




Selective Context介绍
Unlocking Context Constraints of LLMs: Enhancing Context Efficiency of LLMs with Self-Information-Based Content Filtering
https://github.com/liyucheng09/Selective_Context
论文的主题是利用自信息对上下文进行筛选,从而提高大型语言模型(LLM)在处理长文档或保持长对话时的效率。

论文提出了一种名为“Selective Context”的方法,通过评估内容的信息量,有选择地保留更具信息量的内容,从而减少给定上下文的成本,并在不降低性能的情况下更好地利用LLM的固定上下文长度。
Self-Information
自信息(Self-Information),也称为“惊讶度”(surprisal)或“信息内容”(information content),是信息论中的一个基本概念,用于量化一个事件所传达的信息量。
在语言建模的上下文中,该事件可以指代生成的一步(即一个标记)。自信息定义为该标记的负对数似然:
其中,表示标记的自信息,表示其输出概率。
在信息论中,自信息用于衡量事件的惊奇程度或不确定性;罕见的事件传递更多信息,因此具有较高的自信息,而常见的事件传递较少信息,其自信息较低。
在语言建模的上下文中,自信息可以用于评估词汇单位(例如单词、短语或句子)的信息性,以确定哪些信息更可能是新颖或对理解上下文更重要的信息。
Selective Context原理
计算自信息
给定上下文,其中表示一个标记(token),我们使用基础语言模型来计算每个标记的自信息,计算公式如下:
这里的基础语言模型应该是因果语言模型,例如GPT-2、OPT和LLaMA。
合并为词汇单元
为了使选择性上下文能够适用于短语和句子级别,需要将标记及其自信息合并为词汇单元。对于每个词汇单元,可以通过将其各个标记的自信息相加来计算其自信息,这是由自信息的可加性特性决定的:
我们使用句子分词器将其合并为句子级别的词汇单元。对于名词短语,我们使用Spacy将标记合并为名词短语。我们不合并动词短语,因为这可能会产生过长的短语。
选择性保留信息丰富的上下文
有了每个词汇单元的自信息计算结果,现在可以评估它们的信息性。我们建议使用基于百分位数的过滤方法,而不是使用固定阈值或保留固定数量的前个词汇单元,以自适应地选择最具信息量的内容。

首先,我们根据自信息值降序对词汇单元进行排名。然后,计算所有词汇单元中自信息值的第个百分位数:
接下来,我们选择性地保留自信息值大于等于第个百分位数的词汇单元,构建过滤后的上下文:
基于百分位数的过滤方法更加灵活,可以根据给定上下文中自信息值的分布来保留最具信息量的内容。
实验设置
实验数据集
BBC新闻:包含从英国广播公司(BBC)于2023年3月发布的新闻文章。该数据集涵盖了政治、商业、体育和技术等各种主题。在我们的实验中,我们使用每篇新闻文章的全部内容。 Arxiv论文:由来自arXiv预印本存储库的最新学术论文组成,创建于2023年3月。这些论文涵盖了计算机科学、物理学、数学等各种科学领域。由于Arxiv论文可能非常长,我们在实验中仅处理每篇Arxiv论文的前两个部分。 ShareGPT.com:ShareGPT.com是一个平台,ChatGPT的用户在该平台上分享他们与ChatGPT进行的令人惊讶和有趣的对话。该数据集包含了不同语言和各种场景(如编码、闲聊、写作助手等)的对话。我们在实验中使用ShareGPT数据集进行对话任务的评估。
评价指标
原始上下文重建:给定选择性上下文生成的压缩上下文,该任务旨在评估模型是否能够重建原始上下文。该任务评估了过滤上下文后保留原始上下文中的基本信息的能力。在我们的实验中,压缩上下文作为输入,原始上下文作为参考答案。 摘要生成:给定一个上下文,任务是生成一个简洁且信息丰富的摘要,概括文档的主要内容。该任务旨在评估内容过滤对模型对压缩上下文的整体理解能力的影响。
实验结果
Selective Context在不同的上下文缩减比例下与原始上下文相比,在摘要和问答任务中仅引起轻微的性能下降。当缩减比例为0.2时,BLEU分数仅下降0.05,而ROUGE-1分数的下降仅为0.03。当缩减比例为0.35时,结果仍然令人满意,BERT分数约为0.9,ROUGE-1分数超过0.5。
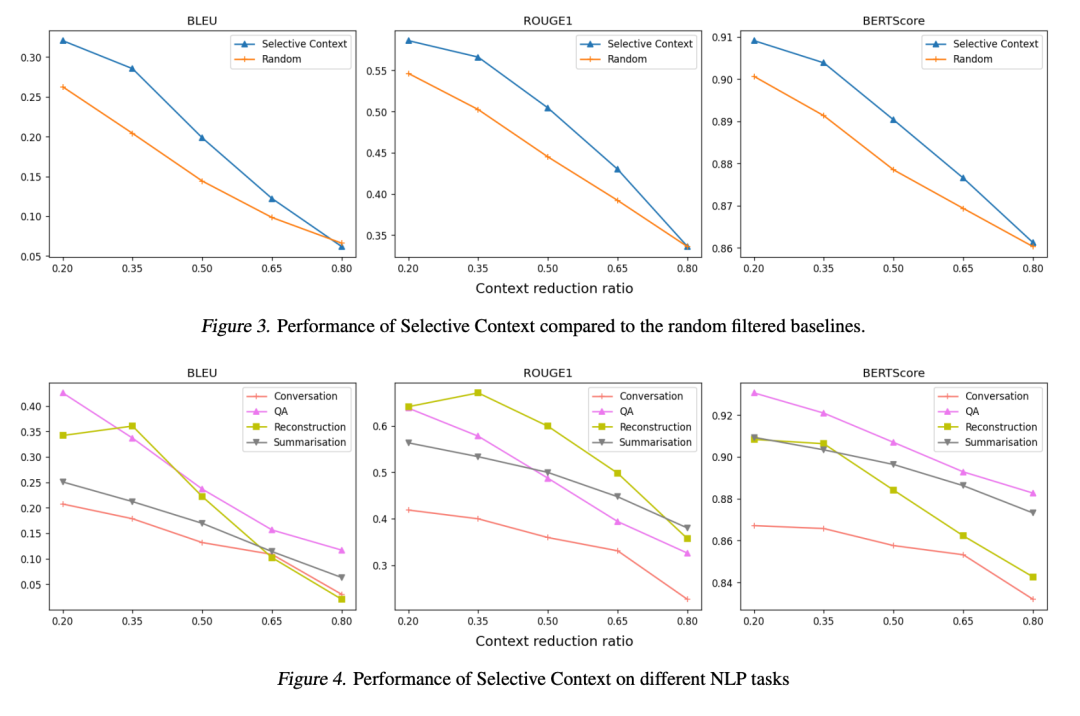
对比随机筛选基线,选择性上下文方法表现更好。随机筛选方法在随机缩减20%的内容时,BLEU分数可以达到0.25以上,当随机缩减35%的内容时,ROUGE-1分数可以达到0.5以上。而选择性上下文方法在缩减比例为0.35时,达到了约0.3的BLEU分数和超过0.55的ROUGE-1分数。
当缩减比例为0.8时,两种方法显示出类似的结果,表明LLMs难以处理信息丧失达80%的上下文。总体而言,实验结果表明,选择性上下文能够有效地最大化LLMs中固定上下文长度的效用,在各种任务上保持强大的性能。
方法总结
Selective Context通过过滤掉不太信息丰富的内容,提供了一种更紧凑、更高效的上下文表示方式,同时不降低在各种任务上的性能表现。
总的来说选择性上下文是一种有效的方法,能够最大限度地利用LLM中固定上下文长度的优势。它可以压缩输入提示的长度,同时保持各种任务的性能。
但本文并未讨论压缩提示是否会导致输出多样性的差异。该方法尚未验证适用于涉及多语言、混合文本和代码输入的场景。
# 竞赛交流群 邀请函 #

添加Coggle小助手微信(ID : coggle666)
每天算法竞赛、干货资讯和大模型知识汇总
与 35000+来自AI爱好者一起交流~

