4.6 向量化执行
OceanBase 在第三代执行引擎中引入了向量化执行。主要是因为 OceanBase 的用户场景除了 OLTP(联机事务处理)类的简单查询,还会有一些像报表分析、业务角色等 OLAP(联机分析处理)查询。而这些 OLAP 查询都具备数据处理量较大并且耗时高的特点。
传统按行迭代的模型,每行都需要进行一次迭代。这样会导致虚函数调用开销较大。传统火山模型的实现,一般不同的算子都会有一个公共基础类。之后每一个算子的实现都是该公共基础类的一个派生类,框架会通过算子调用不断地进行迭代。这种情况下,如果需要迭代的次数非常多,实际上的开销是非常大的。同时因为数据是一行一行处理,每个算子都会处理一行数据,计算之后又传输给下一个算子。整个过程对于 CPU 的数据 cache 以及指令 cache 都不是特别友好。
实现向量化之后,数据都是按 batch 进行迭代。这样就较大程度上减少了迭代的次数,整体来说,算子调用的开支也会降低很多。
整个向量化的实现,其实还是使用类似于传统迭代模型进行迭代,但是传统迭代模型是一行数据进行迭代,向量化实现是一个数据 batch 进行迭代。在这个迭代过程中,算子与算子之间、算子内部的实现以及计算都是按 batch 进行,整体来说对 CPU 的 cache 会更友好,数据的局部性也会更好。
除此之外,因为向量化实现是对一个 batch 数据进行计算,所以在很多场景都可以使用到 SIMD。对于多个数据,通过 SIMD 的一条指令就可以直接计算出结果,极大地提升了执行性能。
对于向量化执行,数据描述还是以列的形式按批组织的,而整个实现也还是沿用了之前预分配内存的实现方式,整个的动态内存都在 DATA_FRAME 内存中,举例说明:
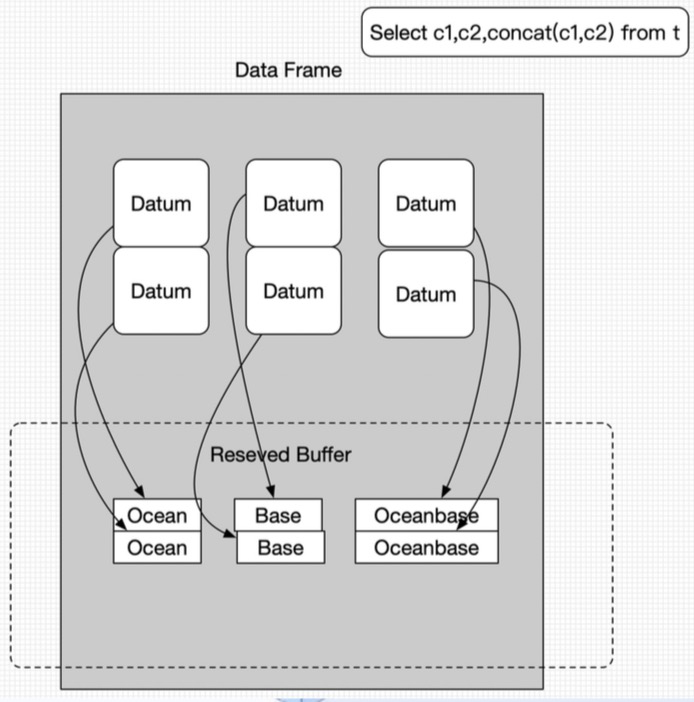
如上图中 c1 这个表达式,假设 batch 是 256 行,这 256 行数据就是连续存放的一列数据。同样的,c2 和 concat(c1, c2) 的数据也是连续存放的,这样可以更好地去使用 SIMD。同时因为内存都是预分配,可以反复使用,不需要在执行过程中重复分配内存和释放内存的操作。
向量化实现
向量化的实现主要涉及以下几个方面的改造:
算子向量化
表达式向量化
存储层向量化
对于算子的实现,以前执行引擎是按单行迭代的方式去实现算子,现在则是按 batch 进行迭代,算子实现的方式会发生比较大的改变。这种按 batch 迭代的方式在算子里面进行数据处理时也是按 batch 去处理。这样就能比较多的用到一些硬件的特性(如内存预取)。
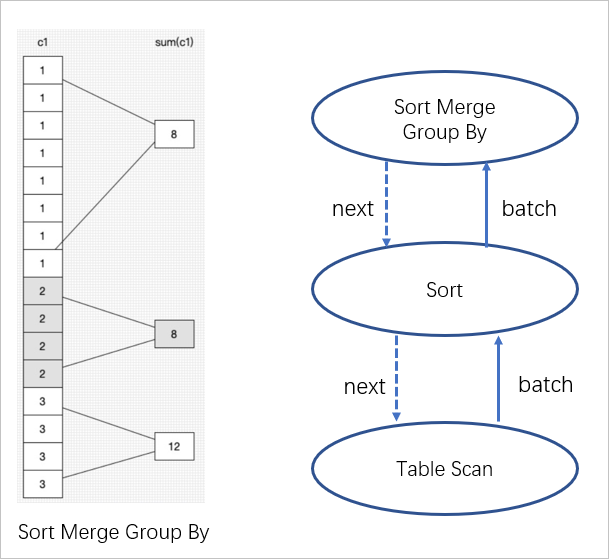
这里看一个例子
select sum(c1) from t1 group by c1
该 SQL 作用是获取 t1 的数据,之后按 c1 列进行分组,最后对 c1 列进行求和。从下图中可以看到 Merge group by 算子会从 Sort 获取一批已经排序过的数据。若是按以前单行迭代的执行方式,数据会一行一行迭代,每迭代一行会做一次 sum 求和。在向量化实现里面,获取到的是一批相同的数据,求和的时候可以直接使用 SIMD 依次对这一批数据进行求和,这样的执行性能可以得到较大提高。
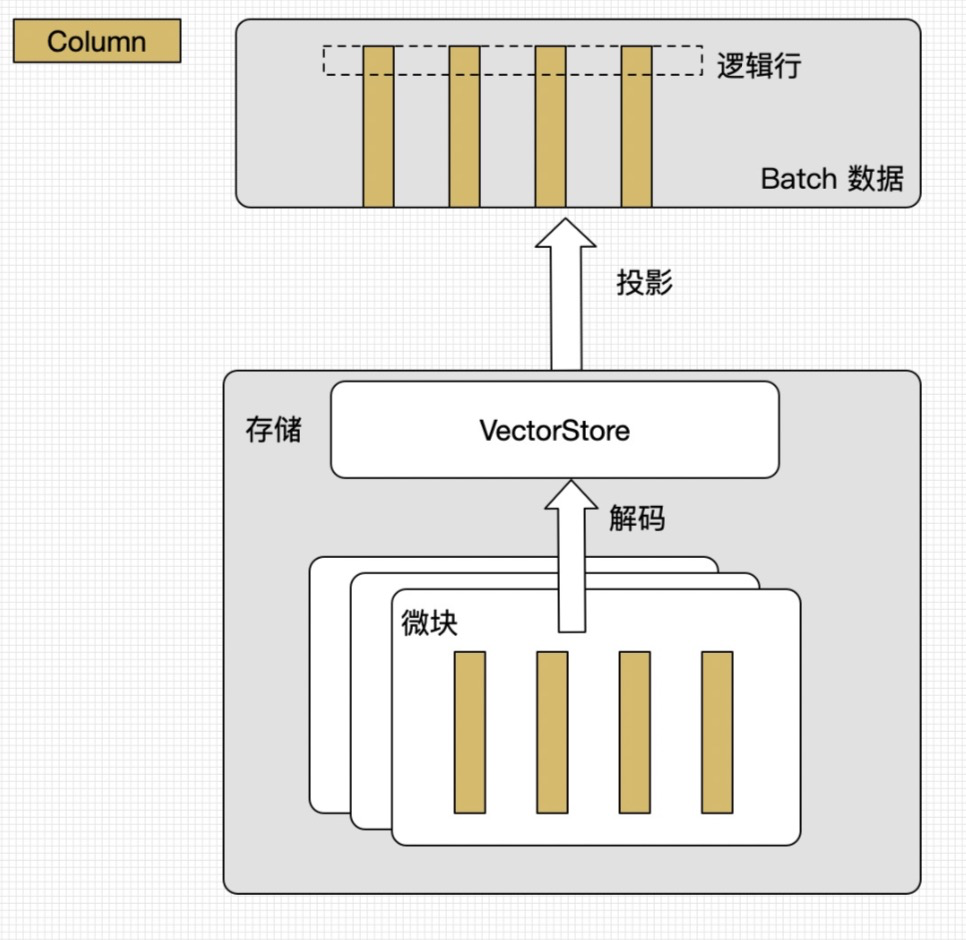
OceanBase 存储层采用的是行列混存架构。因为微块里面的数据都是按列存放,存储的数据投影到 SQL 层时,可以直接把这块连续的数据按 batch 投影到 SQL 层的内存里,这样对向量化的处理会更好,整体来说从存储层到 SQL 层整个迭代过程的开销可以大大减少。同时 OceanBase 也实现了 filter 下压到存储层的能力,filter 下压到存储层之后,过滤也是通过向量化来进行计算的。这样的话,存储层的数据在投影到 SQL 层之前就可以过滤掉,可以大大减少投影的开销以及迭代的开销。
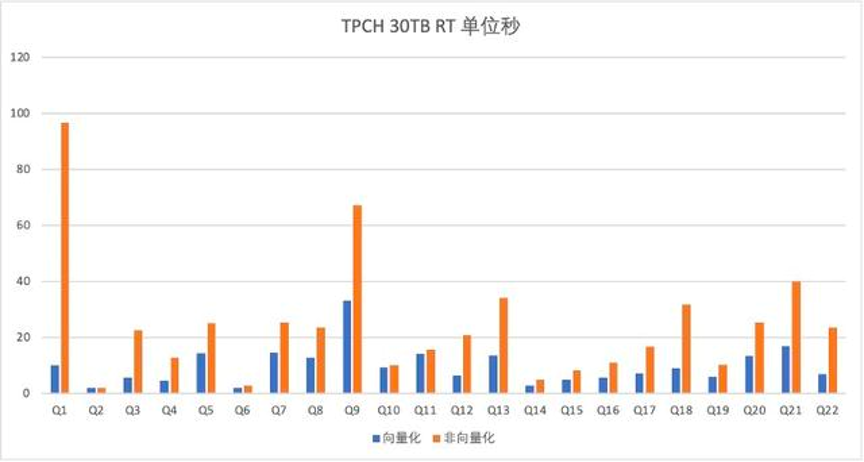
下图是完成向量化以后,OceanBase 在标准的 TPCH 30TB 测试中的测试结果。其中,橙色的是非向量化的部分,蓝色的是向量化部分,纵轴表示的是 RT。可以看到,向量化实现基本上都会有一个比较大的提升,整体性能提升了 2.48 倍。