




前言
Curve 是云原生计算基金会 (CNCF) Sandbox 项目,是网易主导自研和开源的高性能、易运维、云原生的分布式存储系统。
Curve块存储应用实践一部曲之iSCSI Curve块存储应用实践二部曲之nbd Curve块存储应用实践三部曲之云主机 Curve块存储应用实践四部曲之云原生数据库 Curve块存储应用实践五部曲之性能调优
参考性能
条带化卷参数:stripeUnit=16k stripeCount=64(大io建议创建条带化卷测试)
8k随机写测试数据
[global]bs=8Kiodepth=128rw=randwritedirect=1numjobs=1size=100Gioengine=cbdruntime=999999time_basedgroup_reportingramp_time=10s
| iops(k) | avg lat(us) | avg lat(us) |
| 27.9 | 4590 | 27919 |
| 27.7 | 4614 | 27919 |
| 28.1 | 4549 | 27657 |
512k顺序写测试数据
[global]bs=512kiodepth=128rw=writedirect=1numjobs=1size=100Gioengine=cbdgroup_reportingruntime=90ramp_time=10s
| bandwidth(MB/s) | avg lat(ms) | 99th lat(ms) |
| 338 | 189 | 372 |
| 338 | 189 | 485 |
| 343 | 186 | 397 |
影响性能的关键指标
直接通过服务的 ip:port 获取
通过监控查看(块存储监控部署[1])
环境配置
[global]rw=randwriteiodepth=1ioengine=psyncfdatasync=1bsrange=4k-4ksize=4Gnumjobs=32group_reportingtime_based=1thread=1runtime=10000[disk0]filename=/data/chunkserver0/data[disk1]filename=/data/chunkserver1/data
如果有多个SSD盘,在 fio 脚本的后面加上对应的盘。
fio 测试写入的文件,最好提前通过 dd 命令创建或覆盖写一遍,dd if=/dev/zero of=/data/chunkserver0/data bs=1M count=4096 oflag=direct
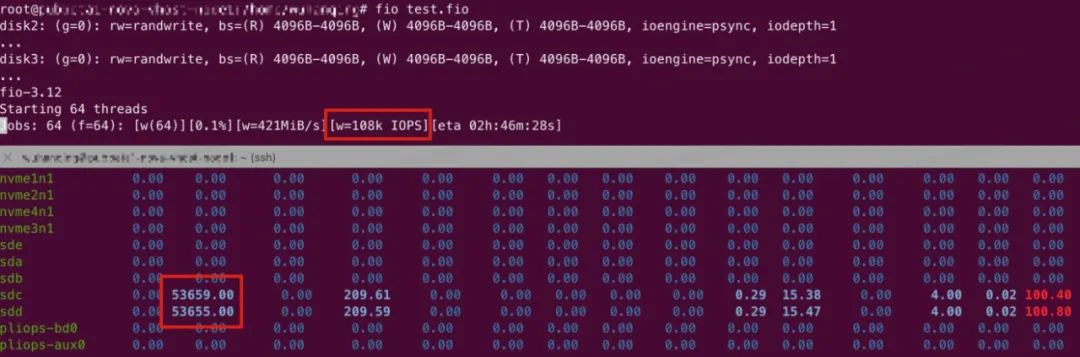
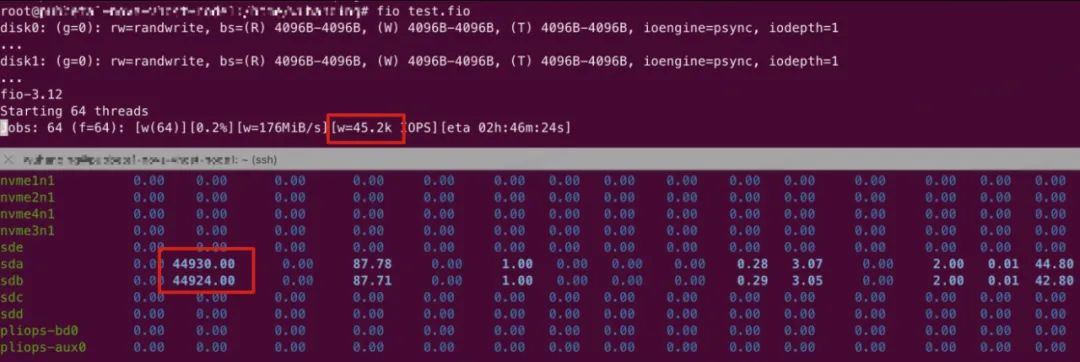
服务端
metric 指标查看:curl leadermdsip:leadermdsport/vars | grep leadernum_range 查看 chunkserver上leader 数量最大和最小的差值,一般这个值在5以内认为集群是均衡的
topology_metric_logical_pool_default_logical_pool_leadernum_range : 1.000
监控:MDS DashBord/chunkserver 状态 panel
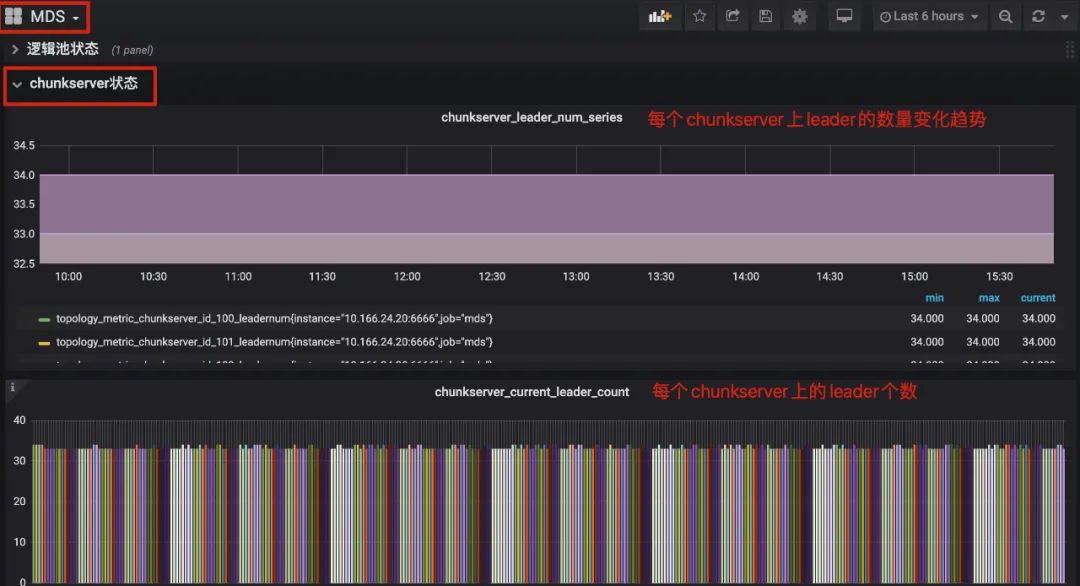
leader 不均衡时可以通过命令触发快速均衡:curve_ops_tool rapid-leader-schedule。这个命令创建的配置变更任务是随着心跳上报的,所以均衡效果在几个心跳周期之后可以看到(默认心跳周期是10s)。
从监控上可以看到每个 chunkserver 上的 leader 不均衡,并且单个 chunkserver 上的 leader 总是在变动(参考 1. 复制组的 leader 在 chunkserver 上的分布是否均衡)
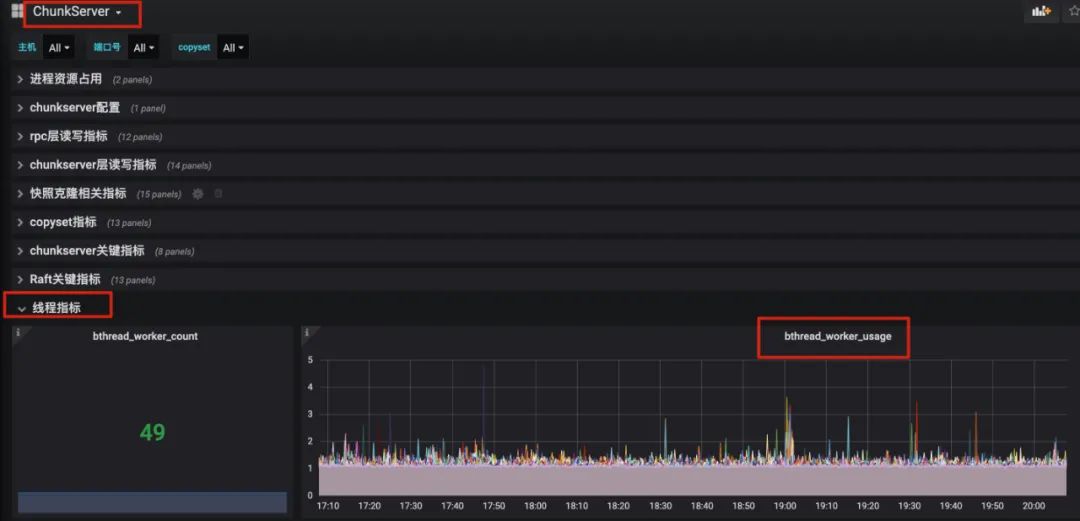
监控项 chunkserver Dashbord/线程指标 Panels 中 bthread 的使用率持续飙高。更多信息的获取可以参考 brpc 线程数量查看:
chunkserver 的日志中有大量 leader 选举日志:
LOG(INFO) << "node " << _group_id << ":" << _server_id<< " received PreVoteResponse from " << peer_id<< " term " << response.term() << " granted " << response.granted();
通过 linux 命令 iostat 查看磁盘压力情况,一般看观察 util 是否接近100%,cpu 的 idle 是否接近0;
通过查看监控项 chunkserver Dashbord/Raft 关键指标 Panels
storage_append_entries_latency : 写盘的延迟(一般ssd的延时在百us~几ms级别;hdd延迟在数十ms级别)
raft_send_entries_latency: 一次写盘延迟+一次rpc延迟(一般rpc的延迟在百us~几ms级别)
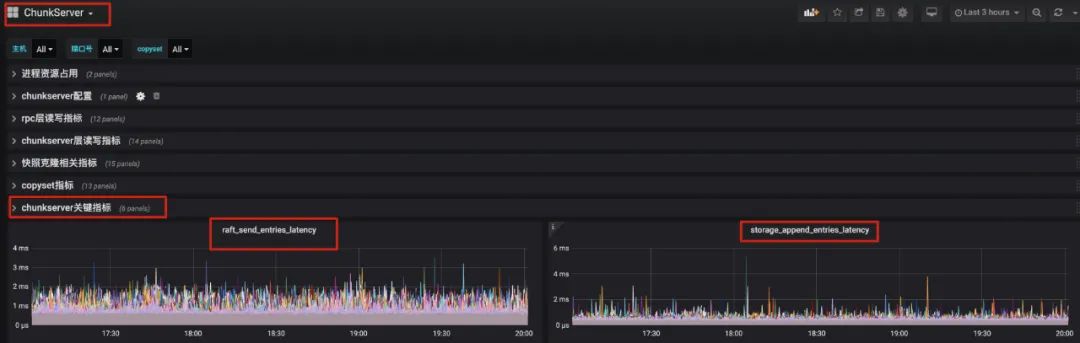
如果底层磁盘已经压满,理论上就已经达到了集群性能上限。
条带化卷的创建:
当前 Curve 块存储支持的几个协议 nbd、openstack、iscsi 都是要跟 Curve 热升级[4]模块对接的,在 IO 链路上会多一次 RPC。当前 Curve 块存储版本已经稳定,如果不考虑热升级,可以去掉热升级模块,提高性能。
Curve 块存储 fio 的使用方式可以参考:Fio for Curve README[5]
其他指标简析
详见 Curve 块存储监控项说明[6]
IO 过程中全链路关键阶段时延的 metric 查看(DashBord/Pannel,指标的具体含义请查看 Curve 块存储监控项说明[7]):
client端:用户接口层指标/client_write_latencyrpc层指标/write_rpc_latencychunkserver端:rpc层读写指标/avg_write_latchunkserver层读写指标/avg_write_latRaft关键指标/raft_send_entries_latencyRaft关键指标/raft_service_append_entries_latencyRaft关键指标/storage_append_entries_latency
<原创作者:李小翠,Curve Maintainer>
参考[1]:
https://github.com/opencurve/curveadm/wiki/curvebs-monitor-deployment
参考[2]:
https://github.com/opencurve/curve/blob/master/docs/cn/%E6%B5%8B%E8%AF%95%E7%8E%AF%E5%A2%83%E9%85%8D%E7%BD%AE%E4%BF%A1%E6%81%AF.md
参考[3]:
https://github.com/opencurve/curve/blob/master/docs/cn/curve-stripe.pdf
参考[4]:
https://github.com/opencurve/curve/blob/master/docs/cn/nebd.md
参考[5]:
https://github.com/opencurve/fio#readme
参考[6]:
https://github.com/opencurve/curve/blob/master/docs/cn/Curve%E7%9B%91%E6%8E%A7%E6%8C%87%E6%A0%87%E8%A7%A3%E6%9E%90.md


关于 Curve
Curve 亦可作为云存储中间件使用 S3 兼容的对象存储作为数据存储引擎,为公有云用户提供高性价比的共享文件存储。
GitHub:https://github.com/opencurve/curve 官网:https://opencurve.io/ 用户论坛:https://ask.opencurve.io/ 微信群:搜索群助手微信号 OpenCurve_bot
