




背景
Curve 块存储支持基于 NVME+HDD 的混闪场景是 Curve 2023年的重要任务之一,具体的信息可以参考 Curve Roadmap 2023。混闪存储的主要优势是能以较低的成本获取较高的性能收益,所以性能是 Curve 块存储支持混闪场景的主要需求之一,这里分享几个 Curve 块存储支持混闪场景过程中遇到的性能问题和优化方案。
Curve Roadmap 2023:https://github.com/opencurve/curve/issues/2207
bcache gc 性能优化
bcache_gc内核线程
内核 ftrace 里的 bcache_gc 事件
bcache sysfs 里 gc 相关的统计
通过 sysfs 观察比较容易,这里会给出 gc 的平均持续时间,最大持续时间,平均触发频率,上次 gc 触发的时间点等统计数据。例如:
grep . sys/block/bcache0/bcache/cache/internal/btree_gc_*/sys/block/bcache0/bcache/cache/internal/btree_gc_average_duration_ms:2696/sys/block/bcache0/bcache/cache/internal/btree_gc_average_frequency_sec:7/sys/block/bcache0/bcache/cache/internal/btree_gc_last_sec:3/sys/block/bcache0/bcache/cache/internal/btree_gc_max_duration_ms:2783
在 Curve 块存储里,io 写请求会先经过 raft 协议,等多数节点写完 raft 日志后,io 请求即可返回,实际数据写到盘上是异步的。开始时 raft 的 wal 日志和数据 chunk 都是放在 bcache 缓存里的,这样对于缓存而言是相当于产生2倍的脏数据,很容易达到 bcache gc的触发阈值。
bcache writeback 异常问题
cat sys/block/bcache0/bcache/writeback_rate_debugrate: 0.5k/secdirty: 39.5Gtarget: 79.9Gproportional: -1.0Gintegral: 0.0kchange: 0.0k/secnext io: 1495mscat sys/block/bcache0/bcache/cache/cache_available_percent25
static inline bool should_writeback(struct cached_dev *dc, struct bio *bio,unsigned int cache_mode, bool would_skip){unsigned int in_use = dc->disk.c->gc_stats.in_use;if (cache_mode != CACHE_MODE_WRITEBACK ||test_bit(BCACHE_DEV_DETACHING, &dc->disk.flags) ||in_use > bch_cutoff_writeback_sync)return false;...}
nvme 盘性能下降
问题分析
在curce混闪测试过程中,我们还遇到了一个“硬件”相关的问题。
起因是在测试过程中发现,大 IO 顺序写压测一段时间后,Curve 混闪集群的性能就会变得很差(降低一半以上),但是过一段时间后性能会恢复正常,起初以为是缓存空间被写满导致的,但查看监控发现并不是的。
之后花了较多时间排查都没有明确的结论,最终只能靠排除法缩小问题范围可能是在 nvme 盘上,跟 Curve 块存储和 bcache 软件是无关的,出现问题的时候 nvme 盘本身的性能就是比较差的;
通过 blktrace 分析正常和异常场景下的 io 耗时,发现2者的 Q2C 和 D2C 差别都不大,说明 block 层调度没有问题,而异常时 D2C 的耗时明显增加一倍以上,说明确实是硬件处理慢了。
==================== All Devices ====================ALL MIN AVG MAX N//正常,D2C平均47usD2C 0.000007957 0.000046761 0.010916137 153422Q2C 0.000009531 0.000049924 0.010919176 153422//异常,D2C平均126usD2C 0.000009035 0.000125747 0.000618107 72384Q2C 0.000010458 0.000128898 0.001085908 72384
然后我们就从 nvme 驱动、固件方面入手,分析了几天还是没有进展,经过多次内部讨论,意外发现磁盘性能下降跟 nvme OP(Over-Provisioning) 空间大小有关。
所谓 OP 空间是 SSD 的预留空间,只有 SSD 主控才能访问到,主机 host 是访问不到的,主要是为内部 GC、读写平衡及坏块屏蔽等存储器内部功能服务的。不同厂商的不同型号 SSD,默认的 OP 空间大小也是不一样的,总的来说 OP 空间越大,SSD 磁盘性能越高,使用寿命越高,但用户可用的空间越小。
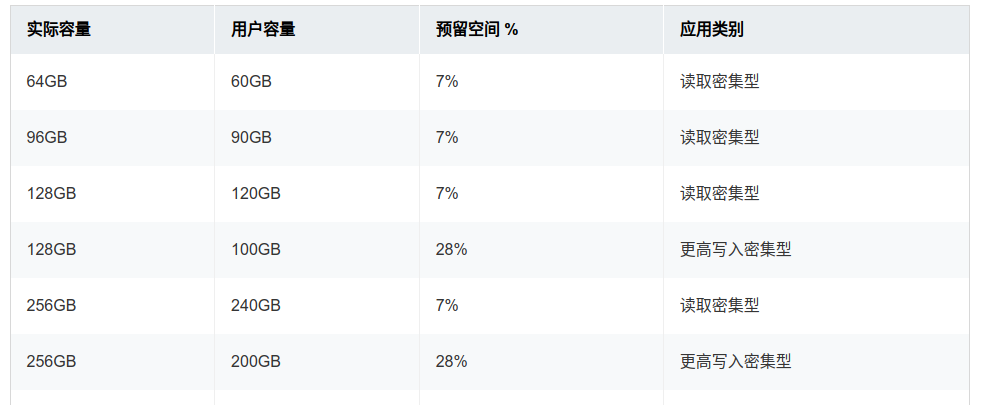
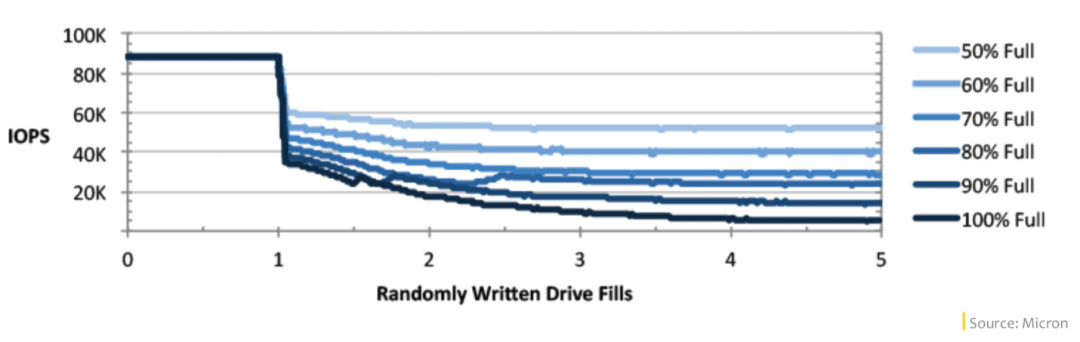
优化方案
暂时先用 Intel 的 nvme 盘来做缓存盘,后续再请厂商一起协助分析三星盘 OP 的问题。
总结
赢大奖有实习 Summer Code Camp | Curve &openEuler 联合举办
Curve 混闪之 bcache 与 open-cas 对比
Curve 社区上半年 Roadmap 进展及下半年规划
Curve 易用性升级之可视化运维——web 控制台介绍
使用 Curve 云上部署 Hadoop,轻松节约 50% 存储成本


关于 Curve
Curve 亦可作为云存储中间件使用 S3 兼容的对象存储作为数据存储引擎,为公有云用户提供高性价比的共享文件存储。
GitHub:https://github.com/opencurve/curve 官网:https://opencurve.io/ 用户论坛:https://ask.opencurve.io/ 微信群:搜索群助手微信号 OpenCurve_bot
