




3.3 OceanBase 的 Compaction 设计
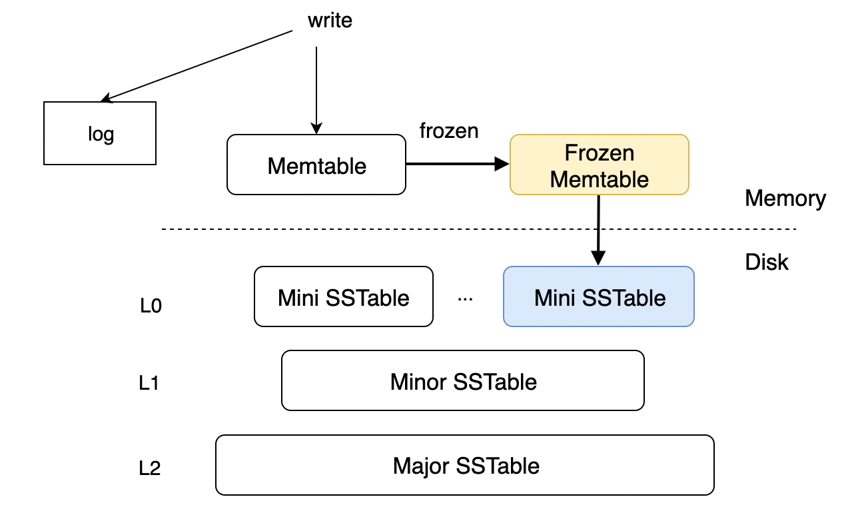
在 OceanBase 中 LSM-Tree 的设定和传统的设定比较类似,也是划分为内存中的 MemTable 和磁盘上的 SSTable。OceanBase 将磁盘上的 SSTable 划分为三层,使用的是 Tiered & Leveled 的 Compaction 策略,在 L0 层使用 Tiered 模式,在 L1 层、L2 层使用 Leveled 模式。
Compaction 类型
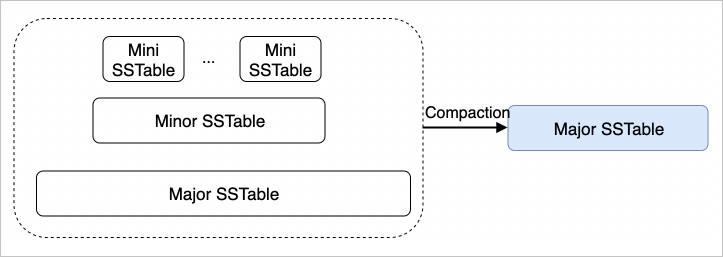
OceanBase 中的 Compaction 分为三种类型:Mini Compaction、Minor Compaction、Major Compaction。下面将分别介绍这三种类型。
转储/Mini Compaction
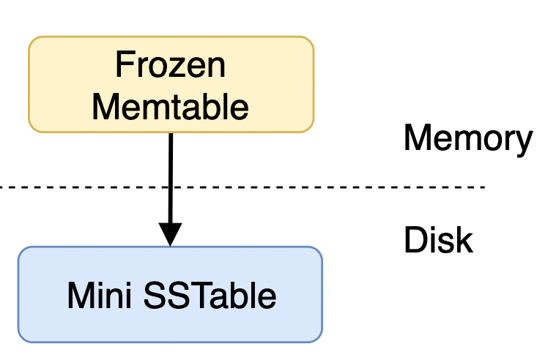
Mini Compaction 是一种 Tiered 类型的 Compaction,核心就是释放内存和数据日志。内存中的 Frozen MemTable 通过 Mini Compaction 变成磁盘上的 Mini SSTable,是数据日志的一个 checkpoint。Mini Compaction 结束后,其对应的 Frozen MemTable 和 log 可以被释放。
Minor Compaction
随着用户数据的写入,Mini SSTable 的数量会逐渐增多,在查询时需要访问的 SSTable 数量会增多,会影响查询的性能。Minor Compaction 就是将多个 Mini SSTable 合成一个,主要目的是减少 SSTable 的数量,减少读放大问题。当 Mini SSTable 的数量超过阈值时,后台会自动触发 Minor Compaction。
Minor Compaction 可以细分为如下两类:
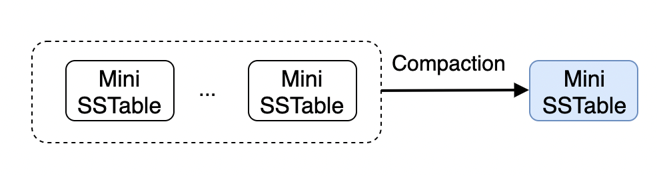
L0 -> L0
Tiered 类型的 Compaction,将若干个 Mini SSTable 合成一个 Mini SSTable,放置于 L0 层。
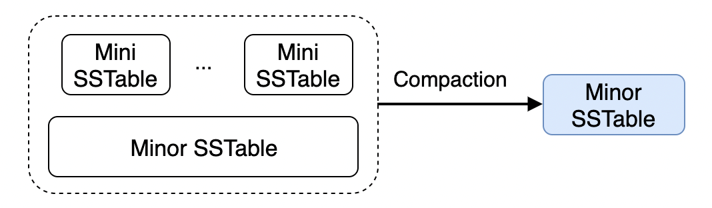
L0 - > L1
Leveld 类型的 Compaction,将若干个 Mini SSTable 与 Minor SSTable 合成一个新的 Minor SSTable,放置于 L1 层。
Tiered 模式和 Leveled 模式在上一节 3.2 Compaction 策略介绍 中已经进行过介绍,Tiered 类型更适合数据量较少的情况,当 Mini SSTable 的数据量较大,并与 Minor SSTable 的数据量相近时,则选择 Leveled 类型,减少读放大问题。可以根据实际情况判断选择哪种类型的 Minor Compaction。
合并/Major Compaction
整个集群选择统一的 Major 位点,每个分区都使用该 Major 位点做快照查询,并将查询结果进行持久化生成 Major SSTable。
合并触发有三种触发方式:自动触发、定时触发与手动触发。
自动触发:当用户做 Mini Compaction 的次数过多,积累的 SSTable 数量过多便触发一次 Major Compaction,缩减 SSTable 的数量,降低读放大。
定时触发:合并作为一个耗费资源的操作,应尽量避免在业务高峰期执行,用户可以通过设置触发时间,在业务低峰期定时触发合并。
手动触发:使用命令
ALTER SYSTEM MAJOR FREEZE;触发。
Compaction 算法
下面以合并/Major Compaction 为例介绍 OceanBase 所有的 Compaction 算法和 Compaction 机制。
全量合并
全量合并是 OceanBase 数据库的一种合并算法,和 HBase 与 RocksDB 的 Major Compaction 过程类似。顾名思义,在全量合并过程中,会把当前的 Major SSTable 数据都读取出来,和所有的 Mini SSTable 合并后,再写到磁盘上去作为新的 Major SSTable,在这个过程中,会把所有数据都重写一遍。全量合并会极大地耗费磁盘 I/O 和空间,如非必要或者 DBA 强制指定,OceanBase 数据库一般不会主动做全量合并。
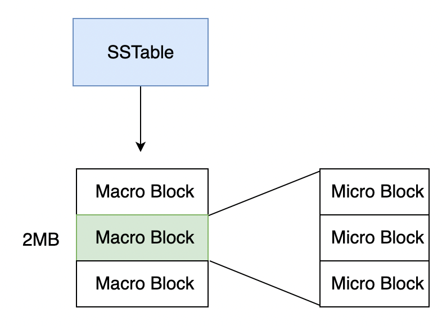
OceanBase 的 SSTable 是一组 2MB 定长宏块(Macro Block)的集合,每个宏块是若干个微块的集合,微块是 I/O 的最小单位。在 SSTable 中部分宏块没有被修改的情况下,其实并不需要重写,可以原封不动地放到新 Major SSTable 中。因此,在全量合并时,如果一次合并中 Mini SSTable 修改了一行数据,此时把整个 Major SSTable 都重写一遍确实不合理,因此提出了增量合并算法。
增量合并
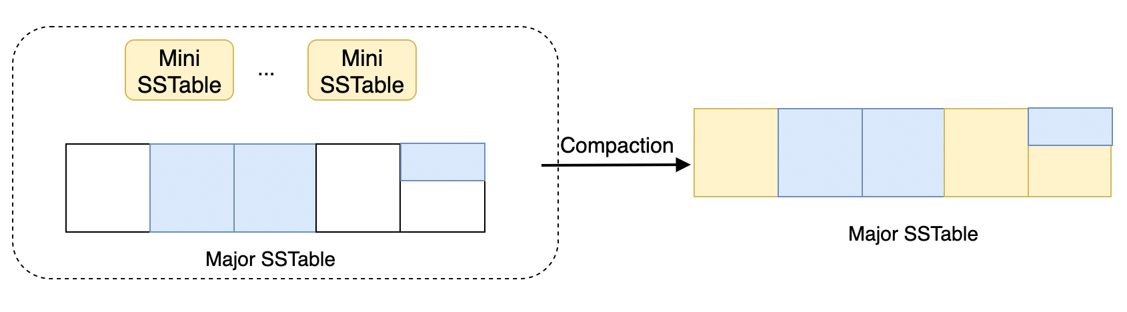
增量合并是相对于全量合并而言的概念,同样是 OceanBase 数据库的一种合并算法。大多数情况下,当需要进行合并时并不是所有的宏块都需要被修改,当一个宏块没有被修改时,直接重用它,而不是重写它,这种方式称之为增量合并。相对于全量合并把所有的宏块重写一遍而言,增量合并只重写发生了修改的宏块。增量合并极大地减少了合并的工作量,也是 OceanBase 数据库目前默认的合并算法。
更进一步地,对于宏块内部的微块,很多情况下也并不是所有的微块都会被修改。对于没有修改过的微块可以直接拷贝到新的宏块上,这样没被修改过的微块就省去了解析行、编解码以及计算列 Checksum 等操作。微块级增量合并进一步减少了合并的时间。
增量合并是出于改善写放大而提出的算法,减少重写的数据量,以此加快 Compaction。
渐进合并
在执行某些 DDL 操作时,例如执行表的加列、减列、修改压缩算法等操作后,可能需要将数据重写一遍。OceanBase 数据库并不会立即对数据执行重写操作,而是将重写动作延迟到合并时进行。如果要将数据全部重写便从增量合并回退到了全量合并,使得合并的耗时变长。
为此 OceanBase 数据库引入了“渐进合并”,即把数据的重写分散到多次合并中去做,在一次合并中只进行部分数据的重写。
示例:通过以下命令可以控制一张表的渐进轮次
alter table t1 set progressive_merge_num = 60;
将表 t1 的渐进轮次设置为 60,在执行加列或减列操作后的 60 次合并过程中,每一次合并会重写 60 分之一的数据,在 60 轮合并过后,数据就被整体重写了一遍。
轮转合并
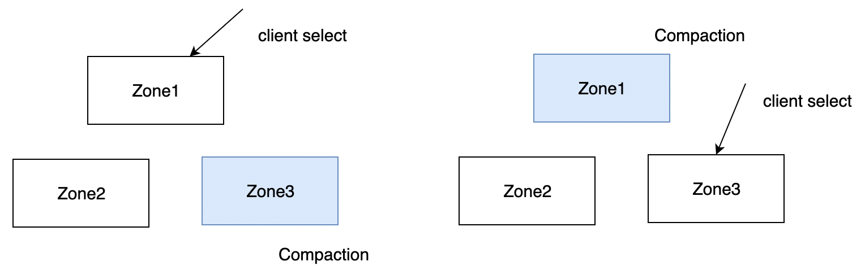
一般来说合并会在业务低峰期进行,但并不是所有业务都有业务低峰期。在合并期间,会消耗比较多的 CPU 和 I/O,此时如果有大量业务请求,势必会对业务造成影响。为了规避合并对业务的影响,借助 OceanBase 数据库的多副本分布式架构,引入了轮转合并的机制。
一般配置下,OceanBase 数据库会同时有 3 个数据副本,当一个数据副本在进行合并时,可以将这个副本上的查询流量切到其他没在合并的副本上面,这样业务的查询就不受每日合并的影响。等这个副本合并完成后,再将查询流量切回来,继续做其他副本的合并,这一机制称之为轮转合并。
并行合并
当合并参与的 SSTable 数据量特别大时,整个合并的过程会非常耗时。因此 OceanBase 提出了并行 Compaction 机制:将整个完成的 Rowkey 值域按照系统参数 tablet_size 划分为若干个子任务,子任务可以由多线程并发执行,当所有子任务执行结束之后本次合并才算结束。
并行合并默认开启,对于超大分区后台自动划分并行任务。系统默认的 tablet_size 大小为 128MB。
