




点击蓝字 关注我们

在 UI 界面上直接通过拖放任务的方式来创建任务 PyDolphinScheduler,通过 Python API 创建工作流,也就是 workflow as code 的方式 编写 yaml 文件,通过 yaml 创建工作流(目前必须安装 PyDolphinScheduler) 通过 Open API 的方式来创建工作流
01
什么是 SPI 服务发现?
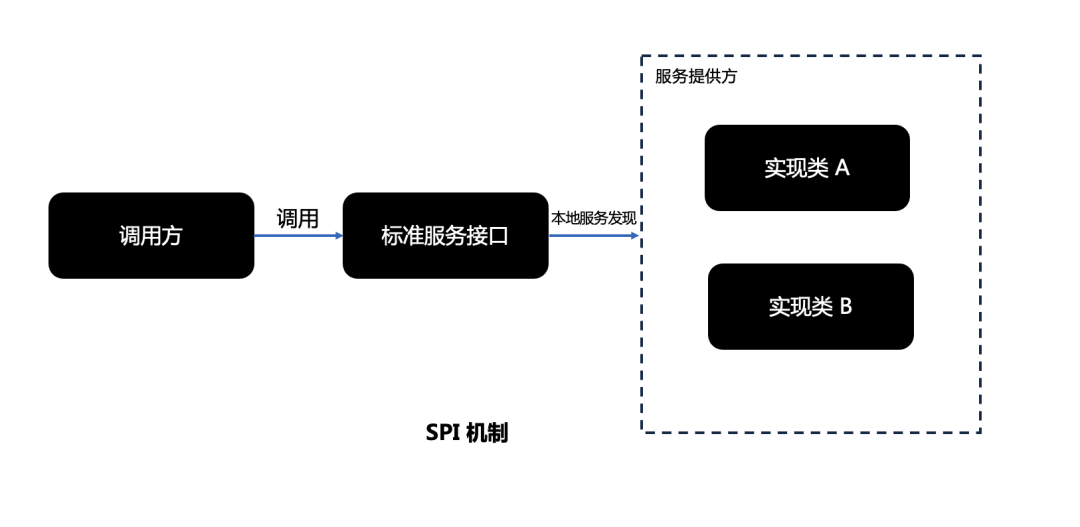
服务接口 Service Interface 服务接口实现:不同的服务提供方可以提供一个或多个实现;框架或者系统本身也可以提供默认的实现 提供者注册 API(Provider Registration API),这是提供者用来注册实现的 服务访问 API (Service Access API) ,这是调用方用来获取服务的实例的接口
02
谁在使用它?
Task Datasource
Flink sql connector,用户实现了一个 Flink-connector 后,Flink 也是通过 SPI 来动态加载的
Spring boot spi
JDBC4 也基于 SPI 的机制来发现驱动提供商了,可以通过META-INF/services/java.sql.Driver 文件里指定实现类的方式来暴露驱动提供者
common-logging
03
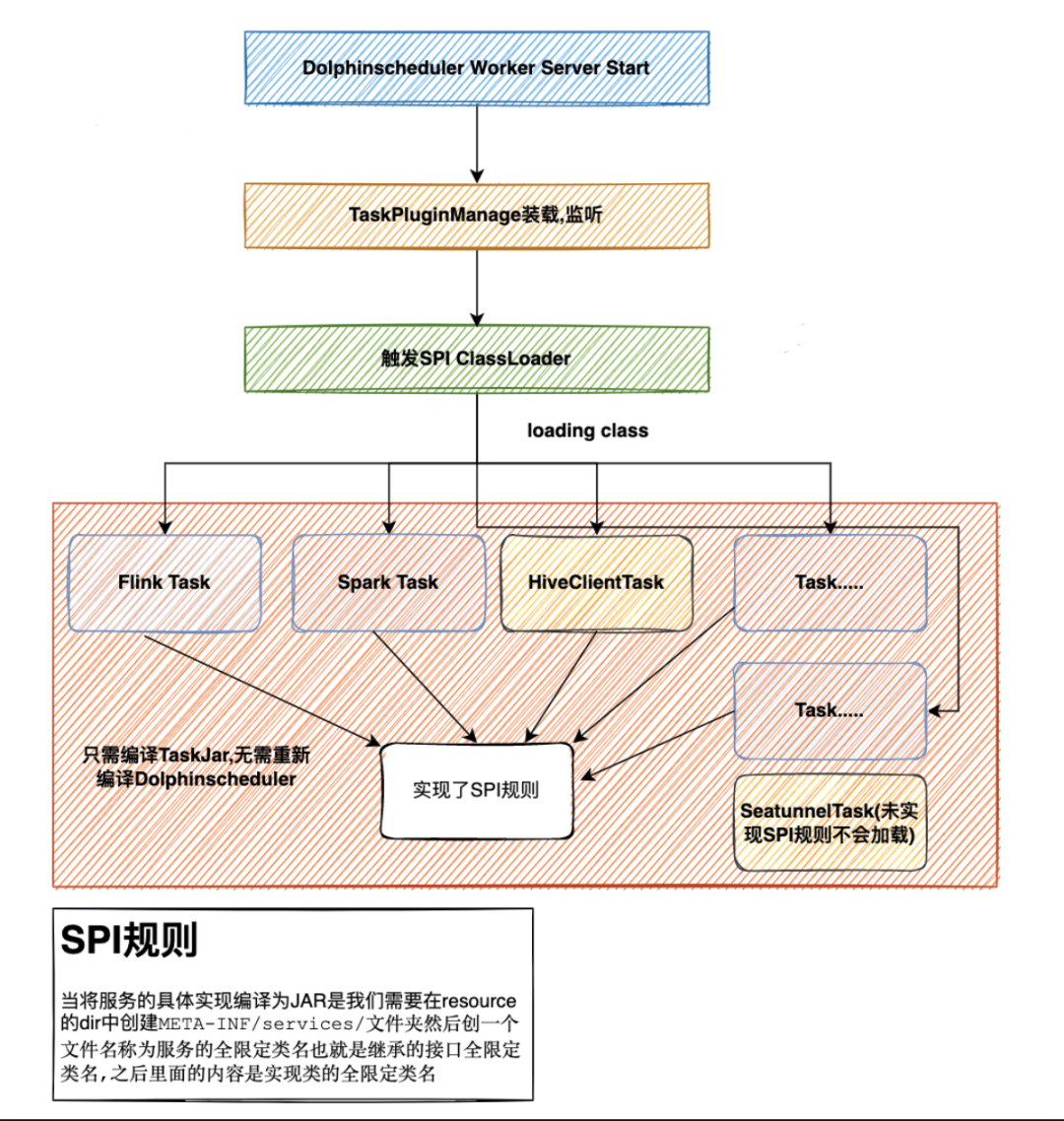
DolphinScheduler SPI工作流程
04
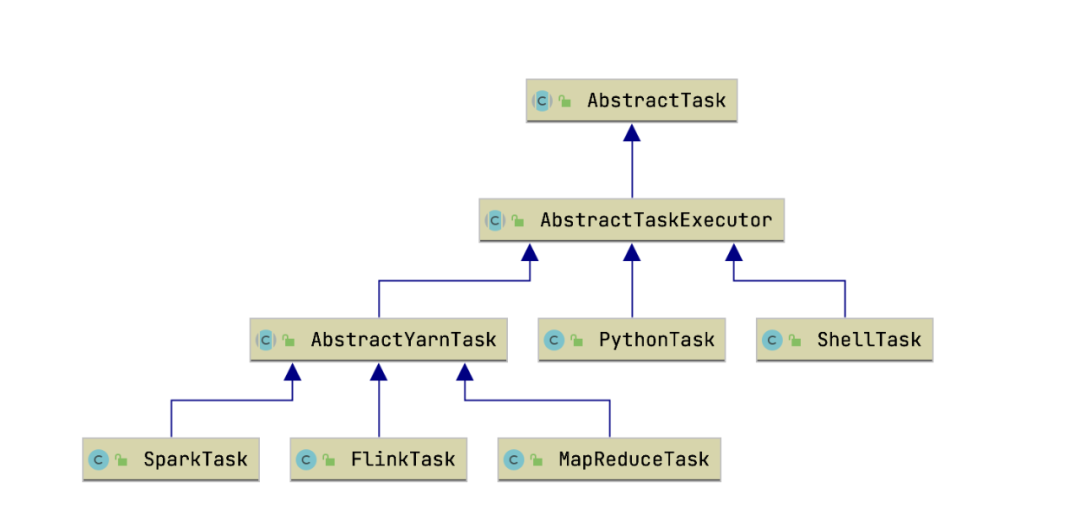
如何扩展一个任务插件?
mvn archetype:generate \-DarchetypeGroupId=org.apache.dolphinscheduler \-DarchetypeArtifactId=dolphinscheduler-hive-client-task \-DarchetypeVersion=1.10.0 \-DgroupId=org.apache.dolphinscheduler \-DartifactId=dolphinscheduler-hive-client-task \-Dversion=0.1 \-Dpackage=org.apache.dolphinscheduler \-DinteractiveMode=false
org.apache.dolphinschedulerdolphinscheduler-spi${dolphinscheduler.lib.version}${common.lib.scope}org.apache.dolphinschedulerdolphinscheduler-task-api${dolphinscheduler.lib.version}${common.lib.scope}
package org.apache.dolphinscheduler.plugin.task.hive;import org.apache.dolphinscheduler.spi.params.base.PluginParams;import org.apache.dolphinscheduler.spi.task.TaskChannel;import org.apache.dolphinscheduler.spi.task.TaskChannelFactory;import java.util.List;public class HiveClientTaskChannelFactory implements TaskChannelFactory {/*** Create task channel, execute task through this channel* @return task channel*/@Overridepublic TaskChannel create() {return new HiveCliTaskChannel();}/*** Returns the global unique identifier of this task* @return task name*/@Overridepublic String getName() {return "HIVECLI";}/*** Parameters required for front-end pages* @return*/@Overridepublic List getParams() {return null;}}
void cancelApplication(boolean status);/*** 构建可执行任务*/AbstractTask createTask(TaskRequest taskRequest);public class HiveClientTaskChannel implements TaskChannel {@Overridepublic void cancelApplication(boolean b) {//do nothing}@Overridepublic AbstractTask createTask(TaskRequest taskRequest) {return new HiveClientTask(taskRequest);}}
package com.jegger.dolphinscheduler.plugin.task.hive;import org.apache.dolphinscheduler.spi.task.AbstractParameters;import org.apache.dolphinscheduler.spi.task.ResourceInfo;import java.util.List;public class HiveClientParameters extends AbstractParameters {/*** 用HiveClient执行,最简单的方式就是将所有SQL全部贴进去即可,所以我们只需要一个SQL参数*/private String sql;public String getSql() {return sql;}public void setSql(String sql) {this.sql = sql;}@Overridepublic boolean checkParameters() {return sql != null;}@Overridepublic List getResourceFilesList() {return null;}}
package org.apache.dolphinscheduler.plugin.task.hive;import org.apache.dolphinscheduler.plugin.task.api.AbstractYarnTask;import org.apache.dolphinscheduler.spi.task.AbstractParameters;import org.apache.dolphinscheduler.spi.task.request.TaskRequest;import org.apache.dolphinscheduler.spi.utils.JSONUtils;import java.io.BufferedWriter;import java.io.IOException;import java.nio.charset.StandardCharsets;import java.nio.file.Files;import java.nio.file.Path;import java.nio.file.Paths;public class HiveClientTask extends AbstractYarnTask {/*** hive client parameters*/private HiveClientParameters hiveClientParameters;/*** taskExecutionContext*/private final TaskRequest taskExecutionContext;public HiveClientTask(TaskRequest taskRequest) {super(taskRequest);this.taskExecutionContext = taskRequest;}/*** task init method*/@Overridepublic void init() {logger.info("hive client task param is {}", JSONUtils.toJsonString(taskExecutionContext));this.hiveClientParameters = JSONUtils.parseObject(taskExecutionContext.getTaskParams(), HiveClientParameters.class);if (this.hiveClientParameters != null && !hiveClientParameters.checkParameters()) {throw new RuntimeException("hive client task params is not valid");}}/*** build task execution command** @return task execution command or null*/@Overrideprotected String buildCommand() {String filePath = getFilePath();if (writeExecutionContentToFile(filePath)) {return "hive -f " + filePath;}return null;}/*** get hive sql write path** @return file write path*/private String getFilePath() {return String.format("%s/hive-%s-%s.sql", this.taskExecutionContext.getExecutePath(), this.taskExecutionContext.getTaskName(), this.taskExecutionContext.getTaskInstanceId());}@Overrideprotected void setMainJarName() {//do nothing}/*** write hive sql to filepath** @param filePath file path* @return write success?*/private boolean writeExecutionContentToFile(String filePath) {Path path = Paths.get(filePath);try (BufferedWriter writer = Files.newBufferedWriter(path, StandardCharsets.UTF_8)) {writer.write(this.hiveClientParameters.getSql());logger.info("file:" + filePath + "write success.");return true;} catch (IOException e) {logger.error("file:" + filePath + "write failed.please path auth.");e.printStackTrace();return false;}}@Overridepublic AbstractParameters getParameters() {return this.hiveClientParameters;}}
# 1,Resource下创建META-INF/services文件夹,创建接口全类名相同的文件zhang@xiaozhang resources % tree ././└── META-INF└── services└── org.apache.dolphinscheduler.spi.task.TaskChannelFactory# 2,在文件中写入实现类的全限定类名zhang@xiaozhang resources % more META-INF/services/org.apache.dolphinscheduler.spi.task.TaskChannelFactoryorg.apache.dolphinscheduler.plugin.task.hive.HiveClientTaskChannelFactory
## 1,打包mvn clean install## 2,部署cp ./target/dolphinscheduler-task-hiveclient-1.0.jar $DOLPHINSCHEDULER_HOME/lib/## 3,restart dolphinscheduler server
NOTICE:目前任务插件的前端还没有实现,因此你需要单独实现插件对应的前端页面。
参考: https://blog.csdn.net/s1293678392/article/details/120048318
参与贡献
随着国内开源的迅猛崛起,Apache DolphinScheduler 社区迎来蓬勃发展,为了做更好用、易用的调度,真诚欢迎热爱开源的伙伴加入到开源社区中来,为中国开源崛起献上一份自己的力量,让本土开源走向全球。

参与 DolphinScheduler 社区有非常多的参与贡献的方式,包括:

贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度。
社区汇总了以下适合新手的问题列表:https://github.com/apache/dolphinscheduler/issues/5689
非新手问题列表:https://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A%22volunteer+wanted%22
如何参与贡献链接:https://dolphinscheduler.apache.org/zh-cn/community/development/contribute.html
来吧,DolphinScheduler开源社区需要您的参与,为中国开源崛起添砖加瓦吧,哪怕只是小小的一块瓦,汇聚起来的力量也是巨大的。
参与开源可以近距离与各路高手切磋,迅速提升自己的技能,如果您想参与贡献,我们有个贡献者种子孵化群,可以添加社区小助手微信(Leonard-ds) ,手把手教会您( 贡献者不分水平高低,有问必答,关键是有一颗愿意贡献的心 )。

添加社区小助手微信(Leonard-ds,好友申请注明“入交流群+姓名+公司+职位信+是否是用户”,群里是实名制,仅用于验证身份)
如果想参与贡献,添加小助手微信时请说明想参与贡献。
来吧,开源社区非常期待您的参与。
☞Apache DolphinScheduler 支持使用 OceanBase 作为元数据库啦!

