






MVP 手把手
检索增强生成 (Retrieval Augmented Generation, RAG) 是最现实的 GPT 落地场景之一。在使用 Azure OpenAI 的“Add your data”(添加您的数据)实现 RAG 和 Azure ML Studio 的在线搜索提示流之外,我们还可以尝试使用 Azure ML Studio 的“Bring You Own Data QnA”(用您自己的数据来问答)。

01
创建提示流之前,先创建“矢量索引”。我们的矢量索引准备使用认知搜索,所以首先需要创建一个到 Azure 认知搜索的连接。
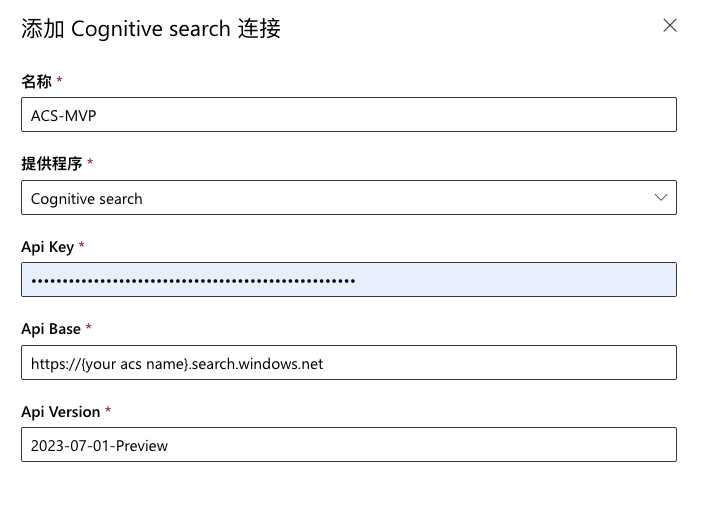
如果还没有在 Azure 中创建 Azure Cognitive Search 认知搜索资源,请先创建一个非免费定价层的。接着在提示流中,点击“连接”页签,点击“创建”下拉按钮,选择“Cognitive Search”。在向导中输入连接的名字,选择提供程序为“Cognitive search”,输入认知搜索的 API Key。注意要使用 Admin 的管理 Key 而不是 Query 的查询 Key,否则后续创建索引会失败。最后输入 API 的终结点地址,保存连接。
接下来就可以创建矢量索引了。
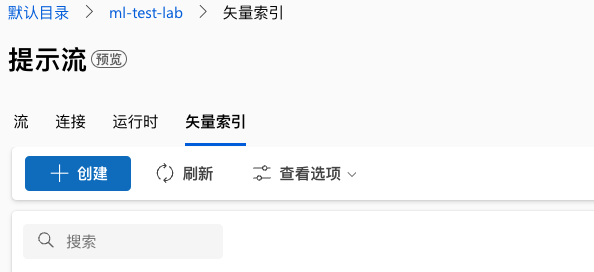
创建新的矢量索引可以使用本地存储(这个本地应该指的 Azure 里,因为上传的数据会存在 Blob 存储)或注册的数据资产(意味着之前处理过的数据可以标记为数据资产并复用,例如我们后面创建成功的矢量索引)。
我们先来创建一个使用“本地存储”的 Azure 认知搜索的矢量索引。
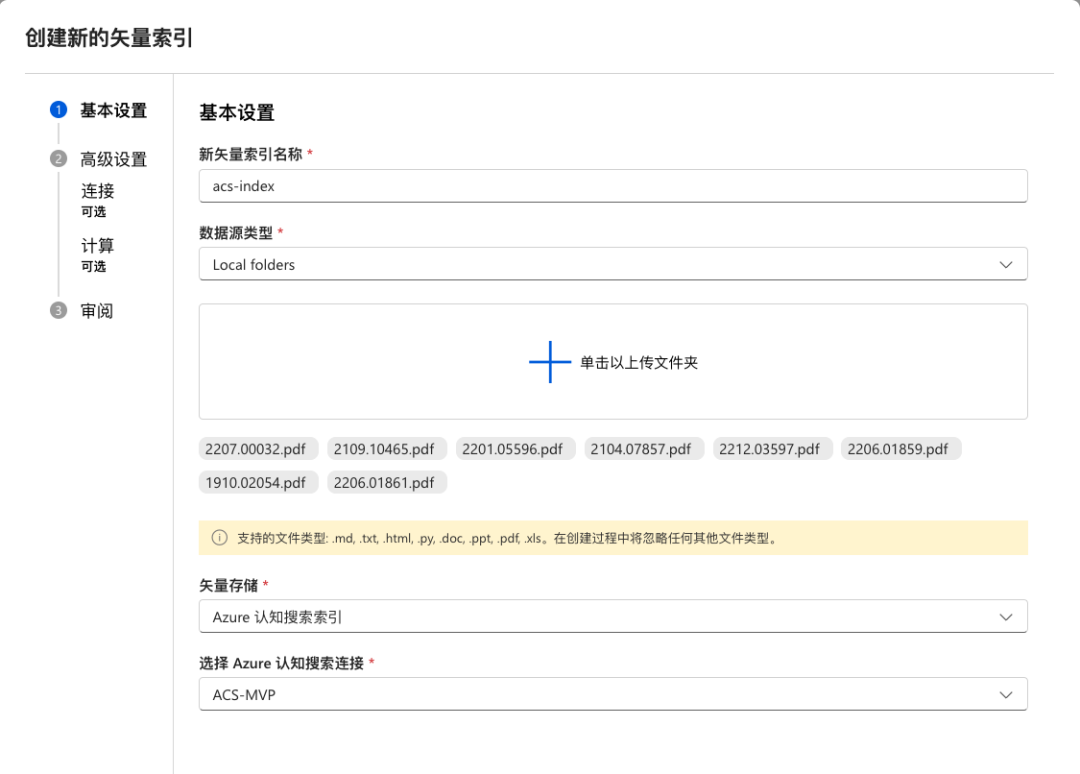
与 AOAI Studio 不同,该向导直接选择上传文件夹。文件将会被上传到一个 Blob 存储容器,再进行处理。下一步提供 Azure OpenAI 的连接。Azure OpenAI 连接让矢量索引可以调用 Embedding 模型。
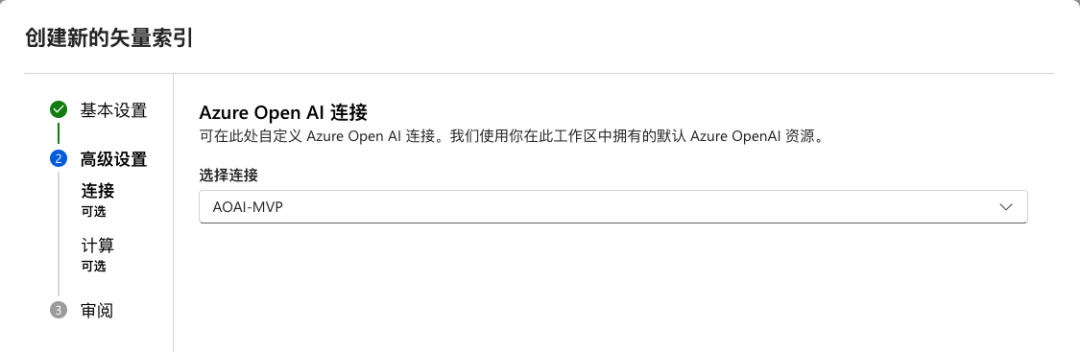
接下来需要确定使用的计算资源。默认使用无服务器计算(serverless),也可以选择计算群集。
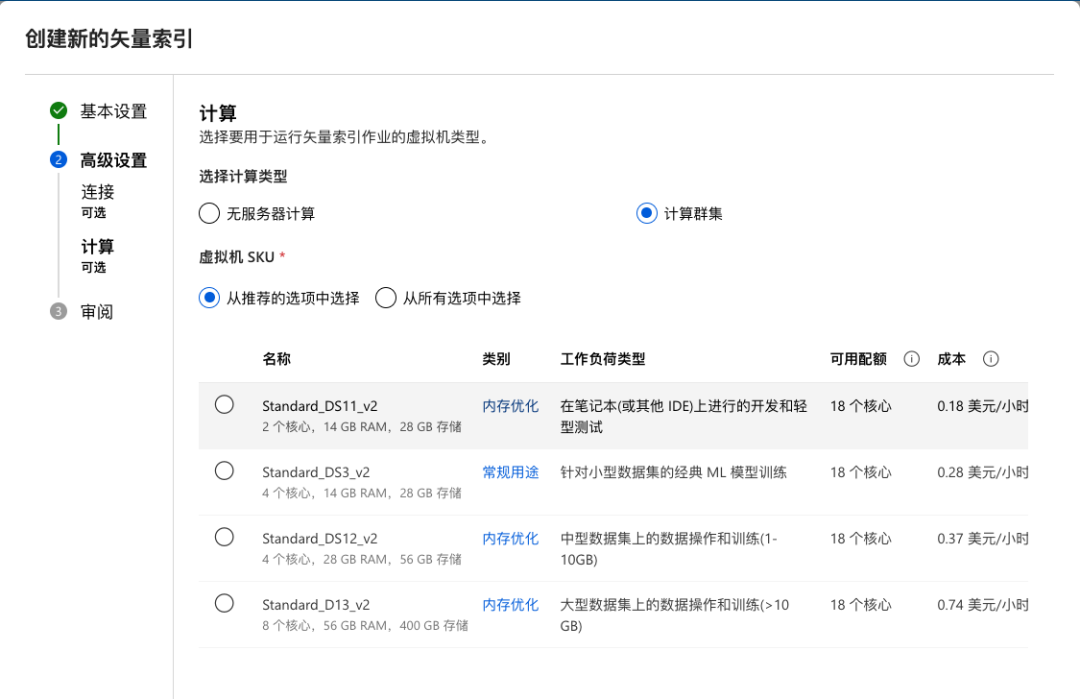
准备工作基本完成。点击“创建”按钮之后,Azure ML Studio 实际上会提交一个作业(Job)来完成整个矢量索引的创建过程。对于这个过程,ML Studio 会像以前我们所熟悉的一样,构建一个管道线来执行。自动生成的矢量索引作业管道线图如下:
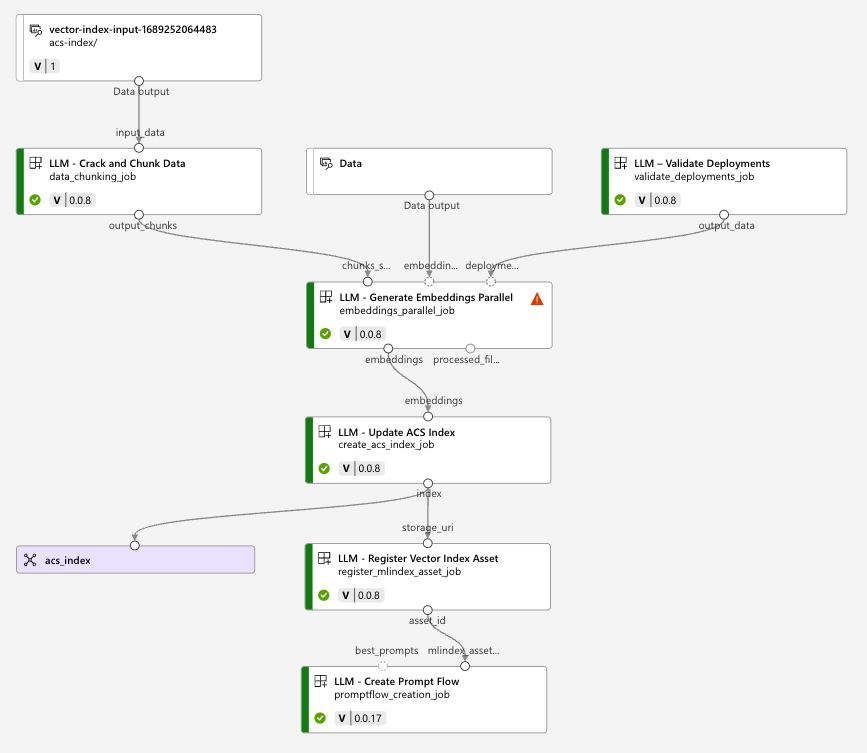
可以看到,上传的文件首先被存放在存储容器,之后对这些文件(示例上传的是 PDF 文件)进行破解和裁剪。在管道线的右上角,组件会对提供的 AOAI 连接进行验证,以确保是否支持 Chat 的模型和 Embedding 的模型。
管道线会将这两个组件模块的输出提供给并行生成 Embedding 的组件模块,对分块的文件进行嵌入,得到矢量空间。完成后,就可以使用矢量数据在 ACS 认知搜索创建矢量索引。创建完成,我们就得到了可以使用的矢量索引“acs-index”。这还没有结束,管道线会继续运行,将生成的矢量索引注册为矢量索引资产,便于其他过程复用。最后,利用生成的矢量索引,管道线会自动创建提示流。
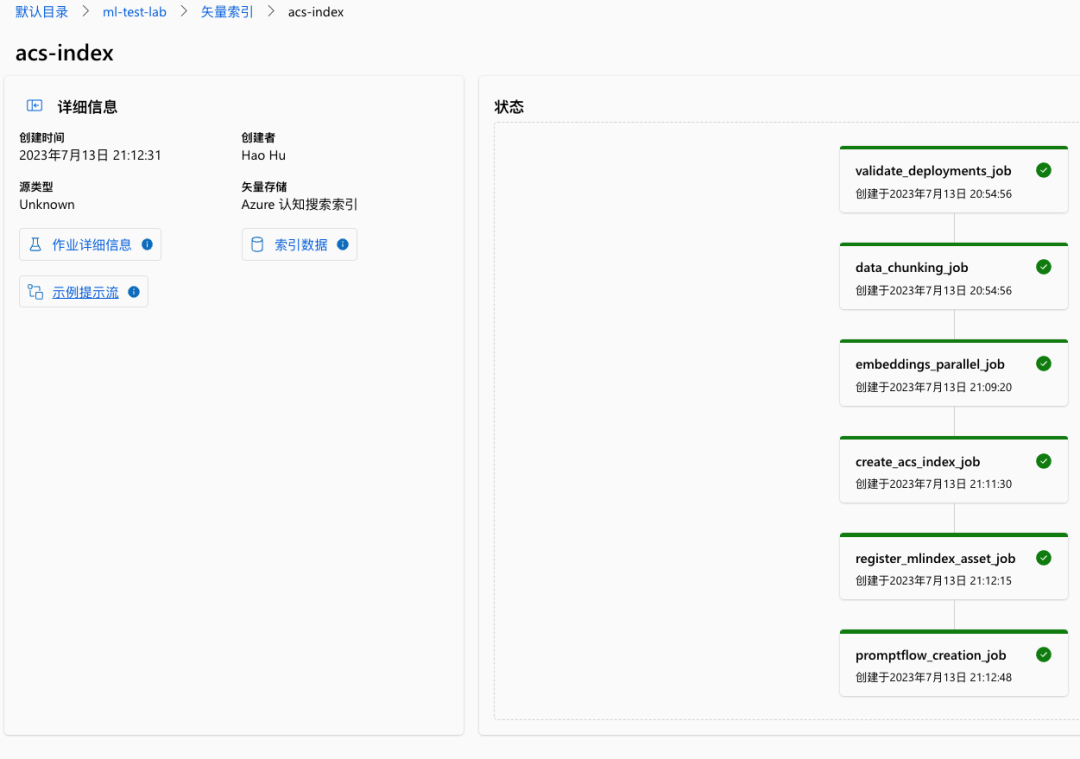
创建完成的矢量索引可以查看整个作业的详细信息,可以查看索引数据(在Azure ML使用的 Blob 存储中),也可以直接打开关联的示例提示流。同时也会显示整个管道线各作业模块的完成情况,是否出错等等。
02
点击“示例提示流”看看生成的提示流是否正常工作。
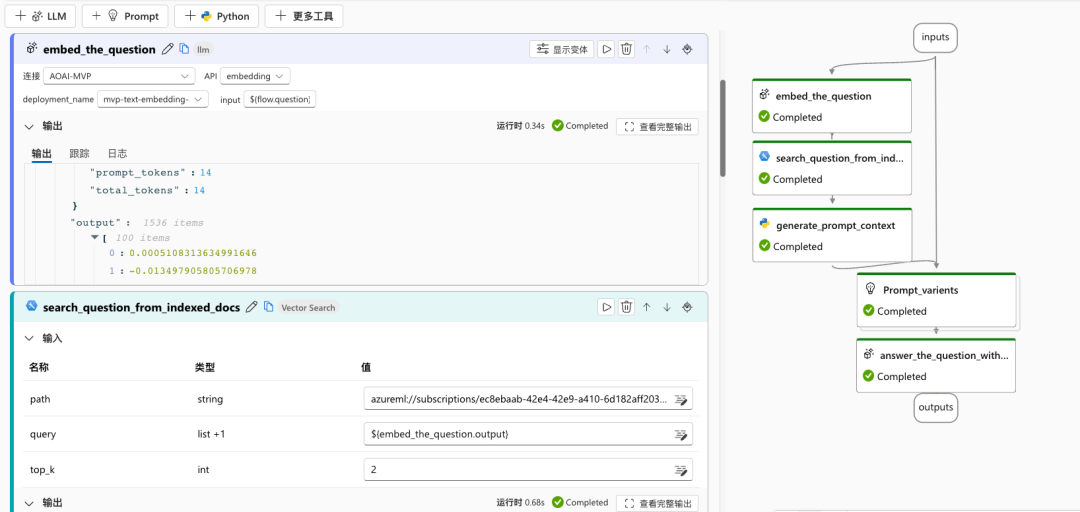
打开提示流,在输入(inputs)组件处输入我们的问题,并运行整个提示流。
“embed_the_question”组件模块会首先调用 AOAI 中支持 embedding 的模型来做嵌入。因为我们的查询是基于矢量空间余弦相似度来进行的,所以要把提问转为嵌入的矢量来和矢量索引进行比较。可以看到这一组件模块的输出已经是 1536 维的矢量。
下一模块“search_question_from_indexed_docs”会在我们已经准备好的矢量索引中查找。请注意,这里的 path 参数不再是我们开头说的“占位符”,而是真实的经过索引之后的路径。改变 top_k 会对向量搜索产生影响。
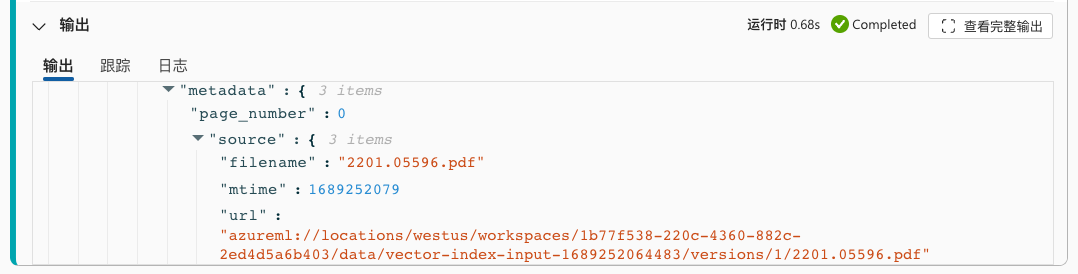
在这一组件模块的输出,可以看到基于矢量索引搜索到的结果,例如搜索到的文档的 url。这里的文档 url 已经是 blob 存储的别名路径。在后续使用这些数据来交谈的时候,就需要这些 url 来指示数据来源。
有了矢量搜索结果,接下来就可以生成提示内容了。在“generate_prompt_context”组件模块中,将使用 Python 代码,将搜索结果转变为可以用作对话提示的文本。这个文本包含内容和来源两部分信息,并且不同条目间使用换行间隔。
from typing import Listfrom promptflow import toolfrom embeddingstore.core.contracts import SearchResultEntity@tooldef generate_prompt_context(search_result: List[dict]) -> str:def format_doc(doc: dict):return f"Content: {doc['Content']}\nSource: {doc['Source']}"SOURCE_KEY = "source"URL_KEY = "url"retrieved_docs = []for item in search_result:entity = SearchResultEntity.from_dict(item)content = entity.text or ""source = ""if entity.metadata is not None:if SOURCE_KEY in entity.metadata:if URL_KEY in entity.metadata[SOURCE_KEY]:source = entity.metadata[SOURCE_KEY][URL_KEY] or ""retrieved_docs.append({"Content": content,"Source": source})doc_string = "\n\n".join([format_doc(doc) for doc in retrieved_docs])return doc_string
以下是 Github Copilot X 对上述代码的解释:
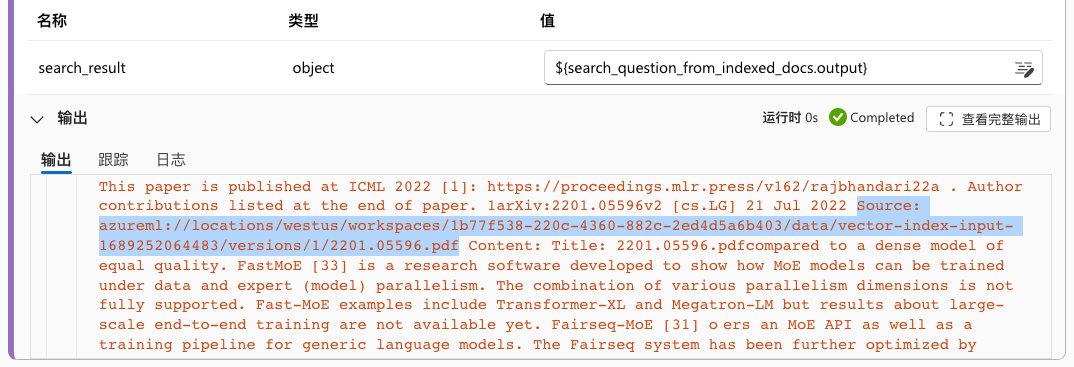
运行完这个组件模块之后,就会输出一大段文本,可以看到,来源的文件 url 和前面提到的 Blob 存储路径一致。
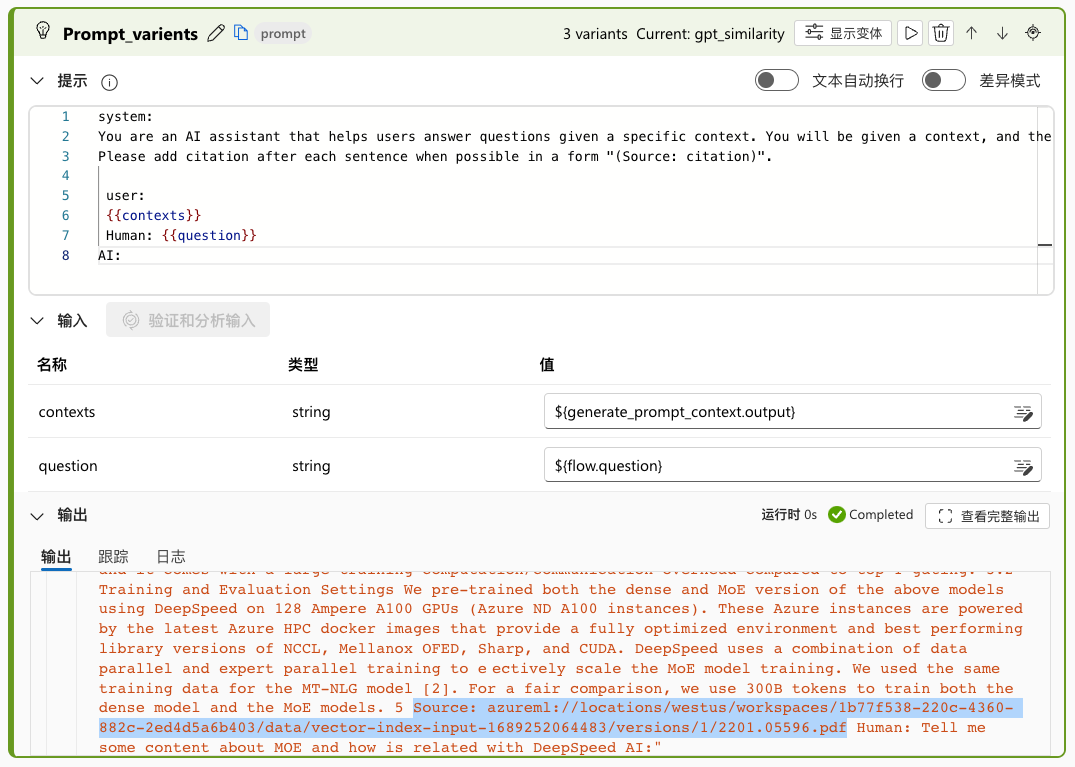
有了内容和来源,就可以构造提示了。默认的“Prompt_varients”提示变体有三个。以运行的示例来看,相同的矢量搜索结果发给了三个不同的提示变体:“gpt_similarity”、“gpt_relevance”、“bert_f1”。我暂时没有找到这三个不同的变体是否有不同的配置,只看到提示模板有些细微的差别。为了简化生成,可以让三个都使用相同的默认变体:“gpt_similarity”。
最后的组件模块“anwser_the_sample_flow”就很简单了,直接使用生成的 {prompt_text} 来和 ChatGPT 模型聊天,然后生成类似如下的输出:
{"system_metrics": {"completion_tokens": 197,"duration": 6.635436,"prompt_tokens": 1754,"total_tokens": 1951},"output": "Mixture-of-Experts (MoE) models are a promisingarchitecture for reducing the training cost ofgiant dense models. DeepSpeed-MoE is an end-to-endMoE training and inference solution as part of theDeepSpeed library, including novel MoE architecturedesigns and model compression techniques that reduceMoE model size by up to 3.7x, and a highly optimizedinference system that provides 7.3x better latencyand cost compared to existing MoE inference solutions.DeepSpeed-MoE offers an unprecedented scale andefficiency to serve massive MoE models with up to 4.5xfaster and 9x cheaper inference compared to quality-equivalent dense models. (Source: azureml://locations/westus/workspaces/1b77f538-220c-4360-882c-2ed4d5a6b403/data/vector-index-input-1689252064483/versions/1/2201.05596.pdf)"}
如果我们前面选的是三个不一样的变体,这里就会按照三个不同的提示模板给出三个不同的输出。
至此,就实现了利用矢量索引实现 RAG 的提示流管道线。
03
Azure ML Studio 的提示流使用图形化的管道线,降低了使用提示流的门槛,大量的处理和代码运行躲在了图形界面之后。我对管道线运行时后面发生的事情很有兴趣,因此也尝试通过查看作业的信息来了解 ML Studio 到底在做什么。
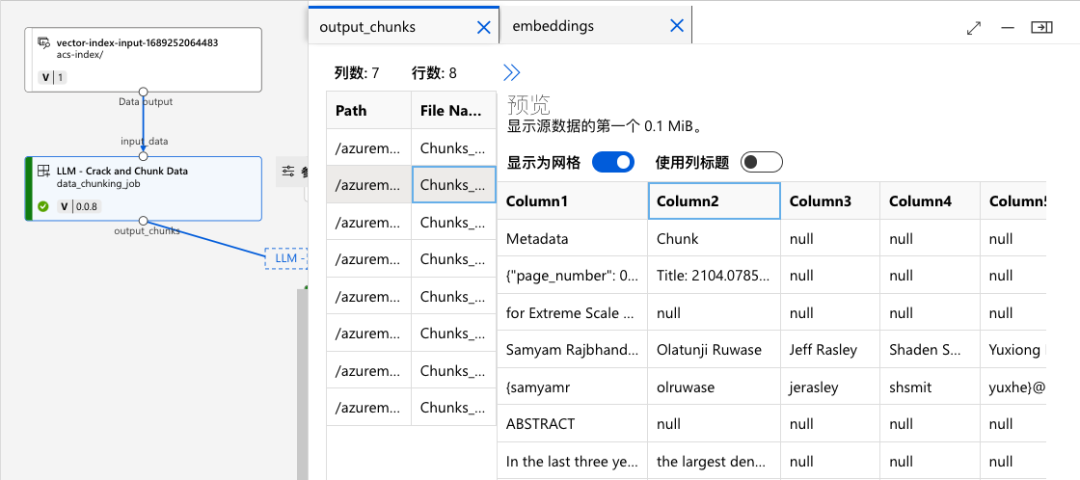
首先看看文本分块。尽管没找到代码,但是从 log 能看到是使用了 azureml.rag.crack_and_chunk 的方法对文件进行了拆解和分块。在机器学习工作室使用的工作空间的 Blob 存储中可以看到这些分块的 CSV 文件。
这里管道线用到的 azureml-rag 库已经发布在 PyPI 上(https://pypi.org/project/azureml-rag ),主要的作用是通过嵌入实现对 ACS 和 FAISS 的矢量索引。
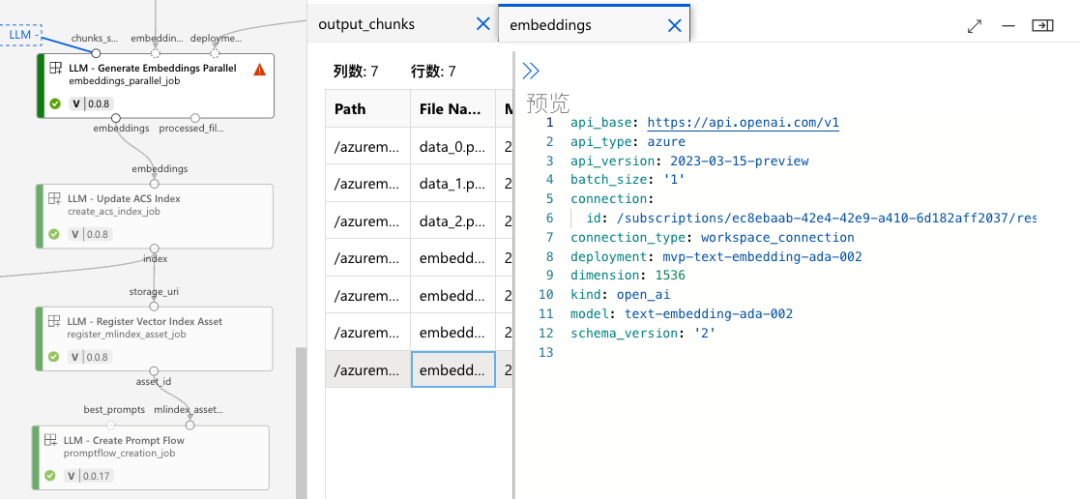
获得分块文件之后,对作业管道线的输出进行查看,可以发现生成的嵌入数据(基本不可读)以及记录。通过记录我们可以看到,调用 text- embedding-ada-002 类型的模型进行了嵌入处理,生成了一个 1536 维的矢量。
是不是对作业管道线中组件感到很有趣?其实这些组件都是基于 azureml-assets 中的组件描述来定义和绘制的。比如我们刚看到的拆解和分块,就能在 large_language_models 大语言模型分支下面的 rag 组件找到 crack_and_chunk 组件,然后可以查看其定义的 YAML 文件。
04
认知搜索 Key
使用查询而不是管理的 Key,会导致创建索引失败。
计算资源
在创建向量搜索的 Job 的时候,默认会使用无服务器。但当作业管道线运行到“embeddings_parallel_job”时,会提示 AzureML Compute 作业失败。这可能是由于使用的无服务器计算资源不能满足要求。

在作业运行的界面点击“重新提交”,可以修改运行参数重新运行管道线。在这个向导里的“运行时设置”页,可以更换默认计算的资源。比如先更换到了计算实例,结果由于 SKU 太低(我选的最便宜的 VM 定价层),磁盘空间不足再次失败了。我又懒得重新创建一个新的计算实例,就用之前创建的带有 GPU 的计算群集又跑了一遍。
ACS 索引大小写
开始创建矢量索引的时候,按照命名习惯给了一个大写缩写组成的名称,发现一到调用认知搜索 API 的时候就出错了。提示认知搜索服务的索引只能使用小写。换成小写重新创建,就没问题了。


[1] 检索增强生成(Retrieval Augmented Generation,RAG)
https://learn.microsoft.com/azure/machine-learning/concept-retrieval-augmented-generation?view=azureml-api-2&WT.mc_id=AI-MVP-33253
[2] 作业管道线组件模块 YAML 文件
https://github.com/Azure/azureml-assets/blob/main/assets/large_language_models/rag/components/crack_and_chunk/spec.yaml

胡浩
Microsoft MVP MCT

19 届多方向微软 MVP,目前奖励领域是 Azure 和 AI。多年从事基础架构相关工作,熟悉全栈虚拟化、终端用户和边缘计算等,对多个技术方向有所涉猎。乐于学习并分享 Azure 和 AI,曾在很多大型研讨会演讲,如微软 TechEd、MEDC、Tech Summit、Ignite,威睿 VMworld、vForum、ENPOWER、Explore 等技术会议。同时也是很多社区大会如 Global AI Bootcamp、Global Azure Bootcamp、Global M365 Bootcamp 等活动的组织者和演讲者。

微软最有价值专家(MVP)是微软公司授予第三方技术专业人士的一个全球奖项。30年来,世界各地的技术社区领导者,因其在线上和线下的技术社区中分享专业知识和经验而获得此奖项。MVP 是经过严格挑选的专家团队,他们代表着技术最精湛且最具智慧的人,是对社区投入极大的热情并乐于助人的专家。MVP 致力于通过演讲、论坛问答、创建网站、撰写博客、分享视频、开源项目、组织会议等方式来帮助他人,并最大程度地帮助微软技术社区用户使用 Microsoft 技术。
更多详情请点击阅读原文登录官方网站:
https://mvp.microsoft.com/zh-cn
