




未来数据分析行业发展之路,是数据产业和传统产业共同关心的话题。
过去的20年里,中国从信息行业飞速发展,各个领域如移动通信、制造、医疗保健以及金融公司都出现了大规模的数据增长。另外,随着微博微信、社交网络、传感器等新型的信息产出,以及云计算、物联网、云原生新兴技术的出现,数据正在以前所未有的速率增长积累。如何将这些数据打通共享,融合分析,挖掘这些数据的潜在价值,是数据分析行业面临的关键问题。
数据分析技术演进路线之Hadoop
10年前,hadoop为解决大数据难题诞生,通过提供一体化完整的生态工具给用户解决数据分析的难题。过去的十多年里面深刻影响了信息行业,但着随着新兴技术的不断涌现,新的数据分析产品clickhouse不依赖hadoop生态,2018年全球第一的CDH与全球第二的HDP合并为CDP, hadoop市场萎缩,直至2021年6月1日,KKR与CD&R拟47亿美元收购Cloudera。hadooop是不是不行了?作为大数据分析的掌门人挂了,谁能代替hadoop?以后用什么技术和产品进行大数据分析?这些都是大家关心的话题。
前事不忘后事之师,先了解hadoop的作用功能。hadoop拥有多种组件满足各种大数据业务场景需求,首先hadoop核心组件HDFS 支持数据存储,满足海量数据。另外MapReduce 和 Spark 做数据计算和处理,sqoop 负责数据采集,kafka可做数据源存储, hbase可做列式数据库,Impala和Tez负责即席查询。特定场景的信息管理系统可以移到 hbase来做,hbase积蓄了大量数据,由于本身就在hadoop系统里面,ETL搬迁数据更节省时间。对于全量数据和批处理,hadoop提供批处理能力和流处理能力 ,另外具备数据流程工具管理任务。分析中的数据可以观看执行状态,分析后的数据有迹可循。另外数据血缘和数据权限管理工具,hadoop都一一满足。早期hadoop凭借着批处理能力能够实现多个廉价服务器计算一个巨大的数据量任务,吸引中小企业的眼光,占领了大部分的数据分析市场。现在的问题出在哪里?
一个考虑周全、面面俱到的解决方案必然是复杂性牺性代价的。客户只需要一碗水,你给一条大江,还要给客户去拿,显然产品的体验不舒适。hadoop集群的搭建大费周章,而且集群维护需要专业人士,产品虽然稳定可靠,但是可用性和运维性差,入门的门槛高,学习的成本高,这是一部分企业不采用hadoop的原因。即使最新版的hadoop3,功能乏善可陈,最大的特性是压缩使用了磁盘空间,没有其它亮点,在hadoop的产品路线图里面,hadoop已经没有想着怎么创新功能 ,主要内容是怎么集成支持k8s\docker等系统。hadoop的创新走到尽头了。
数据分析技术演进路线之新型数据平台
追溯数据分析的历史,数据产生都是第一时间保存在数据库里面,数据内容不多,完全可以在数据库里面分析。如果数据量太大,数据库处理必须占用太多资源,分析时会影响数据库的正常使用,才非常有必要把数据集成到其它数据产品。
用户更希望一个轻量的、统一的数据平台,底层屏蔽数据源细节,本身拥有把物理数据资源抽象出来的能力。
其它人是怎么做的,大数据分析公司新锐代表,美国有扎根深厚的databrick和上市不久的snowflak。databrick是spark技术运营的母公司,等于是spark的商业版应用,主要领域是通过云服务和云平台的方式向用户提供数据挖掘分析服务。上层提供了一个功能丰富又简单的交互式 Notebook,用户可以直接手写 Python,Scala 或 SQL 进行数据分析和挖掘,底层计算使用 Spark,存储使用 Delta 对接云存储服务,实现一致性和事务性。
Snowflak是数据分析市场的独角兽。2020年9月,Snowflake在纽约证券交易所上市,紧接着,它迎来了一个又一个高光时刻,上市首日股价大涨超110%,估值翻了一番多,从330亿美元增至700多亿美元,并一举成为了美国有史以来IPO规模最大的一家软件公司,上市的时候股价曾一度飙涨到每股 400 多美金。易用性是让 Snowflake 身价暴涨的一个重要原因,Snowflake 是一个把数据仓库做成 SaaS 服务的软件供应商,这种完全托管的服务对于用户使用变得非常简单。
数据分析技术演进路线之数据虚拟化
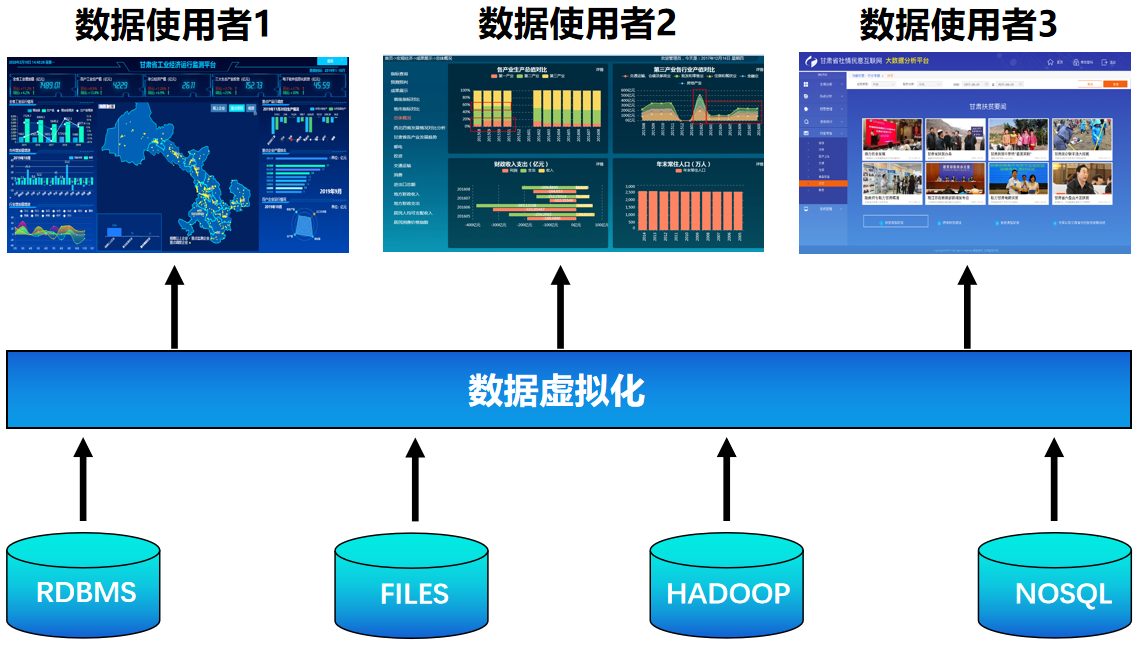
是什么使他们受到了资本市场的追捧?无非两点原因,第一是基于流行的公有云平台,产品具有使用简单、弹性伸缩、按量计费、灵活取用等特点。第二是基于创新型的技术,下面我们统称为数据虚拟化技术,通过屏蔽底层数据源细节,对外给客户提供统一简洁的界面,既提高客户产品使用的舒适性,又最大化发挥数据产品的性能。databrick除了我们耳熟能详的批流一体化能力对海量数据进行全量处理或增量更新,另外还能支持连接不同的数据源,能够实现不同源的数据汇聚整合。 在第一批的数据访问提炼后,把数据缓存起来快速响应后续的访问。众所周知,databrick的数据处理引擎用的是spark,那么Snowflake的数据处理技术是什么,批处理?流处理?索引?分区?缓存? Snowflake作为数据仓库的SaaS服务领导者,必然是多种数据处理技术协同共存,针对不同的需求完成不同数据处理智能调度。不同的数据使用者统一与虚拟层打交道 ,请求却指向不同的数据源。
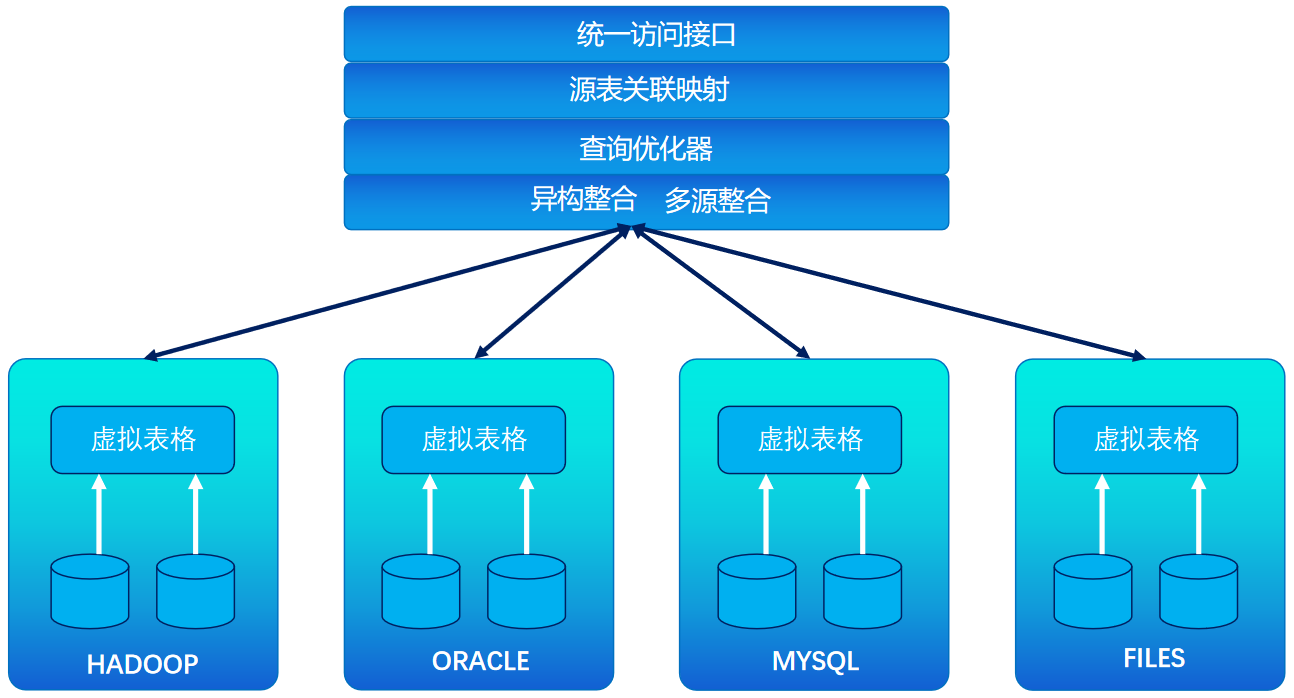
1.统一数据语言的标准化和转换层,对外提供SQL,屏蔽Python、Scala 、Java各种语言。
2.统一元数据标准规范,比如表格的结构、转换和清洗操作、聚合等 。当使用数据虚拟化时,元数据规范只需要被执行一次,不需要把它们复写给更多的数据消费者。换句话说,数据消费者共享和重复使用这些规范。
3.统一数据存储中心,支持从多个数据存储区中集成数据,具备数据下推往数据源执行的能力。
数据虚拟化是指隐藏底层数据源(关系型数据库、NOSQL、NEWSQL、数据仓库)等技术访问细节,将数据源的抽象和聚合要求将物理资源抽象出来,对外为用户提供一个统一的数据接口。用户在定义数据源的初始化配置文件后,能够自由查询和操作各个目标源的数据源,一言简之,数据虚拟化技术实现前端与后端多源异构的解耦,轻量级简单解决数据集成多源异构的困难。
简言之,数据虚拟化对外实现了高可用性和高易用性,对内实现了多种处理技术协调共存,具备多源异构的数据处理能力。
