




AP型场景,SQL中经常会包含很多涉及到一个或者多个值、运算符和函数组成的计算过程,这都是属于表达式计算的范畴。表达式的求值是一个计算密集型的任务,因此,表达式的计算效率是影响整体性能的一个关键的因素。
传统MySQL的表达式计算体系以一行为一个单位的逐行运算,一般称其为迭代器模型实现。由于迭代器对整张表进行了抽象,整个表达式实现为一个树形结构。但是,这种抽象会同时带来性能上的损耗,因为在迭代器进行迭代的过程中,每一行数据的获取都会引发多层的函数调用。同时,逐行地获取数据会带来过多的 I/O,对缓存也不友好。MySQL采用树形迭代器模型,是受到存储引擎访问方法的限制,导致其很难对这些计算复杂的逻辑进行优化。
而在列存格式下,由于每一列的数据都单独顺序存储,涉及到某一个特定列上的表达式计算过程都可以批量进行。对每一个计算表达式,其输入和输出都以Batch为单位,在Batch的处理模式下,计算过程可以使用SIMD指令进行加速。
向量化表达式的关键优化点:
- 充分利用列式存储的优势,使用分批处理的模型代替迭代器模型,使用SIMD指令重写了大部分常用数据类型的表达式内核实现。例如,所有数字类型(int、decimal、double)的基本数学运算(+、 -、*、/、abs),全部都使用对应的SIMD指令实现。在AVX512指令集的加持下,单核运算性能数倍提升。
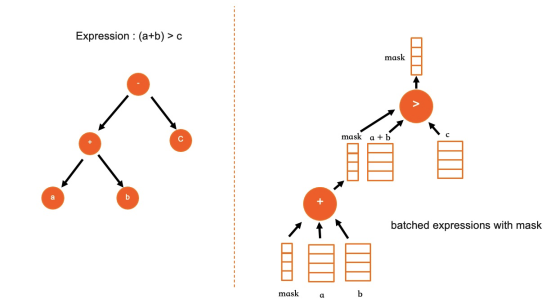
- 采用了与PostgreSQL类似表达式实现方法:在SQL编译及优化阶段,IMCI的表达式以一个树形结构来存储(与现有行式迭代器模型的表现方法类似)。但是,在执行之前会对该表达式树进行一个后序遍历,将其转换为一维数组来存储,在后续计算时只需要遍历该一维数组结构即可以完成运算。由于消除了树形迭代器模型中的递归过程,计算效率更高。同时该方法对计算过程提供简洁的抽象,将数据和计算过程分离,适合并行计算。
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
