




IMCI执行器引擎使用经典的火山模型,但是借助了列存存储以及向量执行来提升执行性能。
火山模型中,SQL生成的语法树所对应的关系代数中,每一种操作会抽象为一个Operator,执行引擎会将整个SQL构建成一个Operator树,查询树自顶向下调用Next()接口,数据则自底向上被拉取处理。该方法的优点是其计算模型简单直接,通过把不同物理算子抽象成一个个迭代器。每一个算子只关心自己内部的逻辑即可,使得各个算子之间的耦合性降低,从而比较容易写出一个逻辑正确的执行引擎。
- 在IMCI执行引擎中,每个Operator也使用迭代器函数来访问数据,但不同的是每次调用迭代器会返回一批数据,而不是一行,可以认为这是一个使用了向量化模式的火山模型。
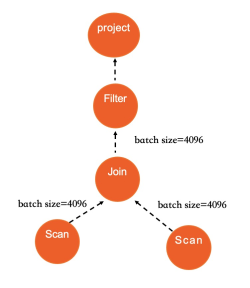
- 串行执行受制于单核计算效率、访存延时、IO延迟等限制,执行能力有限。而IMCI执行器在几个关键物理算子(Scan/Join/Agg等)上均并行执行。除物理算子需要支持并行外,IMCI的优化器也支持生成并行执行计划,优化器在确定一个表的访问方式时,会根据需要访问的数据量来决定是否启用并行执行,如果确定启用并行执行,则会参考一系列状态数据(包括当前系统可用的CPU/Memory/IO资源、目前已经调度和在排队的任务信息、统计信息、query的复杂程度、用户可配置的参数等)。 根据这些数据会计算出一个推荐的DOP值给一个算子,而一个算子内部会使用相同的DOP。同时,DOP也支持用户使用Hint进行设定。
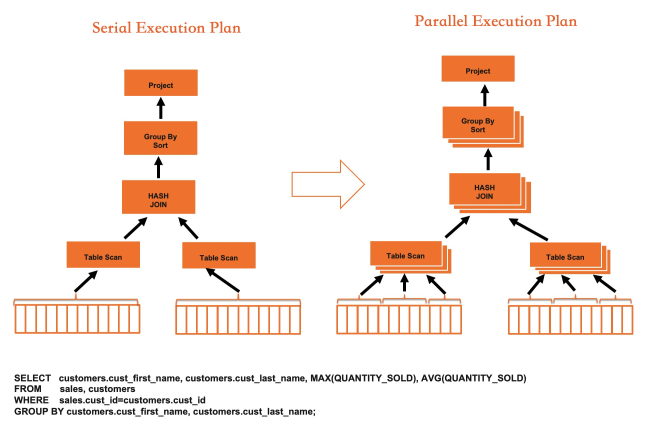
基于以上两点优化思路,重新实现了所有物理执行算子,包括TableScan、HashJoin、NestedLoopJoin、Groupby等。下面以HashJoin为例展示执行器的并行化及向量化加速效果。在IMCI中,HashJoin按如下流程执行:
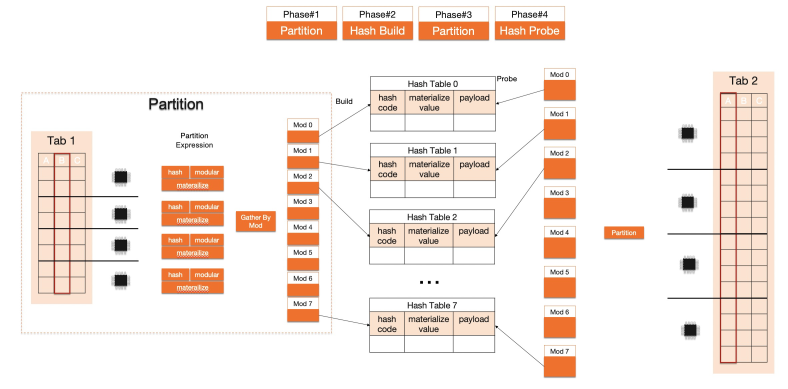
向量化执行解决了单核执行效率低的问题,而并行执行突破了单核的计算瓶颈。二者结合使得IMCI执行速度相比传统MySQL行式执行有了数量级的提升。
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
