




TabLLM介绍
TabLLM: Few-shot Classification of Tabular Data with Large Language Models
https://github.com/clinicalml/TabLLM
传统的深度学习方法在表格数据领域的分类任务上表现不如强大的传统基线方法(如梯度提升树),而LLMs在文本领域取得了巨大的成功。
LLMs的参数中编码了大量的知识,它们几乎不需要标记训练数据即可获得良好的性能。论文作者认为利用LLMs来处理表格数据分类问题具有巨大的潜力。
论文的出发点是利用LLMs的先前知识编码能力和少样本学习能力,提出一种新的TabLLM框架
,以实现对表格数据进行高效的零样本和少样本分类。
历史方法
自监督学习方法:通过自监督任务来预训练模型,在表格数据中包括预测被掩盖的单元格、识别或纠正损坏的单元格以及对数据进行对比增强等任务。
可微分树方法:这些方法结合了树集成的优势和基于梯度的神经网络优化,通过训练可微分的树模型来学习表格数据的特征表示和分类模型。
梯度提升树方法:梯度提升树是一种强大的基准方法,通过迭代地训练决策树并将它们组合成一个强大的模型来实现表格数据的分类。
迁移学习方法:一些方法通过在同一表格上进行附加的监督任务来实现迁移学习,利用半监督学习的方式来提高分类性能。
实现步骤
问题形式化:给定一个包含 n 行和 d 列(特征)的表格数据集,表示为 D = {(x, y)}_n,其中每个 x 是一个 d 维特征向量,y 属于类别集合 C。列名或特征名表示为 F = {f1, ..., fd}。
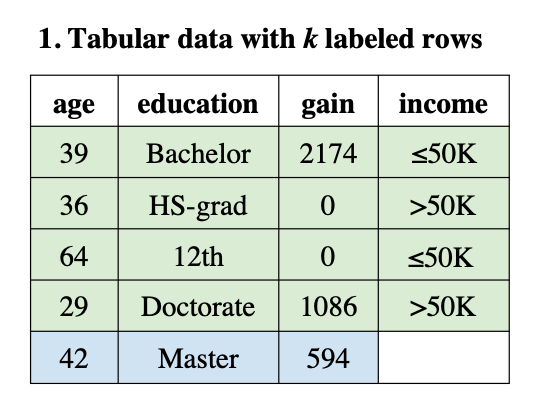
表格数据的序列化:为了使用LLM处理表格数据,需要将表格转换为自然语言文本表示。序列化过程使用 serialize(F, x) 函数,该函数接受列名 F 和特征值 x 作为输入,创建输入的文本表示。序列化可以是任意复杂的过程,可以包括使用其他LLM或特征选择等技术。

用于分类的大型语言模型:TabLLM可以与不同的LLM配合使用,这些LLM基于自然语言输入生成文本。设 LLM 为具有词汇表 V 的LLM。LLM接受输入 (serialize(F, x), p),其中 p 是任务特定的提示,生成词汇空间 V 中的文本。这个输出需要通过使用诸如 verbalizer 的方法将其映射到类别集合 C 中的有效类别上,verbalizer 定义了LLM输出标记和离散标签空间之间的映射关系。
TabLLM的序列化方法:LLM的性能对自然语言输入的具体细节非常敏感。TabLLM研究了不同的序列化格式以改善性能。其中一些序列化方法包括:
- 列表模板(List Template):将列名和特征值简单地拼接成一个列表形式。
- 文本模板(Text Template):将所有特征按照“列名是值”的文本形式进行枚举。
- 表格转文本(Table-To-Text):使用在表格转文本生成任务上进行微调的LLM来生成序列化表示,将每个列-值对单独提供给模型,并将输出进行拼接。
- 文本 T0:使用具有 110 亿参数的 T0 LLM(bigscience/T0pp),将一行拆分为列-值对的两个元组,分别向LLM发送,并结合提示进行输出的组合。
- 文本 GPT-3:通过 API 使用 GPT-3(engine text-davinci-002),一次性处理所有特征,使用提示“将输入中的所有列表项重写为自然文本”作为输入,并用“{人物,汽车,患者} 是”的文本引导输出。
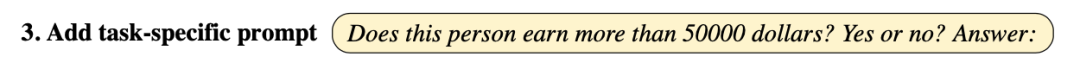
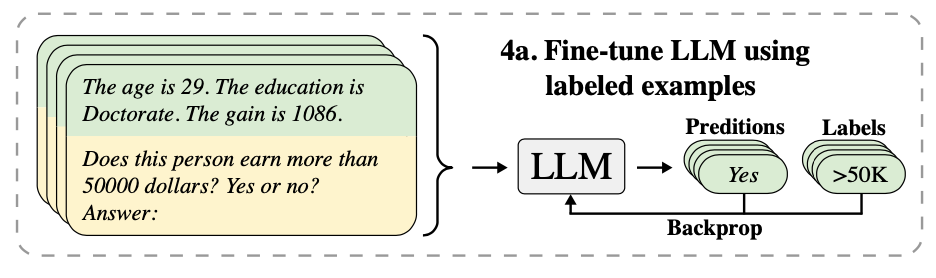
TabLLM采用了具有110亿参数的T0编码-解码模型作为LLM,模型是通过对大量任务特定提示进行训练而得到的,模型的令牌限制为1024个,大致相当于400个单词的长度。
TabLLM效果
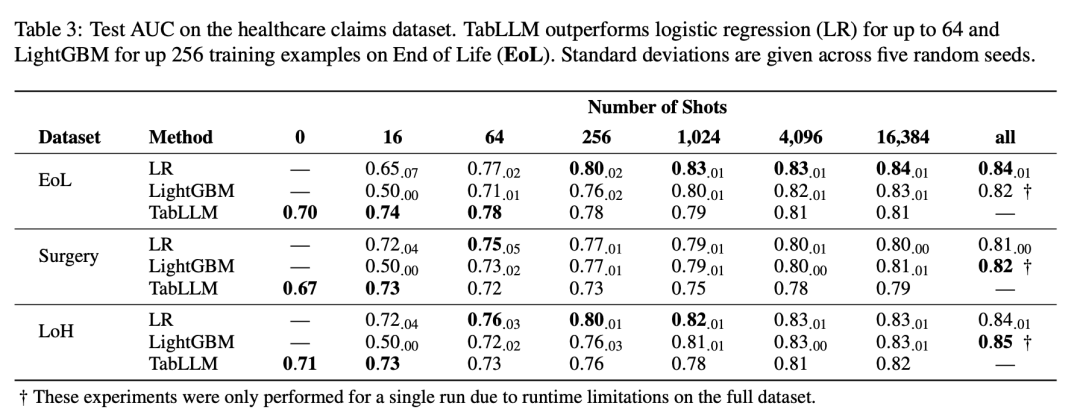
当移除或排列列名时,观察到性能下降的情况。这表明LLM实际上利用了特征名称及其与正确值的关系。 TabLLM的样本效率在很大程度上取决于任务。在Blood、Credit-g、Diabetes和Heart数据集上的性能较低,而在Income和Car数据集上的性能较好。后者数据集的大多数特征具有语义上有意义的文本值,可能提升了TabLLM的性能。 使用更多训练样本时,TabLLM的性能明显提高。在非常少样本情况下,它经常优于强基线模型。
方法总结
TabLLM通过将表格数据序列化为文本或模板形式,并将其输入LLM进行分类预测。该方法在少样本情况下表现出一定的性能改进。
但TabLLM并不能替代现有的机器学习模型,效果并不能比逻辑回归或树模型更好,且模型更难解释。
总之TabLLM方法为表格分类任务提供了一种新的思路,利用LLM来增强少样本情况下的分类性能。
# 竞赛交流群 邀请函 #

添加Coggle小助手微信(ID : coggle666)
每天Kaggle算法竞赛、干货资讯汇总
与 34000+来自竞赛爱好者一起交流~

