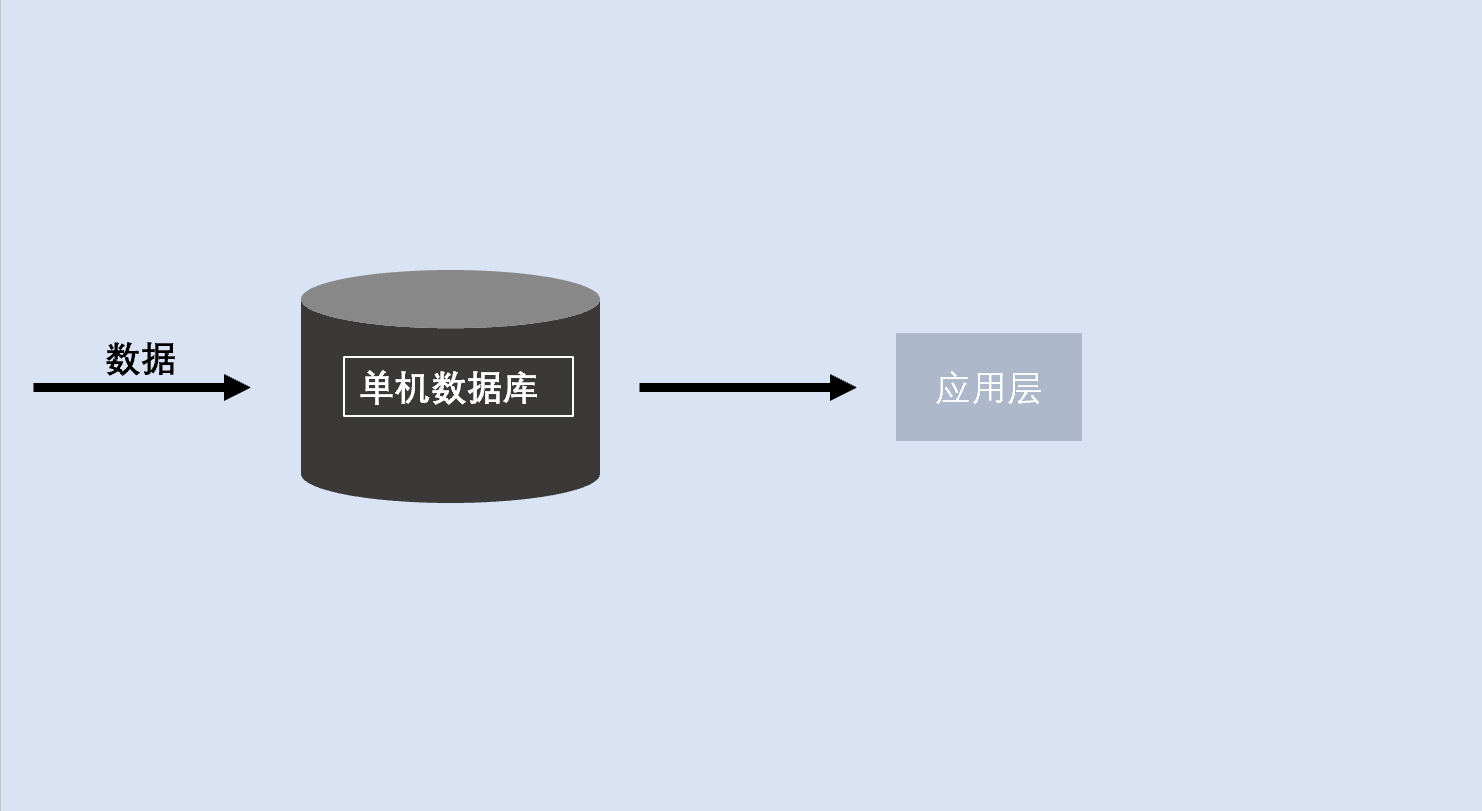
单位数据库架构是指只有一个数据服务器,事务数据和分析数据都在上面,成本低、维护轻、减少运维工作。
数据真实性100%,分析的数据和数据源100%吻合,不考虑数据之间不一致性
随着业务越来越复杂,数据的增加可 读性、可维护性和可扩展性得不到保证
随着系统代码量的剧增,测试、联调、都有可能影响现有的业务系统,难度成指数级增长
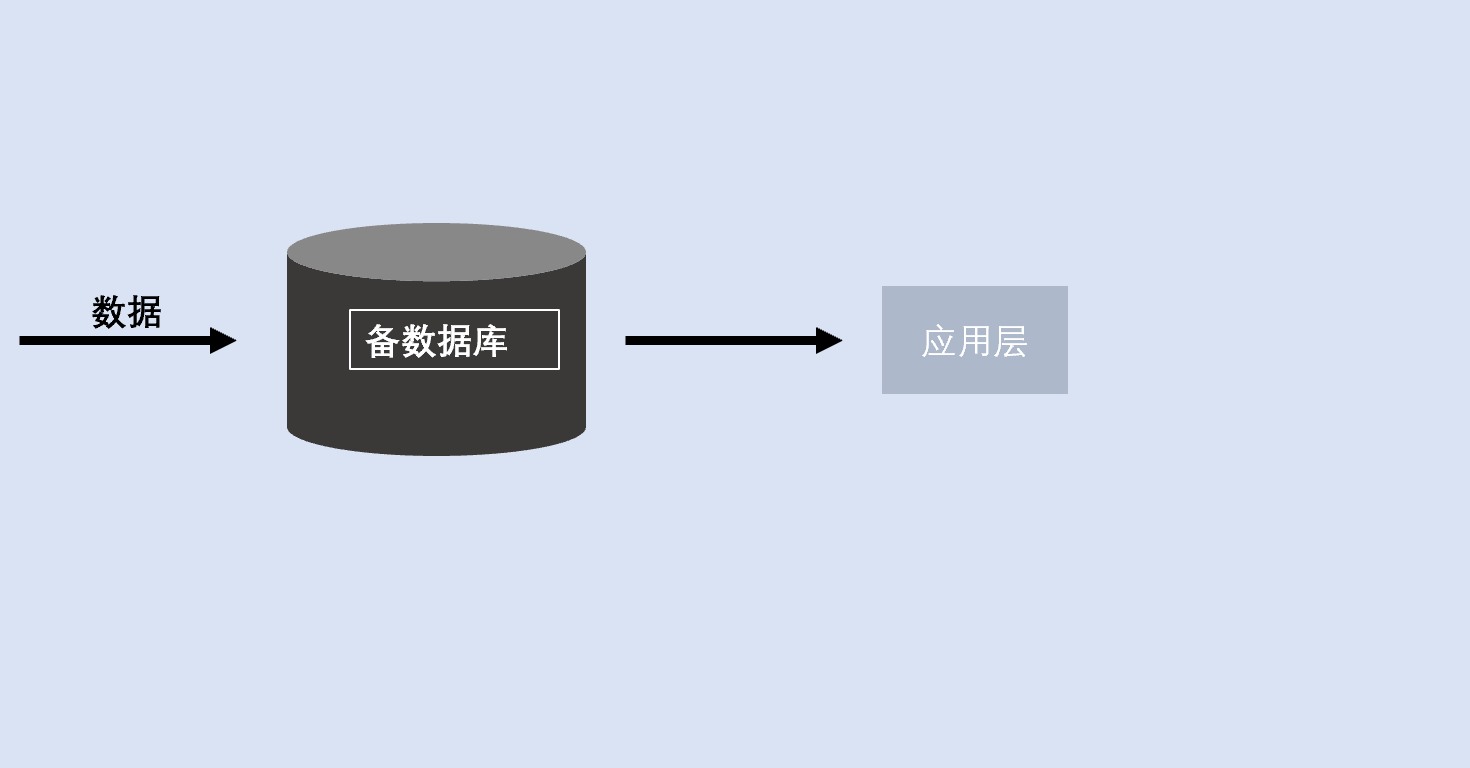
主备数据库架构是指只有两个数据服务器以上,两个数据库之间一主一备,两个数据库近实时同步,主的负责写数据,备的负责读数据。
负载均衡减轻压力,主数据库用来作事务处理,备机除了提供分析业务功能也提供给人查询。
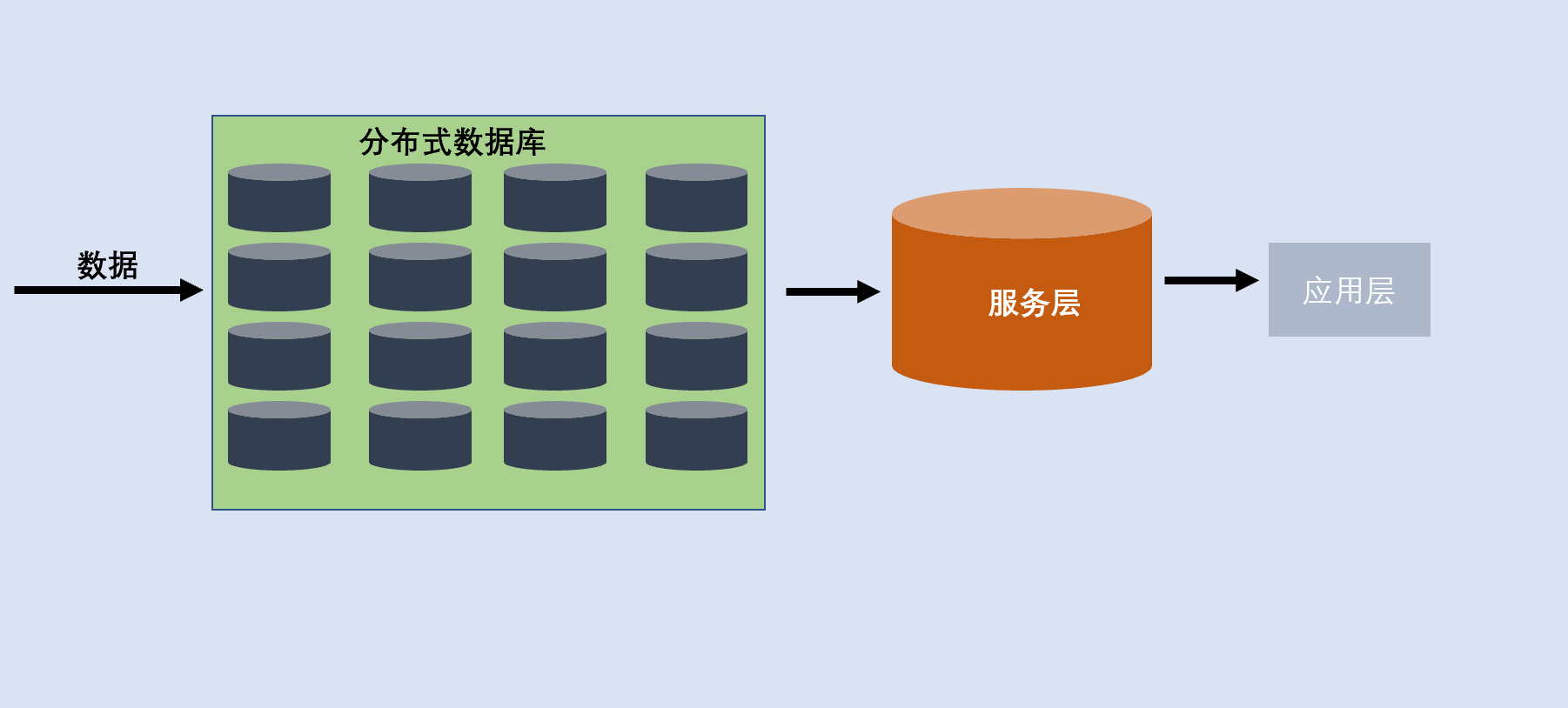
分布式数据库架构是一个集群,通过把分析数据传输到集群,通过把集群的计算能力对数据分析,例如产品Greeplum。
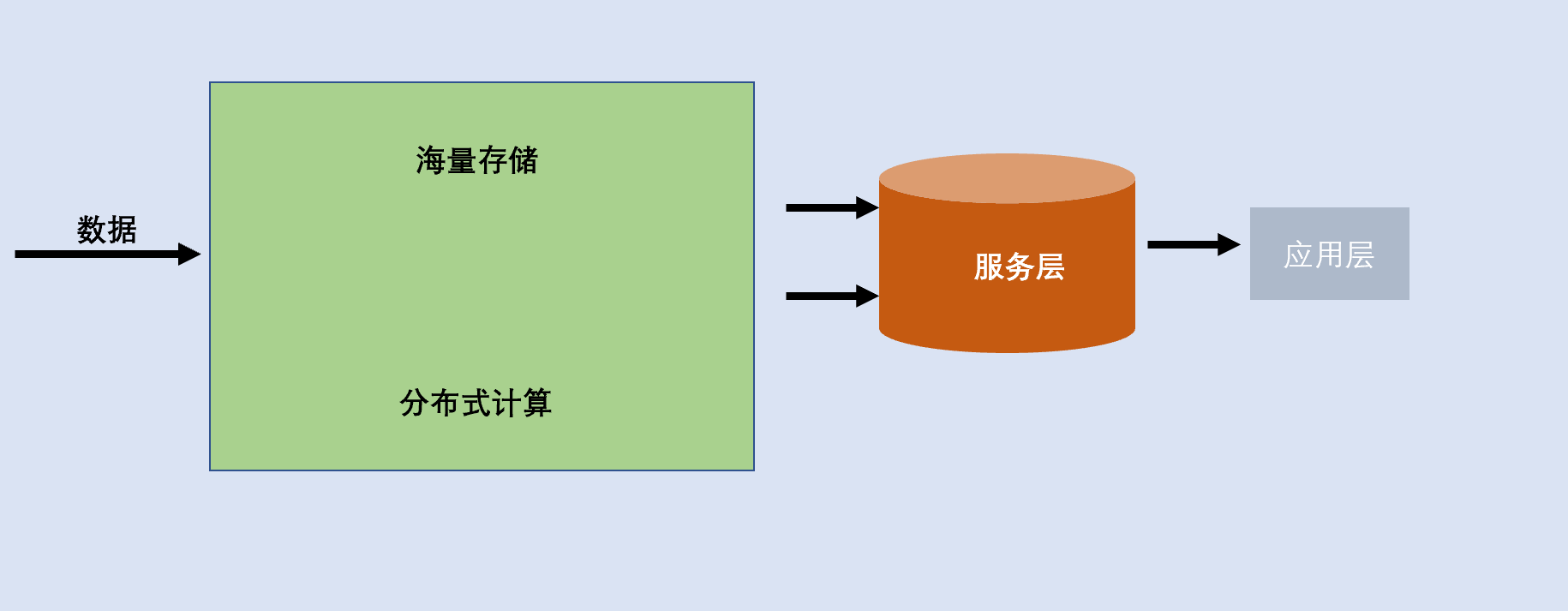
大数据处理架构,经典产品即hadoop,通过提供特殊的文件系统HDFS和分布式处理能力,带来数据处理分析的新思路。后来,陆续出现了多种数据处理引擎,例如Impala、Spark、Flink等等。
在BI和数据管理角度来看,hadoop是一个重量级的解决方案。
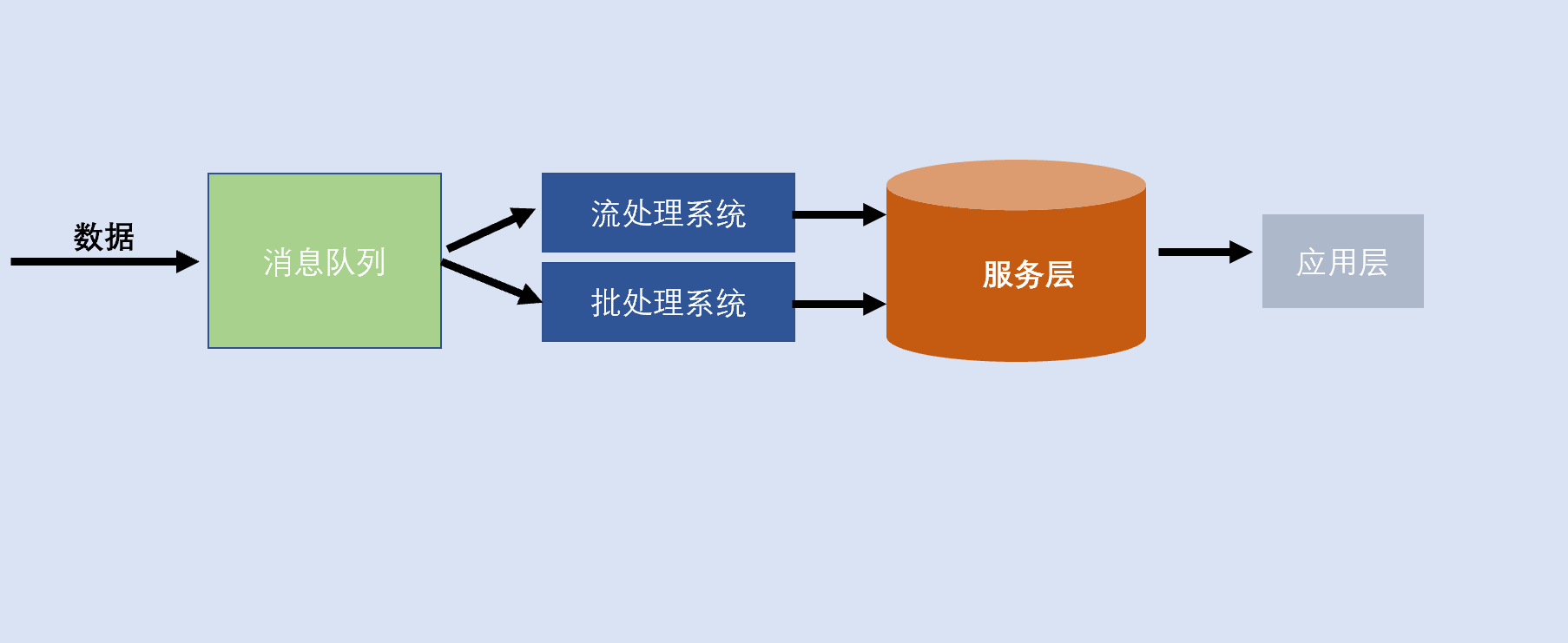
lambda是Lambda 架构由Storm的作者Nathan Marz提出,其设计目的在于提供一个能满足大数据系统关键特性的架构,包括高容错、低延迟、可扩展等。其整合离线计算与实时计算,融合不可变性、读写分离和复杂性隔离等原则,可集成Hadoop, Kafka, Spark,Storm等各类大数据组件。
简言之Lambda架构融合hadoop多种技术组件的优点可以开发高性能的数据仓库系统、企业级数据中台、低延迟的实时数据分析平台等。
两套系统并行,同一个数据可能会被两套系统都处理过,导致执行结果不一样。
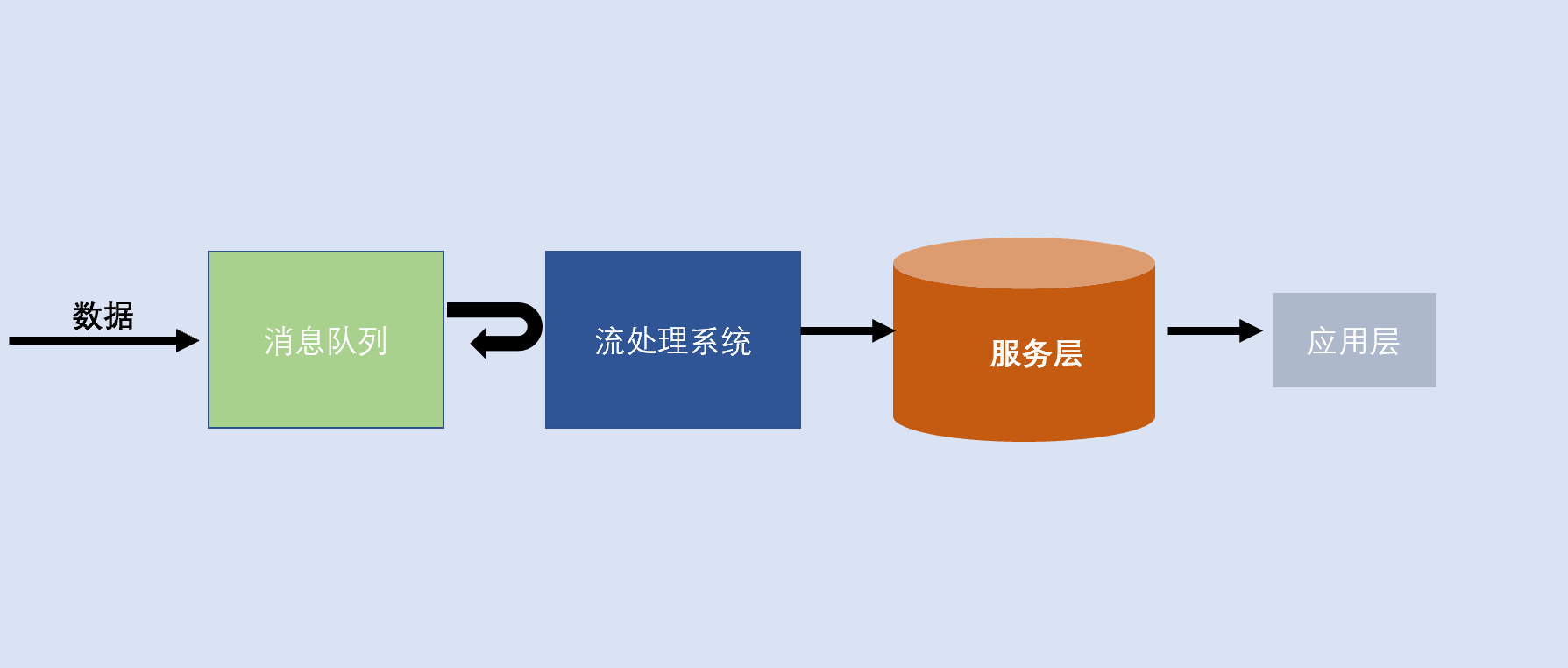
Kappa 架构是由 LinkedIn 的前首席工程师杰伊·克雷普斯(Jay Kreps)提出的一种架构思想。目标是改进 Lambda 架构中速度层的系统性能,使得它也可以处理好数据的完整性和准确性问题。通过改进 Lambda 架构中的速度层,使它既能够进行实时数据处理,同时也有能力在业务逻辑更新的情况下重新处理以前处理过的历史数据。
Kappa和Lambda 都是在大数据处理架构基础衍生出来框架架构,广泛应用于建设各种分析就有和,包括数据中台、数字化转型应用、企业大屏、高性能数据服务平台、实时知识库共享平台、生产制造数据展示平台等等。
两套系统并行,同一个数据可能会被两套系统都处理过,导致执行结果不一样。
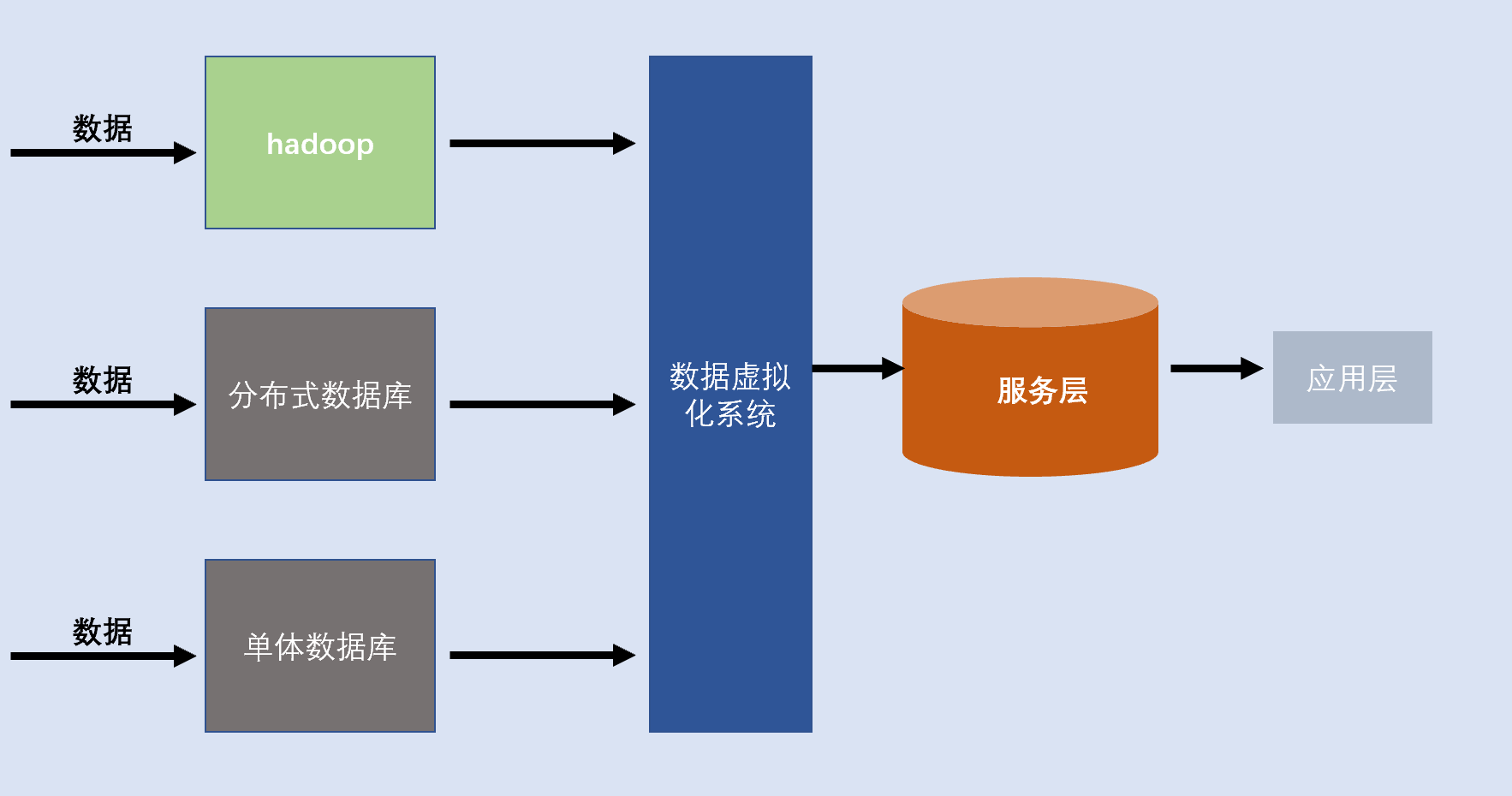
数据虚拟化是指隐藏底层数据源(关系型数据库、NOSQL、NEWSQL、数据仓库)等技术访问细节,将数据源的抽象和聚合要求将物理资源抽象出来,对外为用户提供一个统一的数据接口。
我们可以将数据虚拟化理解拥有强大实力的二手房子代理商,通过它我们可以买卖碧桂园、恒大、万科的房子,由头到尾我们不需要与地产商打交道,只需要与代理商打交道,遇到麻烦的事,也是代理商和地产商互动。
