




4.5 执行引擎简介
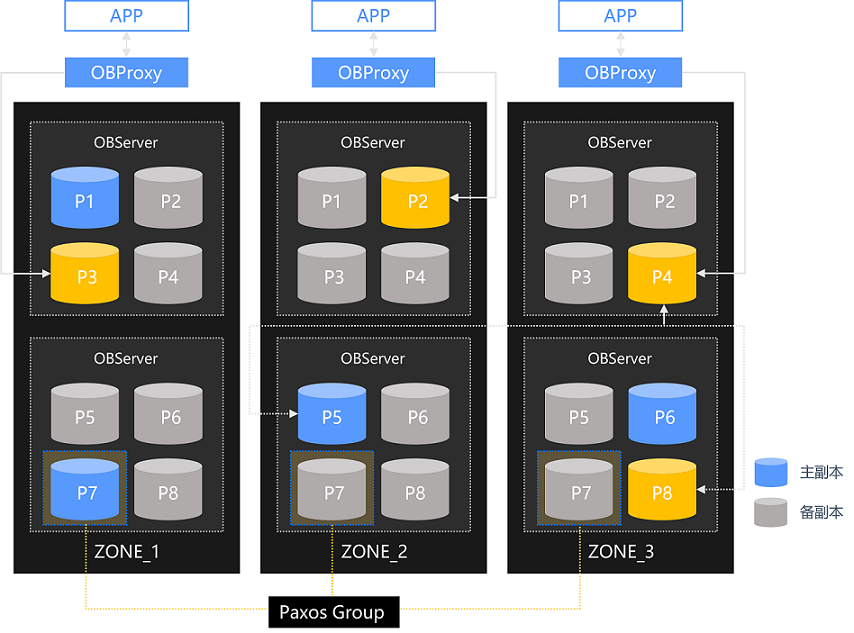
OceanBase 是一个 Share-Nothing 的分布式架构,一个集群中存在多个 OBServer 节点,每个 OBServer 节点都完全对等,同时可以提供读写请求。一个表存放在 OceanBase 数据库里可以按一定的方式进行分区,每个分区都会存在三个副本(一个主副本和两个备副本),分布在不同的 OBServer 节点中。对于强一致性读来说,客户端发起一个请求后,会先发给 ODP,由 ODP 路由到主副本所在的 OBServer 节点上执行。
执行引擎作用
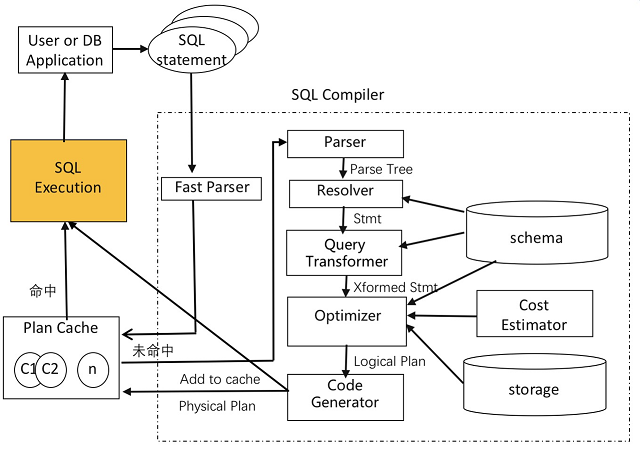
OBServer 节点在接收到一个请求后,首先会进入到 SQL 引擎。通过 Fast Parser 进行参数化,之后使用参数化的 SQL 作为 Key 去 Plan Cache(执行计划缓存)中查看是否存在匹配的执行计划缓存。如果存在,就直接将执行计划传递给执行引擎开始执行。反之就需要重新进行硬解析,生成执行计划,将生成的执行计划交给 Plan Cache,同时把这个执行计划传递给执行引擎去执行。执行引擎会按照给定的执行计划开始执行,并将结果返回客户端。
发展历程
OceanBase 执行引擎经过了多年的演进,早期功能相对较弱,是一个弱数据类型计算,也不支持算子落盘。
第二代执行引擎
从 2017 年开始,OceanBase 对执行引擎进行重新设计,实现了如下功能:
引入强数据类型计算
静态内存预分配
支持算子落盘
自适应的算子内存管理
第二代执行引擎的实现使用的是传统的火山模型,也就是迭代器模型。执行计划由多个算子组成,每个算子由标准的接口实现,即 open/next/close 这 3 个接口。
open 接口:初始化算子执行需要的上下文信息。
next 接口:从下层算子一行一行的获取数据,经过计算后会向上层算子返回一行数据。整个模型是一个数据拉取的模型。
close 接口:执行结束后对算子执行的相关信息进行清理。
这个模型的好处在于实现非常简单,并且非常灵活,易于扩展。每个算子之间的实现是完全解耦的。如果需要新实现一个算子,比如实现了 Hash group by 算子,还要实现一个 Merge group by 算子,此时完全不需要考虑 Hash group by 算子的逻辑,按照接口的约定实现一个新的逻辑算子就可以,之后优化器会根据需要选择使用这个算子。
OceanBase 第二代执行引擎中,数据还是按行迭代的。并且对于原本的执行引擎进行了重写,引入了一些新的设计。
强类型计算
之前的引擎设计是弱类型设计,导致本来在编译期可以做的事情都放到了执行期去做。比如根据数据类型的不同需要选择不同的比较方法,并且在执行期每一行都需要进行该操作,开销很大。引入强类型之后,在编译期就可以确定数据的类型,并且选择出执行期需要使用的比较方法,在执行期可以直接调用该方法。
执行内存预分配
内存预分配是指在编译期确定执行过程中迭代及计算涉及到的表达式内存分布,在执行前预分配需要的内存,执行时重复使用,不需要再反复申请内存。
使用表达式列表进行行描述,并且每一个表达式都会对应有一个存储实际数据的结构(Datum)。
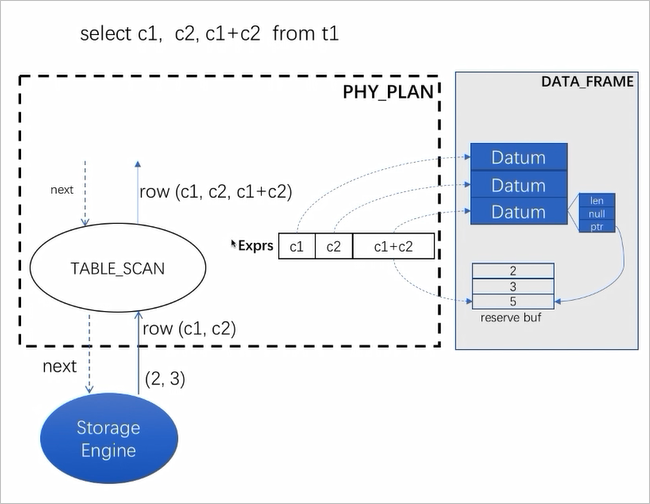
比如上图所示 SQL,执行计划就是一个 TABLE_SCAN 算子,涉及的表达式有三个:c1、c2 和 c1+c2。在生成执行计划过程中就会分析出这三个表达式以及表达式执行过程中需要的总内存,也就是执行前需要预分配的 DATA_FRAME 内存。DATA_FRAME 中会存放每个表达式对应的存放数据的 Datum,每个 Datum 都会预留一部分 buffer。
那这个 SQL 在整个执行过程中是怎么执行的?
执行前预分配出 DATA_FRAME 的内存。
驱动调用 TABLE_SCAN 算子的 next 接口。
该 next 接口继续向存储层调用 next 接口。
存储层向 SQL 层吐出一行数据,示例中吐出的数据是 (2, 3),这行数据会对应的填充到 (c1, c2) 这个表达式对应的预分配内存里。如上图所示,将 (2, 3) 填充到 reserve buf 中。
TABLE_SCAN 算子在输出的时候输出 c1,c2 和 c1+c2 这 3 个表达式数据。而 c1,c2 在前面步骤中就已经填充到了对应的预分配内存中,此时只需要对 c1+c2 进行计算,计算完成之后将结果填充到对应的预分配内存中。
把整个结果返回给客户端。
说明
如果需存储多行数据可以反复迭代,步骤和上述流程一致。预分配的内存可以反复使用,中间不需要再分配多余的内存。
第三代执行引擎
到了 2019 年,OceanBase 实现了第三代执行引擎,也就是向量化执行引擎,整个执行性能得到了大幅提升。功能如下:
向量化处理逻辑
硬件特性挖掘(预取、SIMD 等)
Cache-aware 算子优化
基于编码的 filter 下压
OceanBase 数据库在 2021 年 TPCH 打榜中获得世界第一的成绩,也正是使用了第三代的执行引擎。关于第三代执行引擎的详细信息请参考 4.6 向量化执行。
