




4.3 查询优化
OceanBase 的查询优化也就是怎么把一个改写后的 SQL 生成最终的物理执行计划。优化过程简单来讲就是枚举所有等价的执行计划,对于每一个执行计划,优化器利用统计信息和代价模型计算执行计划的代价,之后从中选择代价最小的计划。本文将详细介绍如何进行计划枚举。
计划形状
在讲计划枚举的细节之前,先简单的讲一下 OceanBase 支持哪些计划形状。目前 OceanBase 支持了 bushy、left-deep、和 deep tree。
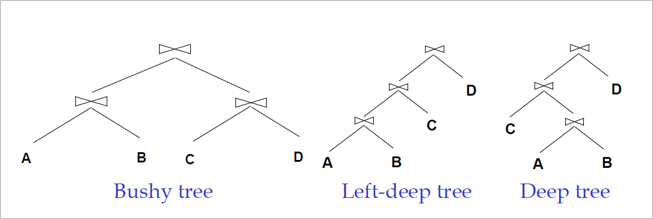
bushy tree:允许连接的两侧都是一个连接。
left deep:连接的右侧必须是一个基表,对应的还存在 right deep tree 表示连接的左侧必须是一个基表。
deep tree:连接的其中一侧是一个基表。
大部分的数据库系统都不支持 bushy tree 或者是默认不生成 bushy tree。因为一旦打开 bushy tree,计划空间会呈指数级增长,导致计划生成代价过高。OceanBase 数据库默认也是不生成 bushy tree 的计划的,当然 OceanBase 也提供了 hint 的机制允许用户指定 bushy tree 的计划。
说明
默认的情况下,OceanBase 会生成 deep tree 形状的计划,也就是常说的 zig zag tree。
这里举一个比较简单的例子,是一个非常简单的两表连接。
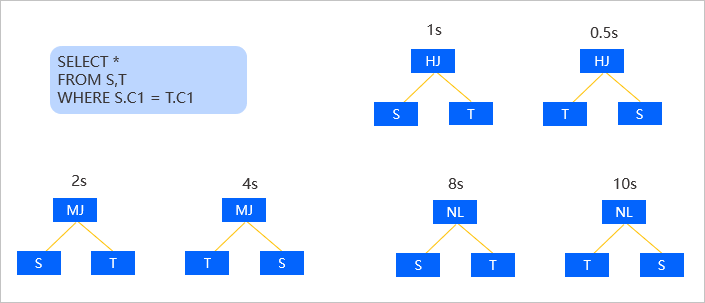
假设在不考虑索引的情况下,那么这两表连接会生成 Hash Join 的计划、Merge Join 的计划和 Nest Loop Join 的计划。然后会交换左右表的顺序,再生成一次这三种连接的计划。也就是说这一个简单的两表连接就会有 6 种计划。
从此例可以看出,计划枚举是一个非常难的问题,这里面最难的一点在于他的计划空间特别大。以星型查询为例,星型查询中间有一个事实表,这个事实表跟很多的维度表连接,这是一个典型的 OLAP 场景。
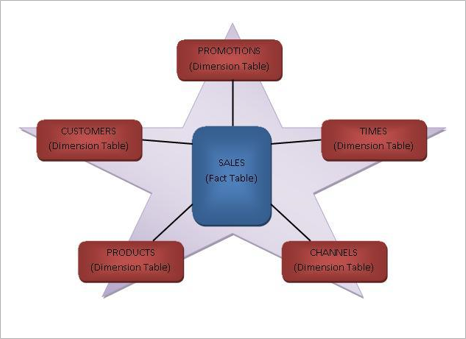
在这种场景下,假设当连接表达到 25 个表,这个时候在不考虑物理算子实现、不考虑基于代价的改写、不考虑分布式优化的情况下,逻辑计划的数量已经就有两亿多个了,这个量级其实非常大的。如果把物理算子实现、基于代价改写、分布式优化都考虑进去,以 TPCH 为例,Q2 这条 SQL 其实就有 40 亿个逻辑计划,Q8 也有 7.5 亿个逻辑计划。
由此可见,如何在海量的计划空间中高效地枚举计划是一个非常难的问题。
枚举算法
枚举算法方面,OceanBase 支持了动态规划算法和线性算法。
动态规划算法适用于表的个数不多的情况,因为动态规划算法的开销是非常大的,所以当连接表的数量非常多时,比如当连接表超过十个的时候,可能计划的枚举空间就已经非常大了,这个时候会把它回退成一个线性的算法。这个线性的算法是一个启发式的,能够让这个计划快速的收敛。当然,线性算法生成的计划在一些场景下是不好的,因此在后续的版本中我们也做了改进,使用贪心算法来替换了线性算法。
在 OceanBase 中,小于十张表的场景下采用的是动态规划算法。动态规划是一个按照 size 去做迭代的一个算法,这里 size 表示的是表的数量。在实现上,首先会枚举所有 size 为 1 的表的执行计划,也就是枚举单表的最优执行计划。
说明
这实际上就是做基表访问路径选择,也就是访问一个基表的时候应该走主表还是走索引。在 OceanBase 中,基表访问路径选择存在前置规则和 skyline 剪枝两种优化策略,详细信息请参考下文 4.4 基表访问路径选择策略。
动态规划算法
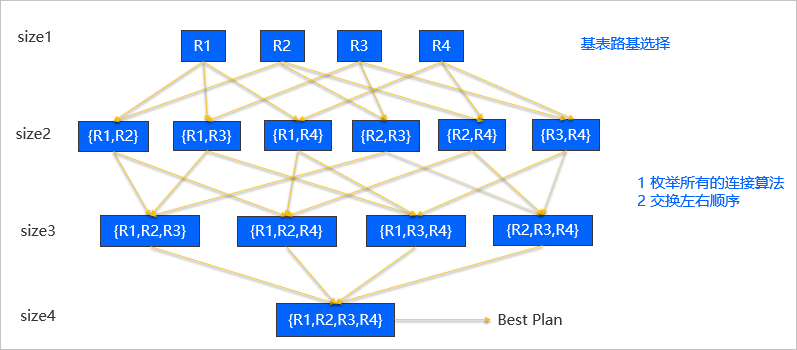
当基表访问路径生成完成后,也就是 size 为 1 的表的计划生成完成后,会继续生成 size 为 2 的表的计划。我们会一次生成 R1 join R2 的计划,R1 join R3 的计划,R1 join R4 的计划, R2 join R3 的计划, R2 join R4 的计划,R3 join R4 的计划。
比如生成 R1 join R2 的的计划的时候,我们会枚举所有连接算法的 R1 join R2 的计划,也会左右交换顺序,生成所有连接算法的 R2 join R1 的计划。并从中保留最优的执行计划集合。
生成完 size 为 2 的表的计划后,接下来会依次生成 size 为 3 和 size 为 4 的计划。当 size 为 4 的表的计划生成完成后,就得到了所有表连接的最优计划集合。
那么最优计划集合包含什么样的计划呢?一个是代价最小的计划,另一个是有 Interesting order 的计划。Interesting order 的概念在 4.4 基表访问路径选择策略 skyline 剪枝中将会介绍。
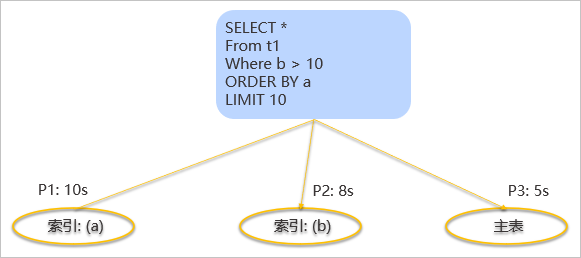
如上图所示,索引表索引 a 是有 Interesting order 的。如果走索引 a 预估代价是要花费 10 秒。走索引 b 的代价是 8 秒,但是索引 b 没有 Interesting order。走主表的代价是 5 秒,主表也是没有 Interesting order。这个时候,首先会保留主表(代价最小),然后也会保留索引 a(有 Interesting order)。
这是为什么呢?因为该索引表本身就是按照索引 a 有序,所以不需要去排序就可以直接取前十行,直接就找到了满足要求的所有的数据。如果去走主表或者是走索引 b,那一定是要把索引表的数据去按索引 a 排一次序,然后才能去取前十行。所以走索引 a 其实是可以省掉这个排序的操作的,因此我们会把这个计划也保留下来。
分配完 join order 后,接下来会按照 SQL 的逻辑依次分配所有其它的算子,比如 group by 算子,窗口函数算子,order by 算子,limit 算子等。这里的分配逻辑其实跟 join order 的计划分配是一样的。
例如 join order 分配完成后最优计划集合有两个,一个是 Merge Join 的计划,一个是 Hash Join 的计划。那么这两个计划一定是代价最小的计划或者是有 Interesting order 的计划。比如 Hash Join 的计划是代价最小的计划,Merge Join 的计划是有 Interesting order 的计划。这个时候要去分配 group by 算子。
在 OceanBase 中 group by 算子其实是有两种实现的,一种是 Merge group by,一种是 Hash group by。对于每一个计划,我们会去给他分配一个 Hash group by,然后分配一个 Merge group by。这样就得到了四个计划,然后依然会从这四个计划中来保留代价最小的以及有 Interesting order 的。
然后后面其他所有算子都是这个逻辑,就是在最优计划集合里分配出所有的算子实现,按算子实现分配出所有计划,然后去保留代价最小的和有 Interesting order 的。
当所有算子分配完成之后就得到了整个计划的整条 SQL 的最优执行计划的集合。从里面取出代价最小的计划就得到了所需要用的计划了。
