




7.2 OceanBase 质量体系和测试工具
本节主要介绍 OceanBase 的质量体系以及常用的测试工具,OceanBase 的测试分为功能测试、正确性测试、性能测试、稳定性测试、兼容性测试,其中每个阶段都有其代表性的测试工具,接下来将按照上述测试类型介绍 OceanBase 如何做测试。
SQL 功能测试
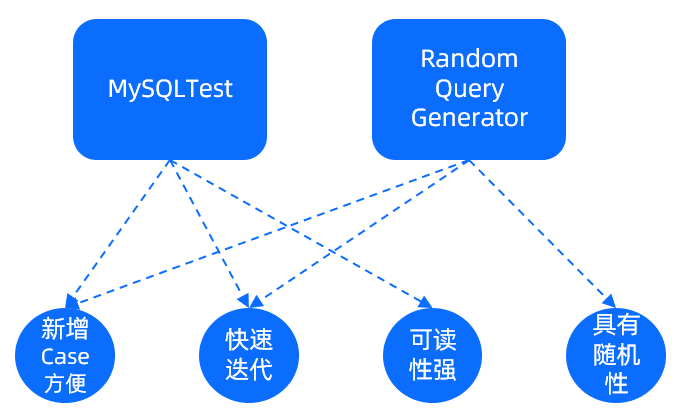
SQL 功能测试框架需要具备的特点:
新增 case 方便
SQL 模块经常会有新功能加入,新增场景的成本要足够低,框架应该具备只提供能力,场景可以自如添加的特性。
快速迭代
SQL 功能模块耦合重,经常牵一发而动全身,快速迭代能在第一时间发现问题。
可读性强
SQL 模块的 case 经常是多人维护,较高的可读性可以降低维护成本。
具有随机性
SQL 功能繁多,使用形式多样,具有一定的随机性可以弥补人工设计场景容易覆盖不全的弊端。
当前 OceanBase 用于 SQL 测试的工具有 MysqlTest 和 RQG,这两个工具几乎兼具上面介绍的四个特点。
MysqlTest 工具
MysqlTest 框架特点如下:
新增 case 快
快速迭代
可读性强
MysqlTest 是基于 MySQL 开源测试框架 MTR(MySQL Test Run)的二次开发,其核心思想是将 case 的执行结果和预期结果做对比,若不一致,则认为 case 执行失败。
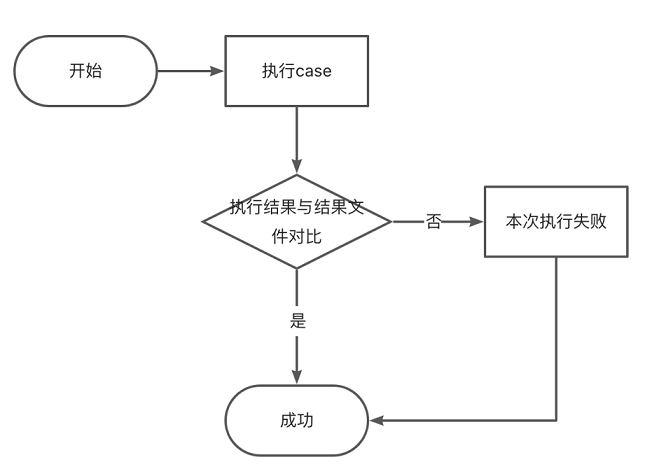
MysqlTest 的 case 由以下三部分组成。
SQL:是测试的主体,以英文分号(
;)结束。Command:用来控制运行时的行为。
Comment:注释,以井字符号(
#)开头。
SQL 是测试的主题,command 是 MysqlTest 工具的精髓,如下所示列举了些常用的 command,可以看到这些 command 的实现都是为了让 case 更好地执行。比如 error 命令,可以更好地验证异常场景;disable_query_log 和 disable_result_log 命令可以更好地做结果对比。
error:验证预期失败;可以加多个错误码作为参数,使用逗号分隔即可。
disable_abort_on_error/--enable_abort_on_error:SQL 执行失败后不退出。
disable_query_log/--enable_query_log:不将执行语句写到 result 文件。
disable_result_log/--enable_result_log:不将执行结果写到 result 文件。
disable_parsing/--enable_parsing:用来多行注释,--disable_parsing 之后的语句将不会被执行。
connect/disconnect:建立连接和断开连接的命令。
system/exec:执行 shell 命令。
perl [terminator]:嵌入 perl code,直到 terminator 位置。
exit:退出,其后的内容不会执行。
let$var_name = value:变量赋值,整数、字符串都可以。
inc$varname/dec $varname:整数加1/减1,是 MysqlTest 唯一支持的运算。
eval:执行 SQL 语句,支持变量的传递,比如:eval insert into t1(i,c1,c256) values(0,'1','$i');
send/reap:发送 query 后不用等待结果立即返回,在 reap 的时候接受结果,多用于事务并发测试。
echo:打印,常用于在结果文件中加注释。
query_get_value(query, colname, rownum):获得 query 返回的结果中某行某列的值。
source:多个 case 可能共用一块代码,这块代码可以单独放到一个文件,通过 source 导入。
sleep/real_sleep:sleep 时间。
replace_column:对查询结果的某些列的值进行替换,对于随着执行时间变化的,比如 createtime 或 modifytime 类型,为了比较可以用这个命令将这个值替换成某常量,如:--replace_column 2 searched;
也可以一次匹配多个类型,如 --replace_column 1 create_time 2 modify_time 3 tenant_id 6 zone 8 zone 7 zone。
replace_regex:使用正则表达式进行匹配。
--replace_regex /REPLICA_NUM =[0-9]*/REPLICA_NUM = 1/g
if/while 循环&控制命令。
MysqlTest 中的每个 command 都很实用,在 OceanBase 的 case 中也被大量使用,感兴趣的同学可以去 MTR 官网 查看各个 command 的详情和使用示例。
Case 的位置
OceanBase MysqlTest 的 case 放在源码的 tools/deploy 目录下。
include:放一些通用的判断逻辑,常用的 SQL 和场景,source 的文件通常放在此处。
test_suite:按照大功能点存放 case 的位置。
t 目录:放 case,文件名以
.test结尾。r/mysql 目录:放预期结果文件,文件名以
.result结尾。
Case 编写注意事项
MysqlTest case 编写有很多注意事项,总体原则是可重复执行,每次运行结果固定。一般要求在不重启数据库的情况下,能够多次连续执行成功且不能影响到后面执行的 case,才算一个合格的 case。
如下所示列举了 case 编写的一些注意事项,这些注意事项都是根据原则来制定的。
建表之前,或者在 case 的最前面,使用 droptable if exists tbl_name。
case 中对于配置项的修改,尤其是 global 的配置项,为了不影响后面 case 的运行,最后在 case 的末尾恢复到默认值。
对于结果文件依赖于执行顺序的,或随着时间会变化结果的值,可用 --replace_column 代替或者 --replace_regex 替换,以保证每次运行的结果文件是一样的。
Case 如何执行
MysqlTest 通过 OBD 来运行,如下示例中列举了用 OBD 跑 case 的常用命令,具体参数说明以及 case 如何执行,请参见 obd test mysqltest 文档。
obd test mysqltest <deploy name> [--test-set <test-set>] [flags]
跑指定位置的单个用例
obd test mysqltest <deploy name> --test-dir ./mysql_test/ test_suite/alter/t --result-dir ./mysql_test/test_suite/ alter/r --test-set alter_log_archive_option --auto-retry跑特定 suite 下的全部用例
obd test mysqltest <deploy name> --suite <suite_name> --auto-retry跑所有的用例
obd test mysqltest <deploy name> --all --auto-retry
MysqlTest 的优点是添加 case 方便,场景非常确定,便于场景积累和快速迭代。它的缺点是随机性不足,想要不漏测,对设计 case 人员的要求非常高。因此引入了 RQG 工具来弥补 MysqlTest 的这点不足。
RQG 工具
RQG(Random Query Generator):MySQL 开发的随机 SQL 生成测试框架,基于 Perl 实现。
核心思想:
通过数据文件(.zz 文件)自动生成关系表并灌入数据。
通过语法文件(.yy 文件)随机生成 SQL 语句(DDL,DML)并执行。
RQG 支持将同一条 SQL 发往不同的数据库 Server 执行,并对比执行的结果。
若执行的结果不一致,RQG 会打印对应的 SQL 以及不一致的直接结果。
下图为 RQG 的框架图,从图中可以看到 RQG 有专门的模块来处理数据文件和语法文件,以及控制 SQL 执行并生成报告。
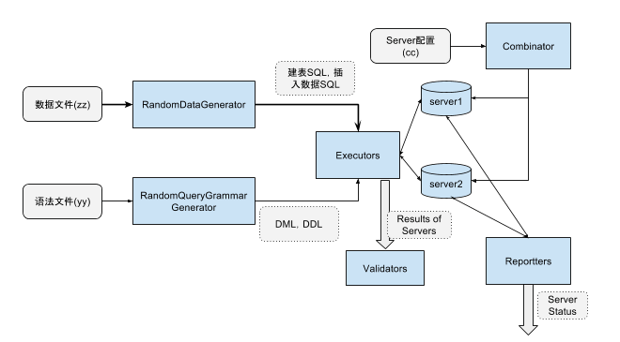
图中各模块解释如下。
RandomDataGenerator:根据用户指定的数据文件(.zz 文件)自动生成随机关系表并注入数据。
RandomQueryGrammarGenerator:根据用户指定的语法文件(.yy 文件)随机自动生成 SQL 语句(DML、DDL)。
Executors:将 SQL 语句发往数据库 Server 执行,并返回执行结果,即和数据库交互的组件。
Validators:对 SQL 的执行结果进行校验,例如对比不同数据库的执行结果。
Combinator:随机组合用户指定的配置项配置一个数据库 Server,已进行测试。
Reporters:监控数据库 Server 的状态,如果 Server 出现错误就会以日志的形式记录下来。
为便于大家理解,接下来介绍一个示例。
数据定义文件 xx.zz 示例中定义了表的数据量,主键类型,分区方式,字段类型的范围等,RQG 通过数据定义文件随机生成表结构并插入数据。
# 数据定义文件 xx.zz 示例
$tables = {
rows => [1, 10 ],
pk => [ 'smallint' ],
names => [ 'A', 'B', 'C' ],
partitions => [undef, 'KEY (pk) PARTITIONS 2']
};
$fields = {
types => [ 'int', 'char(20)' ],
indexes => [ undef ]
null => [ 'not null', undef ]
};
$data = {
numbers => [ 'digit', 'int', 'int'],
strings => ['char(20)', 'english' ]
};
# zz 文件的运行命令
生成关系表和灌入数据:
perl gendata.pl
--dsn=dbi:mysql:host=xxx:port=xxx:user=xxx:
password=xxx:database=xxx
--spec=example.zz
接下来介绍一个简单的语法文件示例。如下所示,从上往下是迭代关系,第一行定义 query 的形式,若遇到 update,就用 update 的定义来替换,table 会替换成数据库中已有的表,字段会用表中的字段名替换。以此类推,每一部分都具有一定的随机性。
# 语法文件 yy 定义
query:
update | update | insert | delete ;
update:
UPDATE _table SET _field = digit WHERE condition LIMIT _digit ;
delete:
DELETE FROM _table WHERE condition LIMIT _digit ;
insert:
INSERT INTO _table ( _field ) VALUES ( _digit ) ;
condition:
_field < digit | _field = _digit ;
# yy 文件的运行命令
生成随机 SQL 并执行:
perl gensql.pl
-–grammar=grammar_file \
--seed=25300 \
--dsn=dbi:mysql:host=xxx:port=xxx:
user=xxx:password=xxx:
database=test
说明
seed 参数表示随机种子,可以指定数字,也可以用 time 字符串,表示用当前的时间表示随机种子。
综上所述,MysqlTest 和 RQG 在 OceanBase 的 SQL 测试中发挥了巨大的作用。
正确性测试
数据正确性是数据库的质量底线,常见的数据正确性问题有以下几个方面:
写入数据不正确
查询结果不正确
多副本之间的数据不一致
数据表和索引表中的数据不一致
对于这些常见的正确性问题,常用的校验方法如下:
与预期结果做对比:MysqlTest
与其他数据库做对比:Random Query Generator
数据库加内部校验:OceanBase checksum 自校验
这三种常用的校验方法都有各自的局限性,其中:
与预期结果对比的方法依赖于 case 设计,很难保证全面覆盖。
与其他数据库对比的方式需要两个数据库语法完全一致,语法不兼容的场景很难被覆盖。
内部校验只校验副本间的 checksum,只能覆盖一部分场景。
2020 年 Manuel Rigger 提出了新的验证 SQL 逻辑错误的正确性的方法,并发表了 3 篇论文,在此基础上实现 SQLancer 工具,3 篇论文如下所示:
PQS 算法:Testing Database Engines via Pivoted Query Synthesis, USENIX, 2020
TLP 算法:Ternary Logic Partitioning: Detecting Logic Bugs in Database Management Systems, PACMPL, 2020
接下来分别介绍一下这三个 SQL 逻辑错误校验方法的思想。
PQS 算法
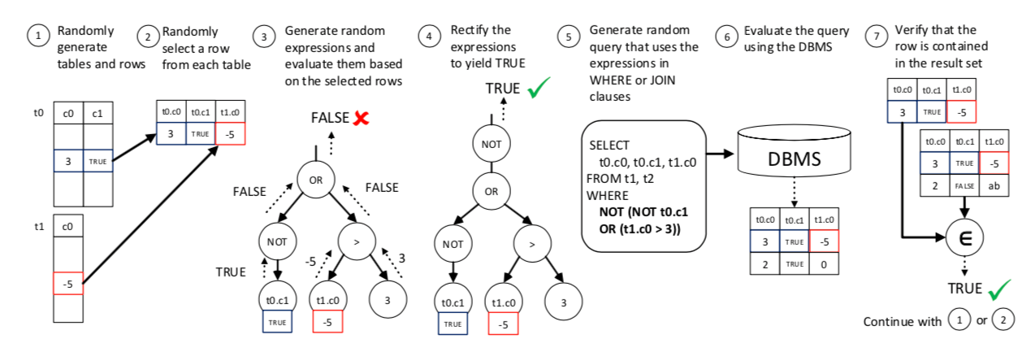
核心思想:
随机生成 table 和插入数据
从数据库中随机选择一行数据
根据这行数据,随机构造一个 expression
执行 expression,如果不为 TRUE,则调整为 TRUE
将这个 expression 放到 where 或者 join 里面
执行这条查询语句看最新的返回结果是不是还包含之前的那行数据,如果没有,则表明有 bug
该算法的核心就是选取一行数据,构造查询结果,通过不断变化查询结果并保持表达式恒 TRUE,即总能查到那条数据。在反复的变化中,如果返回结果不包含之前选取的那行数据,就说明有 bug。
NoREC 算法
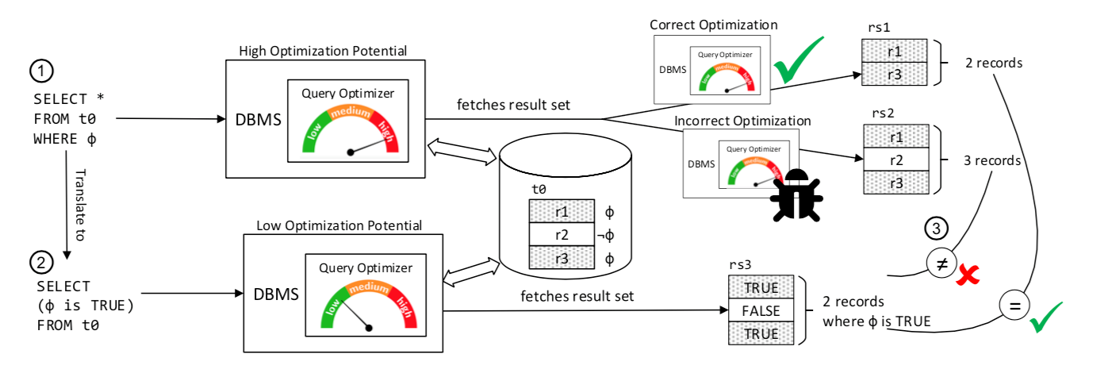
核心思想:将数据库优化器优化后版本的执行结果与没有执行任何优化的相同 DBMS 版本的结果进行比较;第一个查询获取的记录数量必须等于第二个查询的 WHERE 谓词计算为 TRUE 的次数。
通俗来说就是通过数据库的查询改写或其他方式对 SQL 进行等价转换后进行查询,如果等价的两个 SQL 返回的结果不同,则说明有 bug。
示例:
create table norec (c0 int); insert into norec values (1),(2); select * from norec where c0 > 1; select count(*) from (select ((c0 > 1)) is true as count from norec) where count = 1;TLP 算法
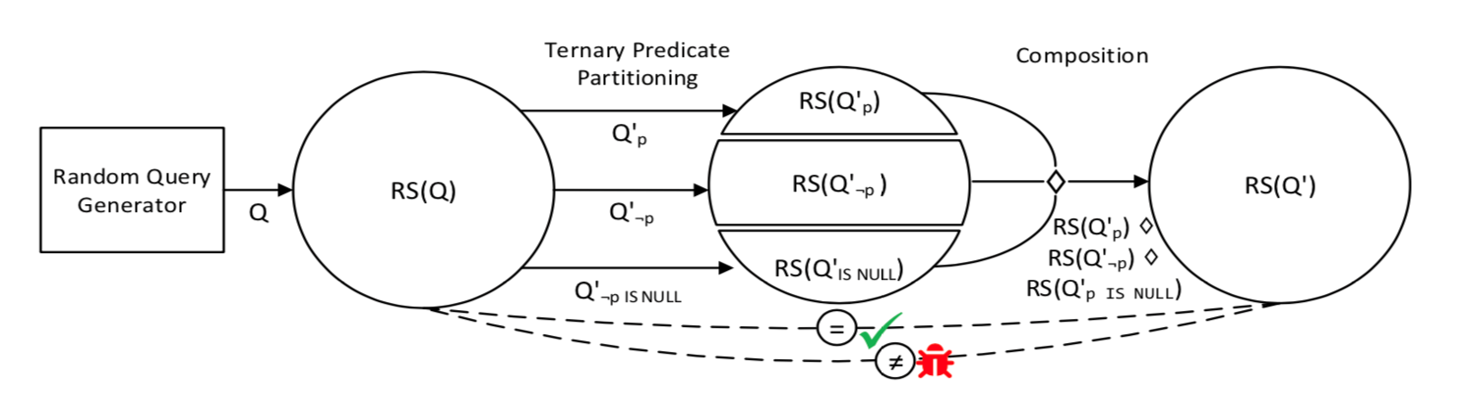
核心思想:将 SQL 拆分为恒 TRUE、FALSE、NULL 的三条 SQL,再合并查询结果,并与原始的查询结果进行比较,如果两次查询的结果不一致,则说明有 bug。
示例:
CREATE TABLE t0(c0 INT); CREATE TABLE t1(c0 DOUBLE); INSERT INTO t0 VALUES(0); INSERT INTO t1 VALUES('−0'); SELECT * FROM t0, t1; SELECT * FROM t0, t1 WHERE t0.c0 = t1.c0 UNION ALL SELECT * FROM t0, t1 WHERE NOT(t0.c0 = t1.c0) UNION ALL SELECT * FROM t0,t1 WHERE (t0.c0 = t1.c0) IS NULL
综上所述,SQLancer 三个算法的设计思想十分精巧,通过各种转换,能够将简单的 SQL 变成人工无法设计的逻辑复杂的 SQL,并能根据一定的规则对这些 SQL 进行判断。SQLancer 的引入对 OceanBase 正确性的测试有了一个非常好的补充。
性能测试
性能测试框架的要求:
可自动化回归
准入基线
多指标判断性能不下降
添加场景成本低
一定的权威性和广泛的认可度
场景经典
基于以上要求,筛选出 Sysbench、TPCC、TPCH 这 3 种经典的性能测试工具。OceanBase 性能测试会有不同的影响因素,如 Memory、CPU、IO、Network 等。针对各种场景和关键参数做性能测试和对比,主要关注的指标有 QPS、TPS、RT 等。
说明
当前 OBD 已支持一键运行 Sysbench、TPCC、TPCH,命令详情请参见 OceanBase Deployer 文档。
Sysbench
Sysbench 是一个支持多线程基准测试工具,在数据库性能测试中使用广泛,它最大的优点是可以通过 lua 自定义场景,添加新场景成本低,便于场景持续积累,具有很高的灵活性。
Sysbench 核心流程分为 cleanup(清理数据)、prepare(准备测试数据)、run(开始压测) 三步,常用的参数有并发度、运行时间等。
--tables # 压测表数量
--table_size # 压测的单表大小,单位行
--mysql-host=[LIST,...] 随机直加时配置 ip list
--mysql-port=[LIST,...]
--mysql-user=[LIST,...]
--mysql-password=STRING
--mysql-db=STRING
--db-driver=STRING # 回归中都用 mysql
--db-ps-mode=STRING # auto 生效默认,Disable 时转成 sql 执行
--num-threads=N #并发线程数
--max-time=N # 执行时间
--report-interval=N # 报告间隔,单位:秒
--percentile=N # 打印百分位 rt,默认 95
--tx-rate=N # 指定 TPS, 为 0 不指定
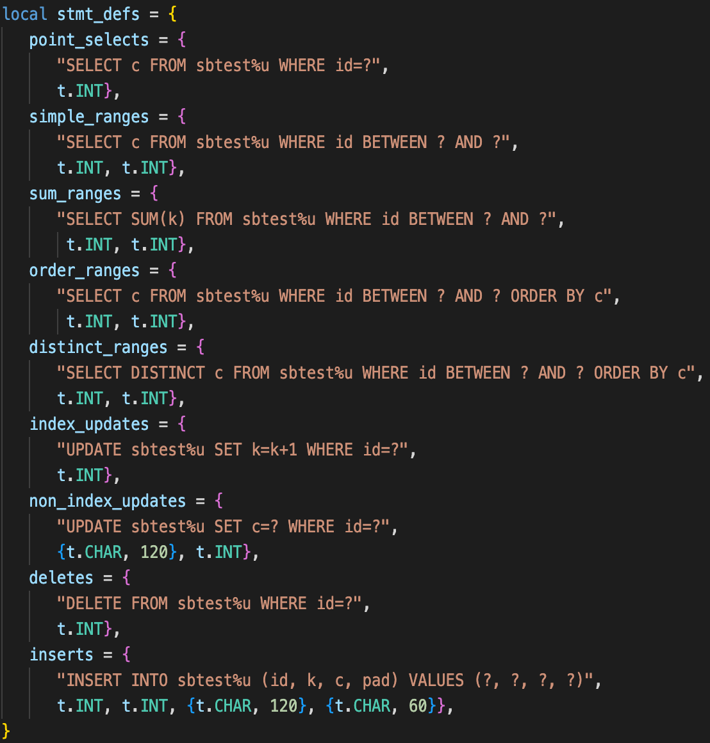
如下所示为 Sysbench 自带的 OLTP 的部分场景,可以看出 Sysbench 自定义场景的成本比较低,可读性非常强。
TPCC
TPCC 是 OLTP 领域中最经典、最受认可的 benchmark 模型,模拟的是经典的商品销售模型。
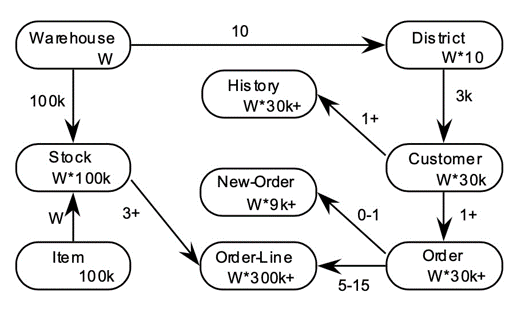
其中有 9 张表,通过仓库的数量 W 调整数据规模,TPCC 各表之间数据比例固定,如下图所示是各表之间数据的比例关系。
5 个经典的事务如下。
NewOrder-新订单的生成
事务内容:对于任意一个客户端,从固定的仓库随机选取 5-15 件商品,创建新订单,其中 1% 的订单要由假想的用户操作失败而回滚。
主要特点:中量级、读写频繁、要求响应快。
占比:45%
Payment-订单付款
事务内容:对于任意一个客户端,从固定的仓库随机选取一个辖区及其内用户,采用随机的金额支付一笔订单,并作相应历史纪录。
主要特点:轻量级、读写频繁、要求响应快。
占比:43%
OrderStatus-最近订单查询
事务内容:对于任意一个客户,从固定的仓库随机选取一个辖区及其内用户,读取其最后一条订单,显示订单内每件商品的状态。
主要特点:中量级、只读频率低、要求响应快。
占比:4%
Delivery-配送
事务内容:对于任意一个客户端,随机选取一个发货包,更新被处理订单的用户余额,并把该订单从新订单中删除。
主要特点:1-10 个批量,读写频率低、较宽松的响应时间。
占比:4%
StockLevel-库存缺货状态分析
事物内容:对于任意一个客户端,从固定的仓库和辖区随机选取最后 20 条订单,查看订单中所有的货物的库存,计算并显示所有库存低于随机生成域值的商品数量。
主要特点:重量级,只读频率低,较宽松的响应时间。
占比:4%
TPCC 通过 tpmC 来做吞吐率衡量,即每分钟内系统处理的新订单个数;TPCC 模型有多种实现工具,如 tpcc-mysql、bmsql 等,OceanBase 使用的是 bmsql。
TPCH
TPCH 是最为流行的 OLAP workload 的 benchmark,TPCH 是用来评估在线分析处理的基准程序,主要模拟了供应商和采购商之间的交易行为,其中包含针对 8 张表的 22 条分析型查询。
TPC-H 的 22 条分析型查询 SQL,主要考验数据库的五种数据分析能力,如下所示:
Aggregation
Join
Expression Calculation
Subqueries
Parallelism and Concurrency
稳定性测试
OceanBase 的稳定性测试的核心思想是 workload + 容灾测试,其中 workload 使用 Sysbench、TPCC、TPCH 等测试工具来模拟压力,容灾测试使用混沌测试工具 ChaosBalde 来模拟 CPU、磁盘、网络、IO、Pod 等故障。
OceanBase 开发了 Obopentest 工具,该工具是基于 Kubernetes 和 ChaosBlade 实现的测试框架,并在此基础上针对 OceanBase 特性新增了容灾类型(如切主、变更副本类型、扩缩容等),下图所示为 Obopentest 工具框架图。
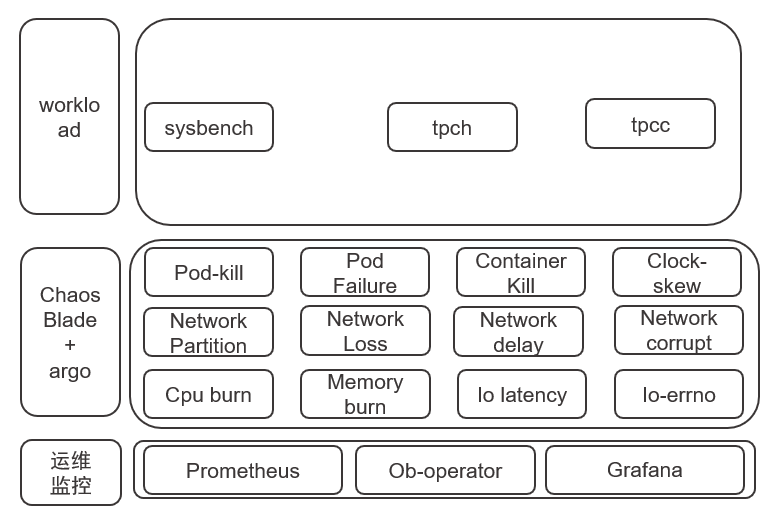
Obopentest 工具使用 Ob-operator 基于 k8s 一键部署 OceanBase 的压测系统,并且通过 Argo 做流程编排。在稳定性测试中如何判断集群是否正常非常关键,因此我们集成了 Prometheus 和 Grafana 来做监控。Obopentest 工具将会在 2022 年底开源出来。
兼容性测试
在 OceanBase 中兼容性测试指的是版本间的升级测试,OceanBase 中版本分为大版本和小版本,其中大版本指版本号发生过变更的版本。OceanBase 中版本号的变更意味着无法直接通过替换 binary 来升级,必须严格按照升级流程升级,比如从社区版 3.1.3 版本升级到社区版 3.1.4 版本就属于大版本的升级。
OceanBase 大版本的升级流程非常复杂,包含如下所示 8 个步骤,每一步都有特定的脚本需要执行,一般不建议手动升级,OCP 和 OBD 工具提供了 OceanBase 的自动化升级。
PRE_CHECK
升级的前置检查,主要是识别当前集群能否升级到目标版本。
对应升级脚本:tools/upgrade/upgrade_checker.py
BEGIN_UPGRADE
集群置为升级状态,此时 OBServer 节点可通过 in_upgrade_mode() 感知集群处于升级状态。
对应命令:
alter system begin upgrade;PRE_UPGRADE
依次执行本次升级涉及的各版本 PRE 脚本,完成系统变量的更新。
对应升级脚本:tools/upgrade/upgrade_pre.py
UPGRADE
按 Zone stop,OBServer 节点替换为新版本 Binary 重启。
UPGRADE_VIRTUAL_SCHEMA:
更新虚拟表、系统视图定义。
对应命令:
alter system upgrade virtual schema;POST_UPGRADE
依次执行本次升级涉及的各版本 POST 脚本。
对应升级脚本:tools/upgrade/upgrade_post.py
END_UPGRADE
结束集群升级状态,并推高集群版本号。
对应命令:
alter system end upgrade;POST_CHECK
升级后自检,还原开关(DDL、Major Freeze),执行需要版本号推高后才能执行的升级动作。
对应升级脚本:tools/upgrade/upgrade_post_checker.py
OceanBase 升级的特征:
按 Zone 滚动升级,升级期间不停服,对用户影响小。
流程复杂,一般自动化操作。
升级自动化服务由 OCP 或 OBD 来提供。
升级兼容性测试需要关注的点:
升级过程中对用户的影响。
升级过程中关注通信协议是否兼容,数据是否兼容。
升级后集群是否可以正常使用,转储、合并是否正常。
OceanBase 使用 OCP 或 OBD 结合各种 workload 来做升级测试。
