3.2 Compaction 策略介绍
随着用户数据写入 MemTable,MemTable 超过内存阈值转化为磁盘上的 SSTable,SSTable 的数量会持续增多,导致查询需要访问的 SSTable 文件增多,降低查询的效率,因此引入了 LSM-Tree 最核心的概念:Compaction。
LSM-Tree 的 Compaction 操作是对数据的一次重新整合,其实质是多路归并排序,将若干个 SSTable 按照 Rowkey 递增排序,最后输出为一个 SSTable。
Compaction 虽然对于查询效率的提升效果显而易见,但是 Compaction 的执行过程是一个大量消耗机器资源的操作,过多的 Compaction 会导致资源倾斜到 LSM-Tree 重整的步骤中,而非用户的查询写入操作。
由于 Compaction 涉及磁盘上 SSTable 数据的读取和写入,这将占用大量 I/O 带宽;在读取和写入过程中涉及数据的压缩和解压、密集的 key 比较,是 CPU 密集型计算;而 Compaction 完成后会出现大量 Cache 失效等问题,造成性能抖动。比如内存中 MemTable 变成 SSTable 后,对内存 MemTable 的查询会变成对磁盘 SSTable 的查询,使得查询的耗时变长。
如何权衡 Compaction 带来的查询提速收益和 Compaction 占用的资源,这也是业界在持续关注的问题。
通用 Compaction 策略
说到 Compaction 就不得不提的三个概念:写放大、空间放大、读放大。
不同的 Compaction 策略其实是对三个维度的一个权衡,我们首先介绍三种权衡的定义:
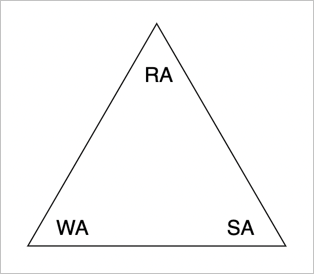
写放大(Write Amplification)= 磁盘写入的数据量 / 实际写入的数据量
用户写入了一行数据,在 LSM-Tree 中可能触发若干轮的 Compaction 导致其他数据被读出写入,原本只是一行数据的 I/O 写入却被放大为 N 倍数据量的 I/O。
空间放大(Space Amplification)= 存储的数据量 / 实际存在的数据量
所有的写入都是顺序 append 写的,不是原地更新 ,所以过期数据不会马上被清理掉,相同 Rowkey 的行在多个 SSTable 都可能存在。因此实际存储的数据量会比实际存在的数据量大很多。
读放大(Read Amplification)= 本次扫描的数据量 / 实际返回的数据量
查询时需要从新到旧访问所有的 SSTable 直到查询到完整的数据,所以会导致扫描的行数比实际存储的行数更多。
业界常用的 Compaction 策略有 Classic Leveled、Size-Tiered、Tiered & Leveled 、FIFO 等。接下来我们将详细介绍每种 Compaction 策略的设计理念,并整体分析每种 Compaction 策略的优点和缺点。
Classic Leveled
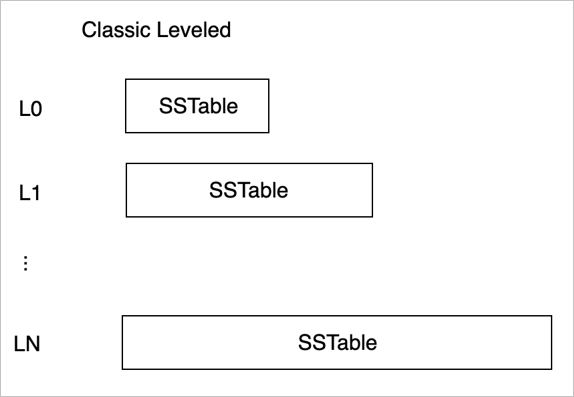
在 Classic Leveled 模式中,LSM-Tree 依然划分为 N 个 Level,每个 Level 仅包含一个 SSTable;相邻 Level 的 SSTable 大小有一个倍数关系,这个 size 的倍数通常被称为 fanout(扇出)。
Compaction 的触发是由于某个 Level 的数据量超过了阈值。在 Compaction 时会选择 L(n-1) 的数据,与原有 L(n) 的数据 Rowkey 有交集的部分进行合并,得到新的 L(n) 数据。使得在最差的情况下,写放大可以达到 fanout。
Leveled 策略比较容易存在雪崩效应:当每个 Level 的 SSTable 数据量都接近 Compaction 阈值的时候,在 L0 层写入数据会触发 Compaction,使得 L1 层数据量增加也达到触发 Compaction 阈值,集联反应导致后续每个 Level 都触发了 Compaction。
Size-Tiered
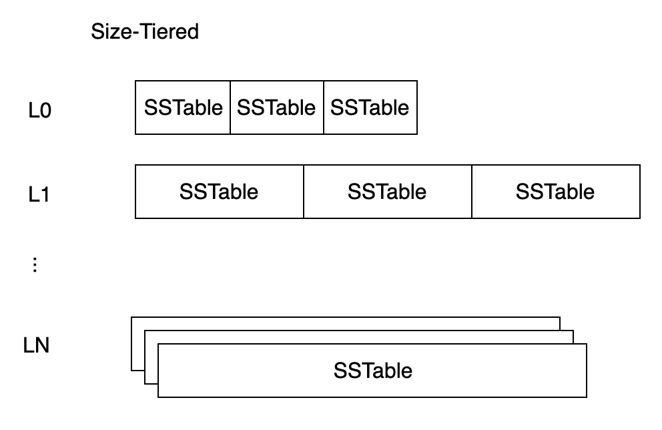
Size-Tiered 模式中,LSM-Tree 也被划分为 N 个 Level,每个 Level 可以包含多个 SSTable。相同 Level 的 SSTable 的 key range 可能存在交集。在查询时需要访问这个 Level 所有的 SSTable,使得读放大比较严重,查询性能不佳。
Compaction 的触发条件是某个 Level 的 SSTable 数量超过了阈值,会将 L(n) 的若干 SSTable,合出一个新的 SSTable 放入 L(n+1),并不与原有 L(n+1) 的数据进行合并。相比于 Leveled 而言执行速度会更快,写放大会更优,但由于查询的 SSTable 数量变多,读放大会更差。
Leveled、Tiered 两种模式的优缺点非常鲜明,但是对于现实场景而言都不太合适,取长补短的混合模式更受数据库引擎的欢迎。
Tiered & Leveled
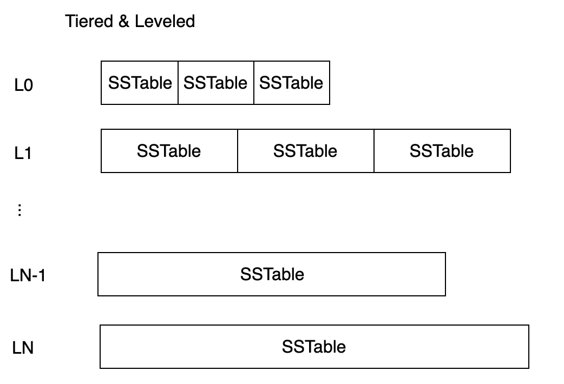
Tiered & Leveled 模式是指对于层级较小的 Level,数据量比较小,写入的数据较新,被更新的可能性比较大,使用 Size-Tiered 模式减少写放大问题;对于层级较大的 Level,SSTable 的数据量较大,数据比较旧不太容易被更新,使用 Leveled 模式减少空间放大问题。
RocksDB 和 OceanBase 都是使用 1-leveling 的策略,即 L0 层为 Tiered 策略,其余层级为 Leveled 策略。
FIFO
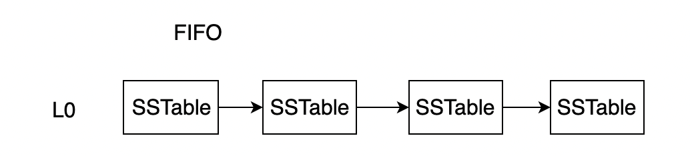
FIFO 模式中 LSM-Tree 只包含一个 Level,所有 SSTable 都在 L0 中;SSTable 以时间序排列,每次淘汰生成时间最早的 SSTable。
FIFO 几乎是最简单的 Compaction 策略,但是会丢数据,比较适合时序数据库这类有时间属性和时间效用的数据。
策略比较
针对上述常用的 Compaction 策略,我们列出一个对比的表格来比较每种 Compaction 策略的设定、优势和劣势。Compaction 策略本身没有好坏的差别,LSM-Tree 引擎也都会根据自己的使用场景使用最合适的 Compaction 的策略。
| Leveled | Tiered | Tiered & Leveled | |
|---|---|---|---|
| SSTable 设定 | 每个 Level 包含一个 SSTable | 每个 Level 包含多个 SSTable,相同 Level 的 SSTable 的 Rowkey range 交集 | 层级较小的使用 Tiered,层级较高的使用 Leveled |
| Compaction | L(n) + L(n+1) = new L(n+1) | several L(n) = new L(n+1) | |
| 权衡 | 写放大会变差,读放大和空间放大会变好 | 读放大和空间放大会变差,写放大会变好 | 写放大比 Leveled 更佳 读放大/空间放大比 Tiered 更优 |
| 代表数据库 | RocksDB 的 Major Compaction | Cassandra 的 SizeTiered Compaction Strategy、RocksDB 的 Universal Compaction | RocksDB 的 Leveled Comapction、OceanBase |
在三种 Amplification 权衡中,空间放大呈伴随状态出现,通过读放大可以推导出空间放大;而读放大和写放大呈对立态势,互相拉扯,无法同时达到最优,这就像鱼和熊掌一样不可兼得。
Leveled Compaction 追求读放大最优就是寻求局部极优,而 Tiered & Leveled Compaction 是寻求一种读放大和写放大的平衡,是一种帕累托最优。
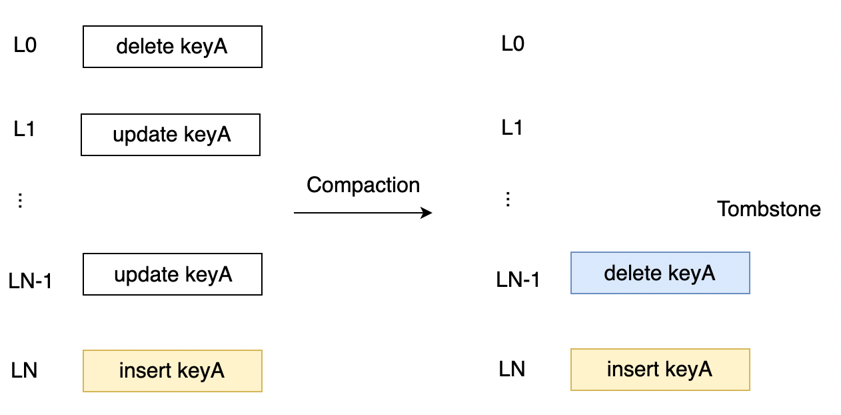
墓碑问题
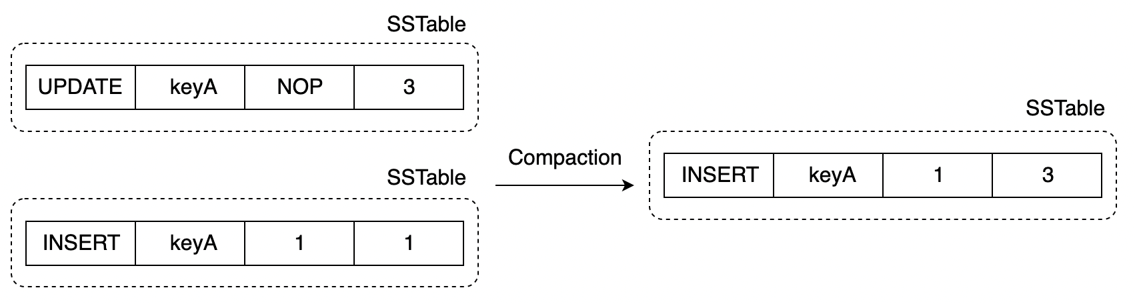
随着 Compaction 的执行,相同 Rowkey 所有行会进行从新往旧地 compact,以此减少空间放大。
但是,如果一个 Rowkey 有 DELETE 操作,理论上该 Rowkey 的所有行(包含 DELETE 行)都可以直接删除,但是需要保证所有 Level 的行中关于这个 Rowkey 的行都被删掉,所以 DELETE 行的 compact 结果需要保存,直到这个 DELETE 行与最底层 Level N 进行 Compaction,DELETE 行才可以被删去,这也就是 LSM-Tree 的墓碑问题(TombStone)。