




背景
Curve 是云原生计算基金会 (CNCF) Sandbox 项目,是网易主导自研和开源的高性能、易运维、云原生的分布式存储系统。
典型场景一:
共享文件系统用于存储训练中间数据
场景描述
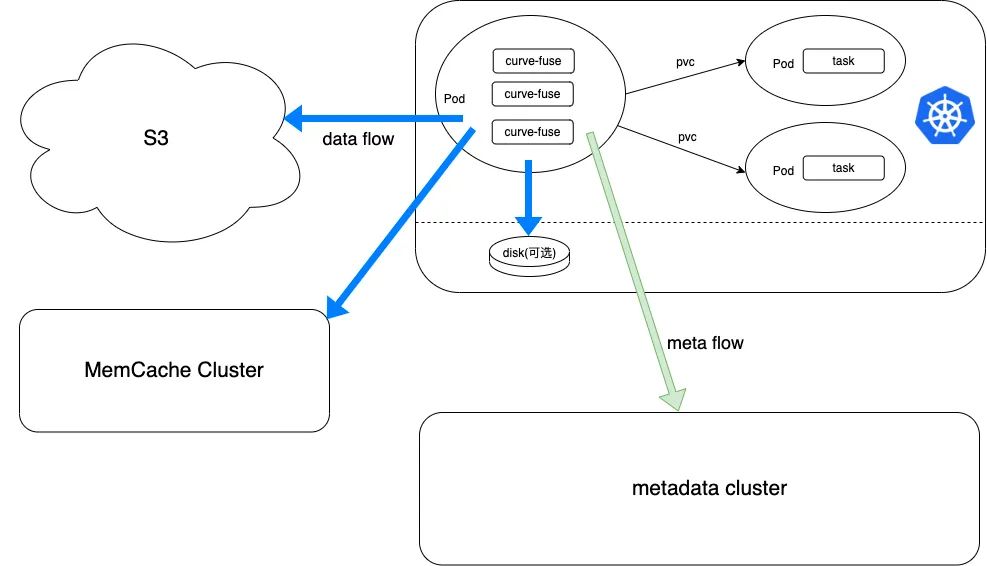
在部署中,除了本地缓存之外,还支持了共享缓存集群用于共享数据的加速。
IO特点及Curve的支持
1、AI 使用的分布式训练框架,分布式框架各节点之间有数据共享的需求,即节点 A 写入的数据,节点 B 要能即时访问到。
Curve 文件系统支持多节点间 close-to-open 一致性(文件关闭后下一次打开可以读到最新数据,多节点间表现为 A 节点文件 close 后,B 节点文件 open,读到的是最新数据),是可以满足场景中的一致性需求。 Curve 文件系统对该一致性的支持,是通过 close 将文件数据上传到 S3 实现的。所以 共享数据的性能依赖于数据上传 S3 的速度 。一般来说 S3 都是 HDD+EC 的配置,性能有限。 为了提升共享数据性能, Curve 文件系统在 v2.5 版本支持了Memcache集群缓存 ,数据上传到该缓存集群后就能实现共享,相比较于直接上传到 S3, 性能有5倍以上的提升。
2、AI 任务跑在 k8s 中,训练任务的 Pod 除了执行训练任务以外,还需要执行一些 k8s 的命令例如用 kubctl 于集群的管理与查看。会频繁访问很多系统文件的信息。
Curve 文件系统在 close-to-open 模式下,元数据的内核缓存和内存缓存都是失效的,这会导致常用命令使用性能体验很差。Curve 文件系统的元数据优化当前正在进 行,之前面向社区发起过讨论,更多的信息可以参考:CurveFS Feature - Performance[1]
典型场景二:
共享文件系统用于AI训练平台
IO特点及Curve的支持
1、AI 使用分布式训练框架,对于数据集的读取,每个节点所需要读取的数据是不一样的。这要求共享文件系统为大量数据读取提供高性能
在 v2.4 版本,Curve 文件系统为了加速数据读取,支持了 Warmup[2] 功能,可以把数据快速加载到本地缓存。但是在当前场景中,每个节点所需要读取的数据不同,并且不能预知任务会被分发到哪些节点,需要读取哪些数据。如果每个节点都做预热,会极大浪费缓存以及网络带宽。
为了解决上述问题, Curve 文件在后续的版本会支持数据预热到共享缓存集群 ,具体可以参考:支持数据 warmup 到 memcache 集群[3]。
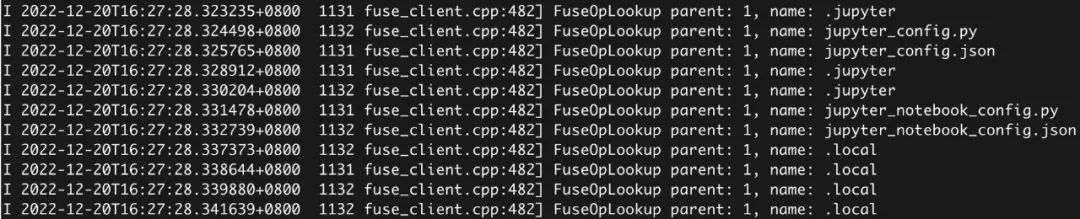
在代码执行过程中可以看到如下文件被频繁访问。这些被频繁访问的文件有两个来源:动态依赖库和环境变量。

由于代码的每次系统调用执行都涉及到所有环境变量和动态依赖库的查找,这部分产生的元数据的访问次数远大于读取数据集产生的元数据开销。
Curve 文件系统在共享状态下元数据的内核缓存和内存缓存都是失效, 导致所有这些文件的查找全部都要回源到元数据集群,严重影响了数据训练的速度。这个解决方法在典型场景1已经阐述过。
总结

这里主要面向存储方向开发者的交流和培养
参考[1]:
https://github.com/opencurve/curve/issues/2207
参考[2]:
https://github.com/opencurve/curve-meetup-slides/blob/main/PrePaper/2023/02-20-Curve%E6%96%87%E4%BB%B6%E5%AD%98%E5%82%A8client%20warmupManager.md
参考[3]:
https://github.com/opencurve/curve-meetup-slides/blob/main/PrePaper/2023/02-20-Curve%E6%96%87%E4%BB%B6%E5%AD%98%E5%82%A8client%20warmupManager.md


关于 Curve
Curve 亦可作为云存储中间件使用 S3 兼容的对象存储作为数据存储引擎,为公有云用户提供高性价比的共享文件存储。
GitHub:https://github.com/opencurve/curve 官网:https://opencurve.io/ 用户论坛:https://ask.opencurve.io/ 微信群:搜索群助手微信号 OpenCurve_bot
