




典型的数据库管理系统会包含多个组件,每个组件负责不同的功能,而存储引擎主要负责数据的存储与查询,向 SQL 引擎组件提供主键插入、更新、删除、数据加锁、随机读取以及范围查询等操作,在进行查询操作时,SQL 引擎也可能将部分的过滤条件、表达式计算及 limit 操作下压到存储层,数据库功能层构建在存储引擎层之上。
本章将介绍 OceanBase 的存储结构和 Compaction 策略,以及数据的写入和查询流程。
3.1 LSM-Tree 介绍
LSM-Tree(Log Structured Merge Tree,结构化合并树)最早是在 1996 年由 Patrick O'Neil、Edward Cheng 等人在论文 《The Log-Structured Merge-Tree》 中提出,随后便在新数据库引擎中得到广泛应用,例如 HBase、Cassandra、RocksDB 等。OceanBase 也选择 LSM-Tree 架构搭建存储引擎。
目前业界中实现存储引擎的两大顶流数据结构是 B+ 树和 LSM-Tree,那么 B+ 树和 LSM-Tree 的差别在哪里?为何传统数据库更青睐 B+ 树,而新数据库引擎更偏爱 LSM-Tree 呢?
B+ 树与 LSM-Tree
B+ 树是平衡搜索树的一种,是为了磁盘搜索而诞生的。B+ 树的所有数据都存储在叶子节点中,每次查询或写入时需要从根节点搜索到叶子节点,再对叶子节点对应的位置进行操作(也就是原地更新)。传统数据库会将 B+ 树的每个叶子节点设置为一个磁盘页的大小,每次磁盘 I/O 就可以加载一个完整的叶子节点的数据到内存中,以此减少 I/O 的次数。
B+ 树查询、插入、删除的时间复杂度都是 O(logN)。
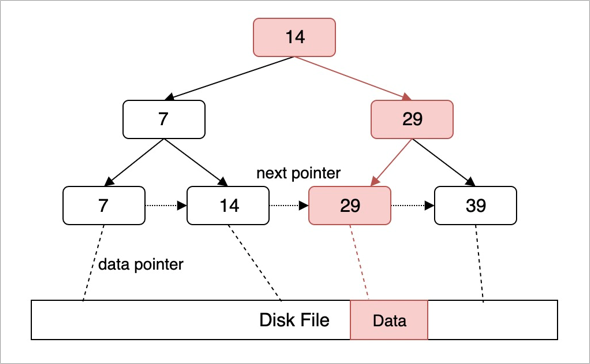
LSM -Tree 的核心思想就是将离散的随机写请求都转换成批量的顺序写请求。
当用户有数据写入时,会写入内存中的 MemTable 和数据日志 log,WAL(Write-Ahead Log) 机制保证重启后通过回放数据日志可以恢复到重启之前的状态。
当 MemTable 的数据量达到阈值,会将 MemTable 冻结为只读状态的 Frozen MemTable,冻结的同时会创建一个新的 MemTable 用于提供数据写入。后台会将 Frozen MemTable 的数据以 Rowkey 递增的次序顺序写入磁盘中,生成一个 SSTable。这个过程结束后,该 Frozen MemTable 与其对应的 log 可以被回收。
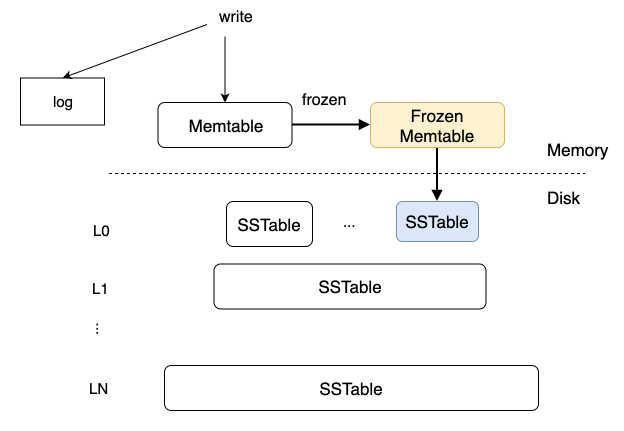
MemTable
MemTable 是纯内存状态,为了便于后续进行顺序读取生成磁盘上的 SSTable,一般采用排序树(红黑树/AVL 树)、SkipList 等这类有顺序的数据结构。
SSTable
SSTable 全称为 Sorted String table,是从 Google 的 BigTable 所借用的概念,意为内部有序的磁盘文件。数据按照 Key 排序,可以使用二分搜索的方式快速得到指定 key 的数据。
磁盘上的 SSTable 被划分为多个层级(Level),层级数字越低表示数据被写入的时间越近,层级数字越大表示数据越旧。
DML 操作
对于传统的数据库来说,UPDATE 和 DELETE 可以直接原地更新,但是由于 LSM-Tree 是 append only 类型,UPDATE 和 DELETE 都需要作为额外的一个行写入。这会导致一个 key 如果发生了多次更新,在整个 LSM-Tree 中会存储多个行。
LSM-Tree 中的所有查询都会先从 MemTable 中开始查询,若 MemTable 中未发现该 key 的完整数据,再从 L0、L1 直到 LN 进行查询,直到查询到 LN 层返回 key 不存在、得到完整的行数据或者查询到 DELETE 行。
为什么 OceanBase 选择了 LSM-Tree
B+ 树有原地更新和定长块的假设,这使得 B+ 树的数据块是不适合做压缩的,如果对数据块做了压缩会导致原地更新还需要额外的解压和压缩操作,将导致查询性能非常差。而 LSM-Tree 是 append only 的模式,没有原地更新,将所有的 UPDATE/DELETE 操作都写做额外的数据,并且 SSTable 中的数据没有定长块的限制,压缩就变得比较自然。
后续 OceanBase 如果扩展到 OLAP 领域,列存就是一个绕不开的技术点。列存的设定是数据量大,且更新较少。那么 B+ 树原地更新的优势在列存场景也会被削弱,在按列存储的模式中要对多列进行原地更新,实现难度比较大,代价也较高。LSM-Tree 的 delta 更新更适合列存场景。
