





导
读
云原生数据库PolarDB分布式版(PolarDB for Xscale,简称“PolarDB-X”)是阿里云自主设计研发的高性能云原生分布式数据库产品。作为PolarDB for Xscale分布式数据库产品存储引擎的核心技术模块, Lizard事务系统承担了重要角色。本篇文章将分为两部分对其进行深度解读,上篇介绍Lizard SCN单机事务系统,下篇介绍 Lizard GCN分布式事务系统。

分布式数据库架构
关系型数据库作为支撑企业级数据的在线存储方案,发挥了无可替代的作用。随着海量数据的增长,以及面对创新业务爆发性增长的场景,如何能够快速,业务无损的进行在线数据库扩容,对数据库的架构提出了巨大的挑战,除此以外,企业的精细化经营,也要求数据库能够一站式提供事务处理能力和数据分析能力,为了应对这些挑战,分布式数据库应运而生,相比着传统的事务型数据库,分布式数据库着力解决的几个核心技术问题:
1. 能否快速进行水平拆分,线性扩展事务处理能力;
2. 能否实现业务无损,像使用单机数据库一样,保证ACID特性;
3. 能否保证业务持续可用,实现企业级容灾能力;
1. 基于中间件的Sharding分案
2. 基于共享资源池的Scale Up方案
3. 基于Share Nothing/Everthing的水平扩展方案
PolarDB分布式版简介
● 云原生化,基于存储计算分离的 Share Nothing 架构,实现极致的弹性能力和水平扩展能力
● 透明分布式,以单机数据库的体验,操作分布式数据库;
● 自研的 Lizard 分布式事务系统,保证 ACID 特性和全局一致性;
● 自研的分布式复制协议 X-Paxos,保证业务持续可用;
● 高效的交互协议 X-Protocol,实现请求流水线处理;
● 行列混合存储,实现 HTAP 处理能力;
PolarDB分布式版架构
PolarDB分布式版采用了 Timestamp Oracle (TSO) 架构实现全局授时服务,由集群 GMS 提供,CN (Computing Node) 节点作为入口,除了提供基础的数据分片和路由功能,并实现了强大的执行引擎能力,DN (Data Node),提供了基础的数据存储服务,并提供分布式事务和高可用能力,CDC (Change Data Capture),作为数据流通道,提供了数据生态能力,PolarDB分布式版总体架构如图所示:
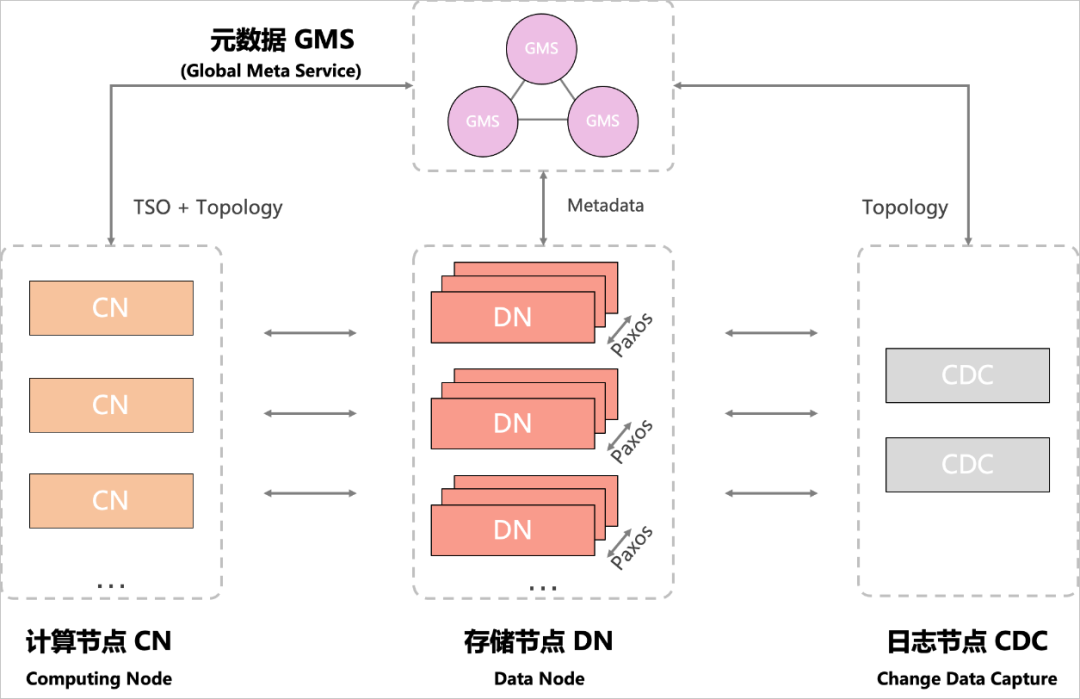
PolarDB for Xscale分布式存储引擎
作为 DN 和 GMS 节点的存储引擎,其在 MySQL 开源生态的基础上,扩展和自研了大量的核心能力,有效的支撑PolarDB分布式版产品, 其中包括:
● 连续递增的全局自增列
● 全局有序的TSO发号器
● 高效稳定的分布式事务
● 安全严格的全局一致性
● 持续可用的分布式协议
业务背景
使用语法
1. 创建 SEQUENCE
CREATE SEQUENCE [IF NOT EXISTS] <数据库名>.<Sequence名称>[START WITH <constant>][MINVALUE <constant>][MAXVALUE <constant>][INCREMENT BY <constant>][CACHE <constant> | NOCACHE][CYCLE | NOCYCLE];
SELECT Nextval(seq);SELECT Currval(seq);
实现原理
Sequence 底层使用 InnoDB 存储引擎来保存这些属性,所以,Sequence Engine 被定义成一个逻辑引擎,负责sequence的缓存策略和访问入口,真实的数据保存在 InnoDB 表中。
为了保证 Sequence 的唯一特性,Sequence 窗口的滑动,涉及到对底层数据的修改,这一部分修改,使用的是自治事务,也就是脱离主事务上下文,自主提交,如果主事务回滚,获取的 sequence 号将会被丢弃,而不是回滚,以保证其唯一性。
Sequence 根据租约 (lease) 类型的不同,支持了两类 sequence,一类是数字型即 Number Sequence,数字窗口用来实现最大吞吐能力和最少可丢弃数字的最佳平衡。另外一类是时间型既 Time Sequence, 时间窗口用来实现最大吞吐能力和最少不可用时间的最佳平衡。
Sequence 的高可用依赖其所在的存储引擎的高可用方案,Sequence 的修改日志通过 BINLOG 日志和 X-Paxos 协议进行复制,如果发生切换,Sequence 丢弃一个租约窗口的数据,来保证唯一性。在性能上能达到 3万 QPS/Core,并能轻松在上百核的 CPU 上运行并且没有性能热点。
全局自增列
分片 1:{ 0001 - 1000 }
分片 2:{ 1001 - 2000 }
分片 3:{ 2001 - 3000 }
SEQUENCE默认实现了数字型生成器,也就是其窗口租约类型是数字,比如窗口是 100,其Cache Size就等于 100,窗口内的数字从内存获取,cache使用完,就推进到下一个窗口。异常情况,最大可丢失一个窗口的数字,来保障其唯一性,所以,Cache Size的设置,需协调尽量提升性能和尽可能少丢失窗口数字的平衡。PolarDB分布式版中的Auto Increment可以对应一个Sequence,用nextval来为这个字段生成唯一连续的数字,保障分布在多节点的数据分片中,实现自增列按照插入的顺序生成。
TSO 发号器
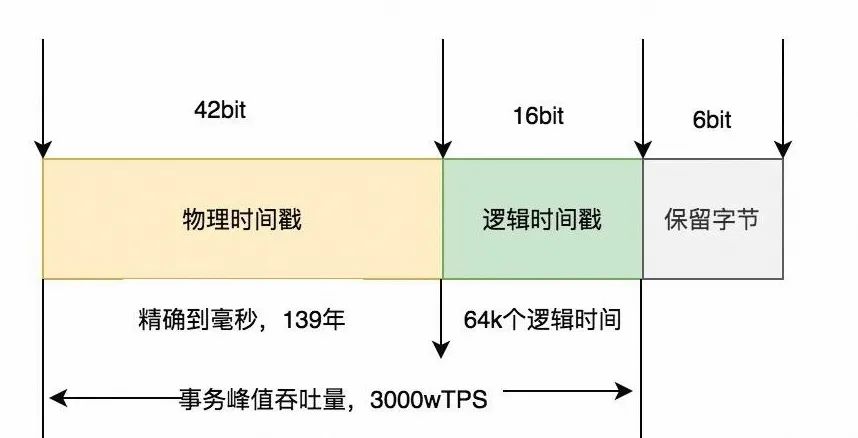
Sequence 实现的时间型生成器,也就是 lease type 等于 Time, 定制 TSO 的格式,使用 42 个 bit 表达毫秒级的物理时间,16 个 bit 表达一个递增的自然数,理论设计上秒级可以实现最大 3000w 的 TPS 吞吐能力,足够支撑一个超大规模的分布式数据库。
其中租约窗口用 Cache Size 来表达,比如:cache size = 2s,其代表租约窗口是 2 秒钟,2秒窗口内的数字从内存生成,并提前推高所有高可用节点到下一个未来2秒的开始,也就是这个窗口,代表异常切换后,TSO发号器可用的最大等待物理时间,以保证唯一性, 对于 Cache Size 的设置,需协调最大吞吐能力和最小不可用时间的最佳平衡。
InnoDB 单机事务系统
▶︎ 弊端1:Read/Write 冲突严重
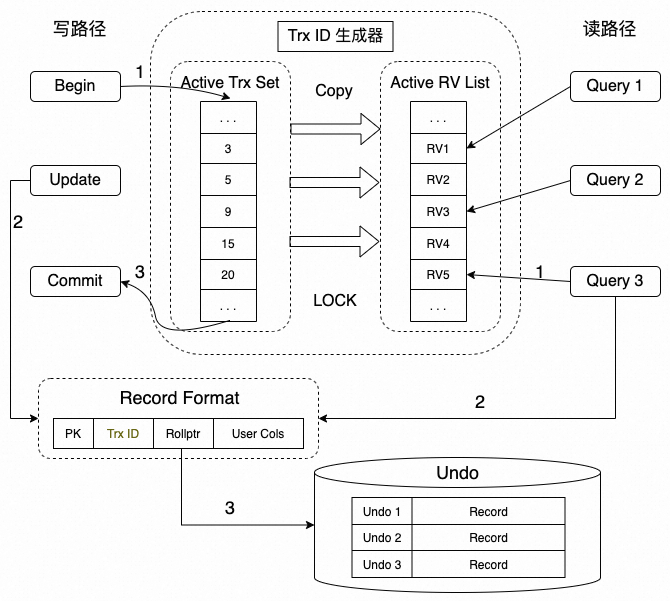
写路径上:
1. 事务启动时,分配事务ID,并插入到全局的活跃事务ID数组中;
2. 事务过程中,修改操作会将事务ID更新到行记录上来,表示该行记录的最新修改者;
1. 查询启动时,启动Read View,并将全局的活跃事务 ID 数组拷贝到Read View 上;
▶︎ 弊端2:Commit 无法外部定序
▶︎ 弊端3:MVCC 视图无法传播
1. 事务 ID 无法在分片之间同步和识别;
1. 在单机存储计算分离的模式下,无法高效使用 read view 进行存储计算下推;
2. 在分片集群模式下,无法得到全局一致性版本;
Lizard SCN 单机事务系统
▶︎ SCN 事务系统架构
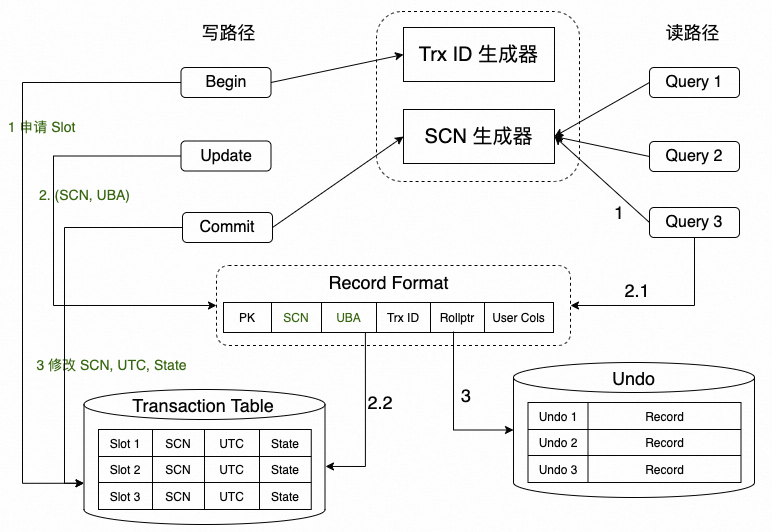
1. 事务启动时,申请事务槽 Transaction Slot,地址记为 UBA;
2. 事务过程中,对修改的记录填入 (SCN=NULL, UBA) 两个字段;
读事务:
1. 查询启动时,启动事务视图 Vision,即从 SCN 生成器上获取当前 SCN,作为查询的 Vision;
2. 查询进行时,根据行记录的 UBA 地址找到对应的事务槽,获知事务的状态以及提交号;
许多用户在线上运维数据库过程中,可能会出现一些误操作,常见的比如更新操作或删除语句没有带限定条件或指定了错误的限定条件,导致数据因为人工误操作而被破坏或丢弃。特别是如果操作的是重要的配置信息,则会严重影响业务运行。这个时候往往需要 DBA 快速对数据进行回滚操作以恢复业务。
FlashBack 语法
SELECT ... FROM tablenameAS OF [SCN | TIMESTAMP] expr;
CREATE TABLE `innodb_flashback_snapshot` (`scn` bigint unsigned NOT NULL,`utc` bigint unsigned NOT NULL,`memo` text COLLATE utf8mb3_bin,PRIMARY KEY (`scn`),KEY `utc` (`utc`)) /*!50100 TABLESPACE `mysql` */
UNDO 保留周期
Lizard SCN 事务系统,保留了两个维度的设置,来灵活制定 undo 的保留周期:
参数 innodb_undo_retention 可以制定 undo 保留多长时间,单位为秒
2. 空间维度:
参数 innodb_undo_space_reserved_size 可以制定 undo 保留多大的空间,单位为 MB
实现原理
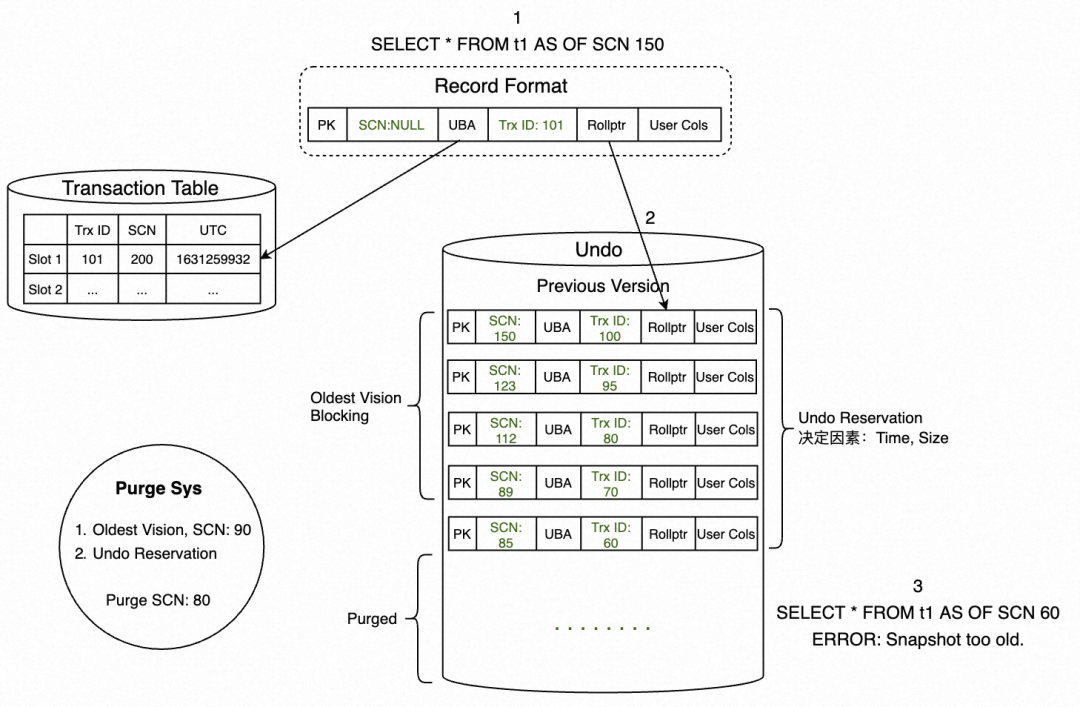
1. SELECT * FROM t1 AS OF SCN 150 发起闪回查询。
2. 扫描到一条行记录,发现SCN是无效值,则通过UBA回查Transaction Table,获取事务状态信息。可以看到,该记录的SCN=200,并非本次闪回查询所需要的版本。
▶︎ SCN 事务系统的代价
相比于 InnoDB 事务系统,Lizard SCN 事务系统带来了巨大的优势:
3. 支持自定义的 FlashBack 查询
但同时也引入了一些代价,因为事务提交只修改了事务槽,行记录上的 SCN 一直为 NULL 值,所以,每次的可见性比较,都需要根据 UBA 地址访问事务槽,来确定真实的提交版本号 SCN,为了减轻事务槽的多次重复访问,我们在Lizard SCN 事务系统上引入了 Cleanout,一共分为两类,Commit Cleanout 和 Delayed Cleanout。
事务在修改过程中,收集部分记录,在事务提交后,根据提交的 SCN,回填部分收集的记录,因为需要尽量保证提交的速度不受影响,仅仅根据当前记录数和系统的负载能力,回填少量的记录,并快速的提交返回客户。
Delayed Cleanout
查询过程中,在根据 UBA 地址回查事务槽 SCN,判断其事务状态以及提交版本号之后,如果事务已经提交,就尝试帮助进行行记录的 Cleanout, 我们称之为 Delayed Cleanout,以便下次查询的时候,直接访问行记录 SCN 进行可见性判断,减轻事务槽的访问。
Transaction Slot 复用
由于事务槽不能无限扩展,为了避免空间膨胀,采用 Reusing 方案。事务槽会持续的保存到一个 free_list 链表上,在分配的时候,优先从 free list 中获取进行复用。
另外频繁的访问 free_list 链表以及从 free_list 链表上摘取,需要访问多个数据页,这带来了巨大的开销,为了避免访问多个数据页,事务槽 page 会被先放入 cache 快表中,下次获取时直接从 cache 快表上获取,这大大降低了读多个数据页带来的开销。
▶︎ SCN 事务系统性能表现
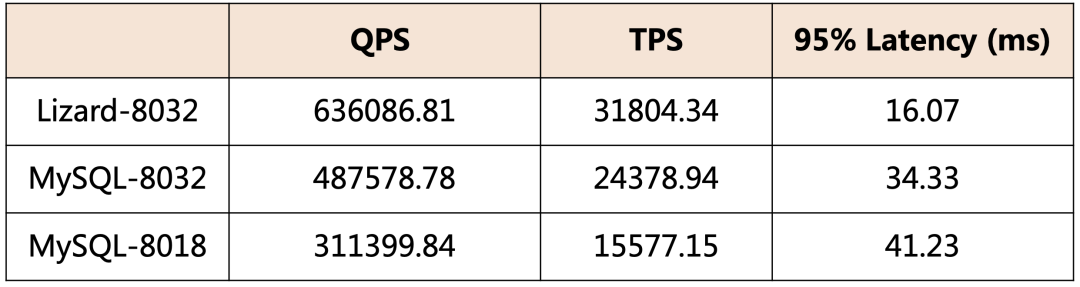 *注:以上数据测试环境为Intel 8269CY 104C,数据量为1600万,场景为Sysbench Read Write 512并发。
*注:以上数据测试环境为Intel 8269CY 104C,数据量为1600万,场景为Sysbench Read Write 512并发。关于Lizard GCN分布式事务系统相关内容将在下篇中深入介绍,敬请期待~
PolarDB分布式版 大降价 🎉



 点击阅读原文了解PolarDB分布式版降价详情
点击阅读原文了解PolarDB分布式版降价详情
