




1. 前言
推荐算法是为了解决“信息过载和用户无明确要求的情况下,如何帮助用户找到感兴趣的物品”,而推荐算法需要一个持续优化的过程才能达到理想的一个效果,在优化过程中,如何衡量效果的好与坏,就需要引入AB实验
2. AB实验架构
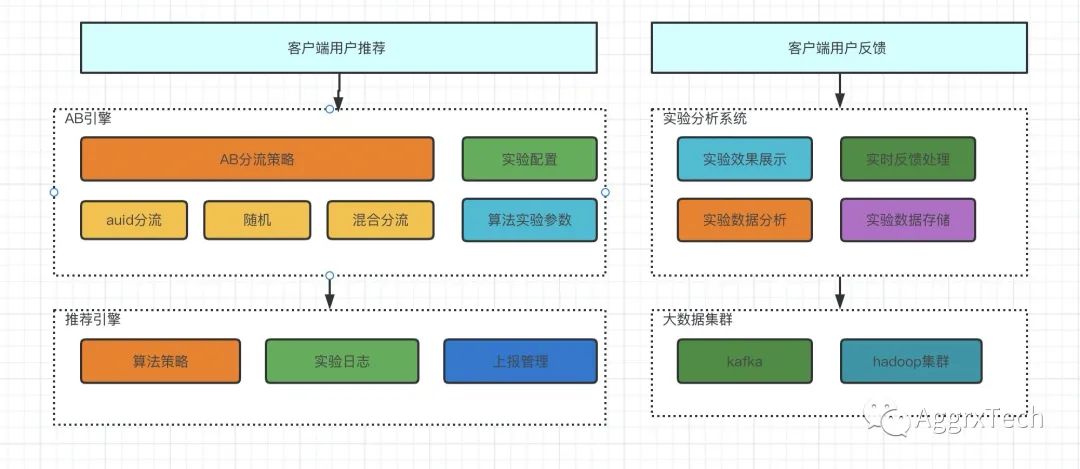 

AB引擎
主要负责分流,实验配置和算法参数配置
推荐引擎
根据不同的参数进行相应的算法和数据调整
实验分析
根据数据上报,对实验数据进行存储和分析,并展示实验效果
本文主要介绍AB引擎部分
3.实验引擎
3.1实验分组
AB实验中一般会分2个及以上个实验组,其中一个作为对照组,通过实验分组与对照组的数据进行对比来分析算法效果的好坏。
实际应用中会给每个分组定一个bucket标识,通过该标识对上报数据进行分组然后进行分析。
3.2实验分流
分流的目的定义什么样的请求进入对照组或者实验组,分流策略主要包括以下三种:
随机分流:对请求随机分配实验分组
优点:该策略比较简单,实现起来容易
缺点:对单个用户而言,分组策略不稳定
auid分流:对用户进行固定的实验分组
优点:确保每个用户的实验分组是稳定的,可以精确控制每个分组的流量
缺点:分组过于简单,无法应对更为复杂的分流策略
混合分流: 多种条件的组合分流,比如针对不同的版本和用户进行分流
优点: 分流策略丰富,可以应对这种场景
缺点: 实现起来相对复杂,由于分流策略的不同,很难保证分流逻辑的通用性
分流的实现:
随机分流公式: slot = random(slotsize)
uid分流公式: slot = abs(hash(auid))%slotsize
其中
uid: 用户的标识
slotsize: 分组的最大个数.
| 实验 | 流量 | slot值范围 |
|---|---|---|
| 对照组A | 20% | 0-199 |
| 实验组B | 80% | 200-999 |
以两个实验分组举例,slotsize=1000,通过分流公式,当slot值在0-199范围内,会被分到对照组A,slot值在200-999范围内时,会被分到实验组B
3.3实验参数
推荐算法中,包含了各种参数配置,通过修改参数的值来调整算法的效果,因此在AB实验中会对每个实验组绑定一组实验参数,通过分流和实验配置,把相应的算法参数传递给推荐引擎。
3.3.1实验数据结构定义
本文中使用protobuffer定义实验数据结构。protobuffer是google开源的一种数据格式,以扩展性强,兼容性强,支持跨语言。由于实验参数是经常变化的,使用protobuffer可以很容易的进行参数扩展
message RecommendParam{optional bool disablePersonalRecFeature = 1;optional bool disablePersonalRuleFeature = 2;optional bool disableFeedbackFeature = 3;optional int32 sourceTypeDiversifyTunerWebLimit = 4 [default = 2];optional int32 sourceTypeDiversifyTunerCycle = 5 [default = 10];optional bool enableSimilarTuner = 6 [default = true];optional double similarTunerThreshold = 7 [default = 1.0];optional int32 similarTunerCycle = 8 [default = 10];}message BucketGroup {optional string bucket = 1;optional int32 startSlot = 2; //起始slotoptional int32 endBuSlot = 3; //终止slotoptional RecommendParam param = 4; //实验参数}message Experiment {optional string name = 1; //实验名称optional string algorithm = 2; //算法标识optional bool enabled = 3; //是否启用repeated BucketGroup bucketGroup = 4;}message Experiments {repeated Experiment experiments = 1; // 实验列表}
RecommendParam: 实验参数,算法依赖的配置参数可以定义在这里,每个实验分组配置上不同的值
BucketGroup: 实验分组,包括slot范围和绑定的实验参数
Experiment: 实验定义,包括实验名称,算法标识,是否开启和分组定义
Experiments:实验列表,可以同时针对多个算法进行配置实验
3.3.2代码实现
实验配置已配置文件的形式进行定义,服务启动时加载实验配置。
public class ExperimentService {private final static int BUCKET_MAX_COUNT = 1000;/*** 桶实验参数*/private Experiments experiments;@PostConstructvoid postConsruct() {loadExperimentFile("experiments.conf");}/*** 解析实验配置文件** @param filePath*/public void loadExperimentFile(String filePath) {try {// 读取文件String content = FileUtil.readFileFromClasspath(filePath);Experiments.Builder builder = Experiments.newBuilder();JsonFormat.parser().ignoringUnknownFields().merge(content, builder);this.experiments = builder.build();log.info("success to update experiment file ");} catch (Exception e) {log.error("experiments get error: " + e.getMessage());}}/*** 获取slot编号** @param auid size* @return*/protected int getBucket(String auid, int size) {int hashCode = auid.hashCode();return Math.abs(hashCode) % size;}/*** 根据算法获取命中实验** @param action* @return*/protected Experiment getExperiment(String algorithm) {Experiment result = Experiment.getDefaultInstance();if (experiments != null) {for (Experiment experiment : experiments.getExperimentsList()) {if (experiment.getAlgorithm().equals(algorithm)) {result = experiment;}}}return result;}/*** 获取命中实验组** @param request* @return*/public BucketGroup getBucketGroup(String algorithm, String auid) {Experiment experiment = getExperiment(algorithm);if (experiment == null || !experiment.getEnabled()) {return BucketGroup.getDefaultInstance();}int bucket = getBucket(auid, BUCKET_MAX_COUNT);for (BucketGroup bucketGroup : experiment.getBucketGroupList()) {if (bucketGroup.getStartBucket() <= bucket && bucket <= bucketGroup.getEndBucket()) {return bucketGroup;}}return BucketGroup.getDefaultInstance();}}
4 总结
在实际开发中,需要用到多层的AB实验,所谓的多层AB实验是将多个实验串联起来的多层实验结构,每一次层实验使用的分流在下一层实验中接着使用,以后可以专门介绍一下多层实验的实现方式。如有错误的地方,欢迎留言指正。
