





在大数据时代,越来越多的企业正落地“数据驱动”战略,通过实时、多维度地分析海量数据、高效精准地支撑业务决策,来应对日益普遍的不确定性与激烈竞争。
在5表关联、每表1亿条数据量的多条件复杂查询下,RapidsDB在1秒内完成结果反馈。 在5表关联、每表10亿条数据量的多条件复杂查询的情况下,RapidsDB只需3.3秒即完成了查询结果反馈。
在支持OLAP工作负载外,RapidsDB还可支持OLTP及HTAP混合工作负载,全面满足大数据时代的企业数据驱动战略需求。
为构建卓越的多表复杂查询能力,柏睿数据RapidsDB自主研发了如下关键技术。
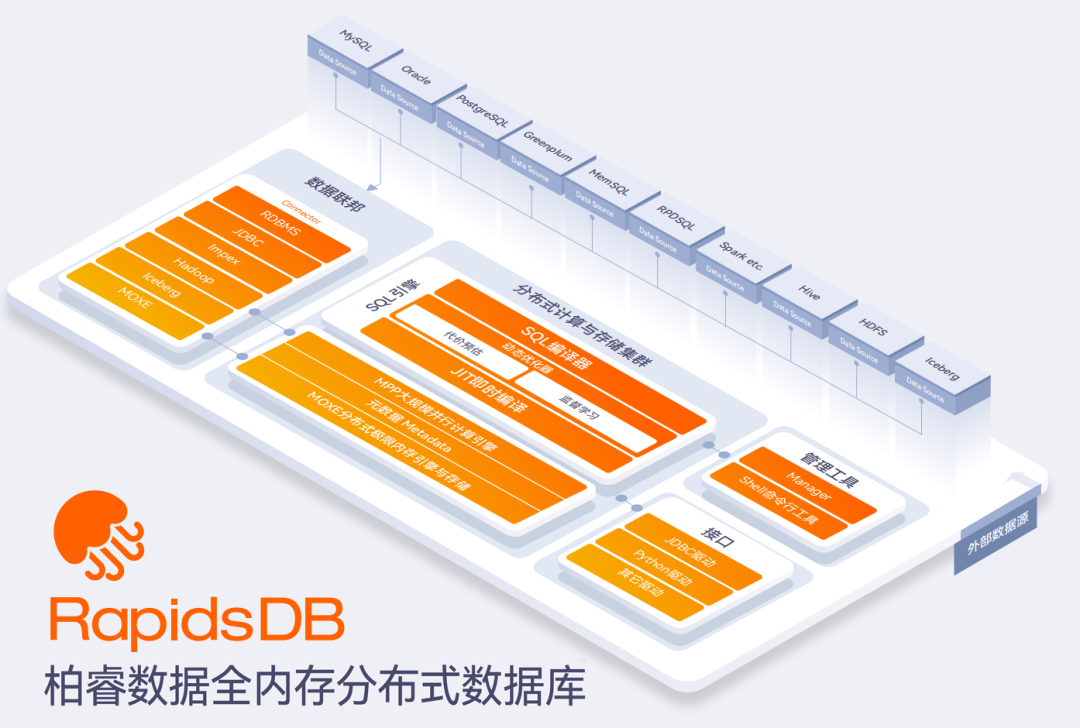
在海量数据下的多表复杂查询会产生大量的数据计算体量,而基于内存的存储和计算,可直接根据记录(Tuple)的内存地址随机查询,此时磁盘I/O已经不是性能瓶颈。
基于经典的Volcano/Cascades优化器,在计划器中将逻辑执行计划和物理执行计划的转换在同一阶段进行,降低冗余的工作,同时将物理执行计划进一步编译优化为内部机器执行码。
另一方面,基于向量化引擎,分布式执行引擎可支持多核多线程工作,通过平均分配处理大量工作,以最大限度地提高CPU使用效率,进一步提升在复杂场景下的查询响应能力。
RapidsDB是一个高度可扩展的分布式系统,在默认情况下,集群中每创建一个存储节点,RapidsDB则在该存储节点上为每个CPU内核创建一个分区,以实现最大化的并行性。在数据库执行的查询任务中,分区是查询并行性的粒度单位。换言之,每个并行查询都以分区数量相同的并行度运行。
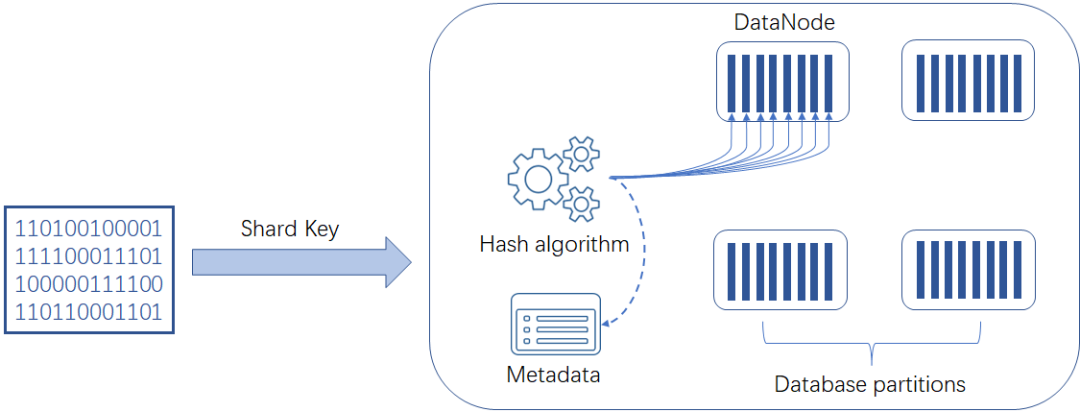
当拥有相同分区索引的表进行关联操作时,因为具有相类似的数据分布特征,各分区内的数据只需要承担大部分分区内部的数据计算和交互工作,从而减少了数据的跨分区流动和计算。在海量数据规模下,则会进一步提升多表复杂关联场景下的性能表现。
具备复杂多表查询能力的数据库,不仅能够通过灵活实时的查询满足业务端更多的应用场景需求,还能在数据开发端降低开发难度与建设成本。
最初基于大宽表的查询场景更多是满足固定报表的查询,非固定场景需要预先制作多种类型的大宽表,这将进一步提升业务的复杂度。而RapidsDB强大的多表查询能力可以提供灵活查询的能力,以及实时查询的能力,真正坐做到了从大宽表的T+1变为T+0的实时业务支持。
此外,数据库多表复杂查询的支持能力,意味着用户可以直接基于源表查询,而无需再根据业务情况制作大宽表。这样做的好处一是可以减少额外的存储成本,二是无需额外的开发内容,由此简化整体开发流程,降低项目建设成本。
推荐阅读



你的 在看 为智能数据算力点赞
