




总体设计
综合上述调研和分析,基于现有的成熟方案,针对深翻页问题,PolarDB MySQL版重新设计了IMCI的Sort/TopK算子:
- 内存充足时,采用如下的内存算法:
- 采用Self-sharpening Input Filter的设计,避免访存效率的问题。
- 并在此基础上利用SIMD指令提升过滤效率。
- 深浅翻页均采用该内存算法,不需要判断深浅翻页的界线。
- 内存不足时,采用如下的磁盘算法:
- 采用归并排序时基于offset和limit做truncate的方案。
- 并在此基础上利用ZoneMap在归并排序的前期阶段做pruning,尽可能地减少对非结果集数据的操作。
- 动态选择内存磁盘算法:不依赖固定的阈值来选择使用内存算法或磁盘算法,而是在执行过程中根据可用执行内存的大小,动态调整所用算法。
由于Self-sharpening Input Filter和归并排序时基于offset和limit做truncate的方案在前文中已经介绍,因此接下来仅介绍选择这两种方案的原因,并介绍利用SIMD指令提升过滤效率、利用ZoneMap做pruning以及动态选择内存磁盘算法的部分。
SIMD Accelerated Self-sharpening Input Filter
在内存充足时,直接采用Self-sharpening Input Filter的设计,主要基于两个原因:
- Self-sharpening Input Filter不管是使用cutoff value进行过滤,还是pre-merge,访问内存的模式都是顺序的,可以避免Priority Queue访存效率的问题。
- 该设计无论翻页深浅都具有优异的性能,在应用时不需要考虑深浅翻页的界线。
实际上,Self-sharpening Input Filter在某种程度上和基于Priority Queue的算法是类似的,cutoff value类似堆顶,都用于过滤后续读取的数据,两者的不同之处在于,基于Priority Queue的算法会实时更新堆顶,而Self-sharpening Input Filter则将数据积累在sorted run中,以batch的方式更新cutoff value。
使用cutoff value进行过滤是Self-sharpening Input Filter中很重要的过程,涉及数据比较,操作简单重复但非常频繁,因此使用SIMD指令来加速这一过程。由于cutoff value过滤和TableScan中使用Predicate过滤是类似的,因此在具体实现中直接复用处理Predicate的表达式,提升过滤的效率,减少计算TopK的时间。
Zonemap-based Pruning
在内存不足时,采用归并排序,并基于offset和limit做truncate,主要原因如下:
- 如果在内存不足时继续使用Self-sharpening Input Filter的设计,就需要将积累的sorted run落盘,并且在pre-merge时同样使用外排序算法,产生大量的读写磁盘的操作,相对于内存充足场景下的Self-sharpening Input Filter有额外的开销。当K非常大时,pre-merge时的外排序可能还会涉及大量非结果集数据,因为最终只需要获取排在第[offset, offset + limit)位的记录,而不关心排在第[0, offset)位的记录。
- 在这种场景下,可以使用归并排序,在生成sorted run的阶段仅将sorted run落盘,然后使用统计信息进行pruning,避免不必要的读写磁盘的操作,也可以尽可能地避免对非结果集数据的操作。
以下图为例来说明使用统计信息进行pruning的原理。下图中,箭头表示数轴,代表sorted run的矩形的左右两端在数轴上对应的位置表示sorted run的min/max值,Barrier表示pruning所依赖的一个阈值。
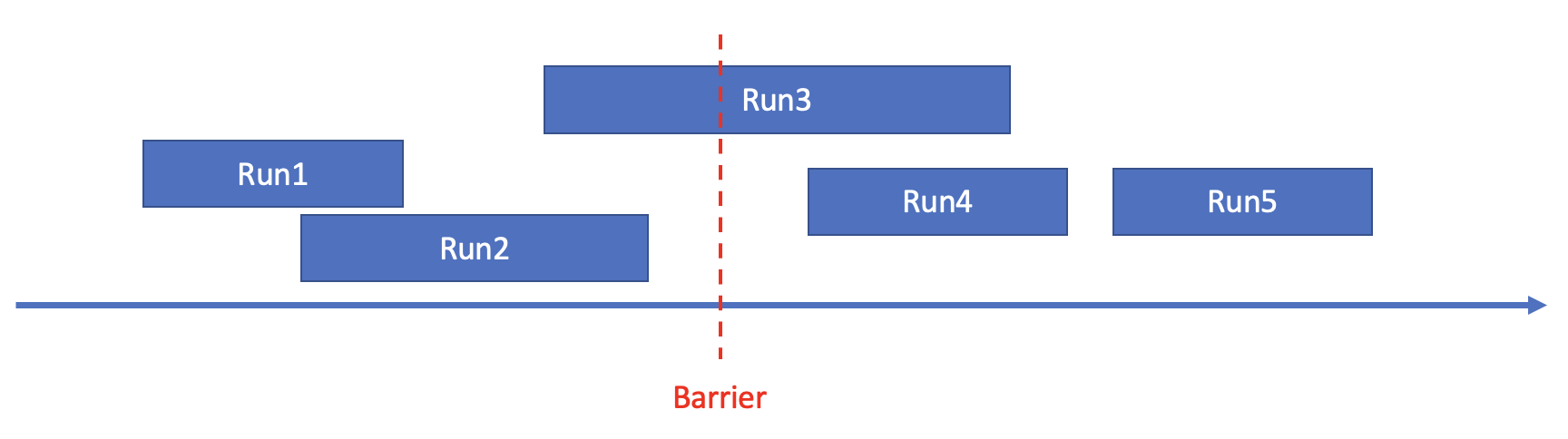
- 任意一个Barrier可以将所有sorted run分为三类:
- 类型A:min value of sorted run<Barrier&&max value of sorted run<Barrier,如上图中Run1,Run2。
- 类型B:min value of sorted run<Barrier&&max value of sorted run>Barrier,如上图中Run3。
- 类型C:min value of sorted run>Barrier&&max value of sorted run>Barrier,如上图中Run4,Run5。
- 对于任意一个Barrier,如果类型A和类型B中的数据量<TopK查询中的offset,那么类型A中的数据必然排在第[0, offset)位,类型A中的sorted run可以不参与后续的merge。
- 对于任意一个Barrier,如果类型A中的数据量>TopK查询中的offset+limit,那么类型C中的数据必然排在第[offset+limit, N)位,类型C中的sorted run可以不参与后续的merge。
根据上述原理,使用统计信息进行pruning的具体流程如下:
- 构建包含sorted run的min/max信息的Zonemap。
- 基于Zonemap寻找一个尽可能大的Barrier1满足类型A和类型B中的数据量<TopK查询中的offset。
- 基于Zonemap寻找一个尽可能小的Barrier2满足类型A中的数据量>TopK查询中的offset+limit。
- 使用Barrier1和Barrier2对相关sorted run进行pruning。
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
