Pgvector是一个使得PgSQL具有向量数据库能力的开源插件,之前pgvector出来后,仅支持IVFFlat索引。随之马上又出现了pg_embedding插件支持HNSW索引,比pgvector性能高20倍。Pgvector的迭代速度够快,马上也加入了对HNSW的支持。Pgvector0.5版本支持的新特性:支持HNSW索引;更快的距离计算;并行构建ivfflat索引。1、新的索引类型:Hierarchical Navigable Small Worlds(hnsw)
Pgvector0.5版本最大的亮点就是引入了hnsw索引。Hnsw索引基于论文《hierarchical navigable small worlds》,该论文描述了创建密集近邻向量层的索引技术。Hnsw的要旨是:通过连接彼此相邻的向量达到更好的性能和召回率。因此当执行近似查询时,能够更准确地找到最接近的邻居。除了性能外,pgvector的hnsw还有以下几个显著特点:“build as you go”:可以在空表上创建一个hnsw索引,然后在不影响召回的情况下添加向量。这点不同于ivfflat,在构建索引之前需要先加载向量,以找到更好的召回中心。向ivfflat索引添加更多数据后,可能说重建索引以找到更新的中心。更新和删除:pgvector的hnsw支持更新和删除。很多其他hnsw的实现并不支持这个功能。并行插入:支持并行向索引中插入,可以更加人容易地从多个来源同时加载数据。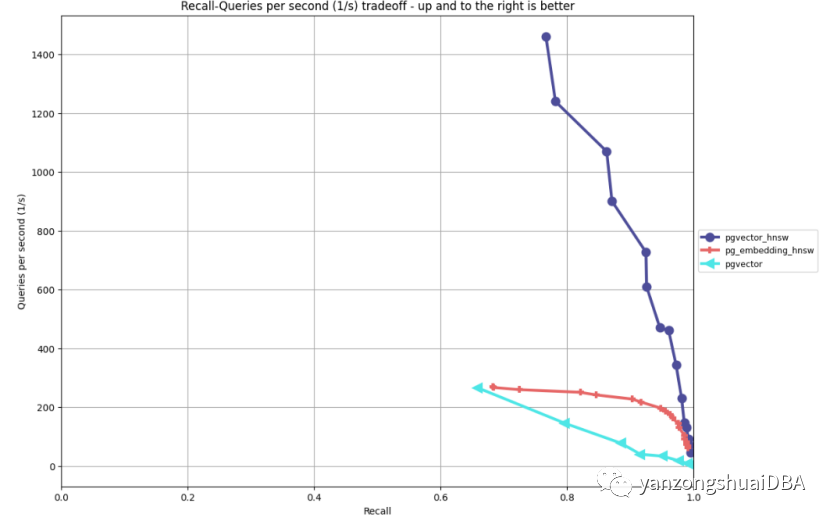
上图为jonathan katz的ANN benchmark的性能对比结果。这里侧重如何使用hnsw的关键参数以理解对性能/召回率和索引构建的影响。索引构建选项
该选项在CREATE INDEX的WITH语句中:CREATE TABLE vecs (id int PRIMARY KEY, embedding vector(768));
CREATE INDEX ON vecs USING hnsw(embedding vector_l2_ops) WITH (m=16, ef_construction=64);
nm:(默认16,范围2-100),表示在每个索引元素之间存在多少双向链接(或路径)。将该值设置为一个较高的数量,可以增加召回量。但也会显著增加索引生成时间,并可能影响查询性能。nef_construction:(默认64,范围4-100),表示在索引中添加元素时,需要检查的近邻数。增加该值可以增加召回量,但是会增加索引构建时间。该值必须至少是m的两倍。如果m是24,那么ef_construction就得是48.注意,必须要指定使用hnsw索引的操作符类。例如使用hnsw索引的余弦,可以使用下面类似的命令:CREATE INDEX ON vecs USING hnsw(embedding vector_cosine_ops);
索引查询的选项
hnsw.ef_search:默认40,范围1-1000,表示在进行搜索时,将这么多的近邻放到“dynamic list”中。一个较大的值会增加召回量,通常需要和性能进行平衡。该值至少需要和LIMIT值一样大。如何使用hnsw
选择默认的索引构建配置项来优化构建时间。如果没有得到数据集的预期召回量,在调整m前先增加ef_construction值,因为调整它通常比较快。可以通过设置较小的hnsw.ef_search值来增加查询性能,比如设置成20:SET hnsw.ef_search TO 20;
SELECT *
FROM vecs
ORDER BY q <-> embedding
LIMIT 10;
2、改进了距离函数的性能
速度是计算两个向量之间距离的首要考量。任何减小计算时间的方法都意味着可以使索引构建和向量查询更快。Pgvector0.5全面改进了距离计算,并为ARM64体系架构带来了显著的增益。默认,pgvector可以通过编译标记使用CPU加速进行向量处理,并以某些方式编写代码帮助在编译后解锁性能收益。0.5版本的增益非常可观。使用1,000,000 个768维向量PLAIN模式存储的表,在mac m1 pro(2021版,8CPI,16GB RAM)进行Euclidean(vector_12_ops或者默认操作符类)和cosin 距离(vector_cosin_ops)测试。CREATE TABLE vecs (id int PRIMARY KEY, embedding vector(768));
ALTER TABLE vecs ALTER COLUMN embedding SET STORAGE PLAIN;
shared_buffers: 4GB
max_wal_size: 10GB
work_mem: 8MB
max_parallel_mainetance_workers: 0
测试前,确保数据已加载到内存,使用pg_prewarm插件进行预热:SELECT pg_prewarm('vecs');
最后创建lists设置为100的ivfflat索引。注意,这是为了快速执行一系列测试,推荐值是:1000000行推荐1000。lists值越大距离计算的影响越大。下面是测试结果。这些结果具有方向性,特别是lists值:上面的测试显示,Euclidean距离和cosin距离都有了显著提升。Andrew Kane在ARM64系统上测试显示,所有距离函数都有显著提升。也就是说,可以在您的pgvector工作负载中看到一些性能提升,其中最显著的是许多距离计算任务,例如建立索引,在大量向量上搜索。3、ivfflat索引并行创建
ivfflat构建索引更快。一种方式就是并行执行。为了理解并行带来的好处,看下索引构建的不同阶段:CREATE INDEX ON vecs USING ivfflat(embedding) WITH (lists=100);
k-means:pgvector采样表中所有向量的一个子集,从而决定k中心。k是lists值。上面查询中k是100;assignment:pgvector扫描表中每项记录,并将其分配到最近的lists中,使用选择的距离操作(例如Euclidean)计算距离Sort:然后pgvector对每个list中记录进行排序write-to-disk:最后,pgvector将索引写到磁盘。1)k-means:k-means计算量很大,但它很容易并行2)assignment:在分配阶段,pgvector必须从表中加载每个记录,如果表很大,会耗费很长时间。围绕索引构建阶段耗费时间最多的地方进行分析,耗费最多地方是assignment阶段,特别是随着索引集规模增加。虽然k-mean中花费的时间随着lists数量二次方增长,但与assignment相比,这仍然只是花费时间的一小部分。有趣的是,整个测试中,写入磁盘的时间占时间的百分比保持相对稳定。Pgvector0.5.0在assignment阶段增加了并行,特别是发起多个并行worker扫描表并将记录分配到最近的list。需要关注下PG的几个参数:1)max_parallel_maintenance_workers:PG维护操作比如索引构建中并行进程最大个数。默认2,可以适当调大2)max_parallel_workers:PG并行操作最大并行进程。默认8,可以根据并行需求,和max_parallel_maintenance_workers一起调大3)min_parallel_table_scan_size:最少扫描这么多数据才会发起并行进程。如果对vectors使用extended/toast存储,则不能并行扫描表。因为PG仅考虑主表的大小,而不是toast表。这个值设小点,可以帮助你发起并行。下面是768维的1000000个vectors的一个并行例子:CREATE INDEX ON vecs USING ivfflat(embedding) WITH (lists=500);
DEBUG: building index "vecs_embedding_idx" on table "vecs" serially
CREATE INDEX
Time: 112836.829 ms (01:52.837)
SET max_parallel_maintenance_workers TO 2;
CREATE INDEX ON vecs USING ivfflat(embedding) WITH (lists=500);
DEBUG: using 2 parallel workers
DEBUG: worker processed 331820 tuples
DEBUG: worker processed 331764 tuples
DEBUG: leader processed 336416 tuples
CREATE INDEX
Time: 61849.137 ms (01:01.849)
SET max_parallel_maintenance_workers TO 8;
CREATE INDEX ON vecs USING ivfflat(embedding) WITH (lists=500);
DEBUG: using 6 parallel workers
DEBUG: worker processed 142740 tuples
DEBUG: worker processed 142394 tuples
DEBUG: worker processed 142192 tuples
DEBUG: worker processed 142316 tuples
DEBUG: worker processed 142674 tuples
DEBUG: leader processed 142284 tuples
DEBUG: worker processed 145400 tuples
CREATE INDEX
Time: 67140.314 ms (01:07.140)
可以看到,对于这个数据集,最大能提升2倍。这个功能在哪里可以缩短时间?看几个不同阶段的比较:1,000,000 768-dim vectors, lists=1000整体上有2倍以上提升,assignment阶段有6倍提升,排序会有显著下降。添加更多vectors:5,000,000 768-dim vectors, lists=2000可以看到,assignment阶段节省最多时间,尽管注意到排序时间大约是线性的。最后看个非常大的例子:100,000,000 384-dim vectors, lists=10001)通常会用一个更大的list来在数据集中驱动一个更好的性能/召回率2)主要使用不同的max_parallel_maintenance_workers,这个数据集来说最优值323)最后在write-to-disk阶段完成前停止了测试,但是趋势是比23小时要快4、其他特性
1)SUM聚合:可以对vectors进行sum聚合:SELECT sum(embedding) FROM vecs;2)Manhattan / Taxicab / L1距离:该release增加了l1_distance函数,可以在两个vectors中找到Manhattan距离3)元素乘法:SELECT '[1,2,3]'::vector(3) * '[4,5,6]'::vector(3).可以通过ALTER EXTENSION vector UPDATE;或者ALTER EXTENSION vector UPDATE TO '0.5.0';进行版本升级5、原文
https://jkatz05.com/post/postgres/pgvector-overview-0.5.0/





