为了帮助开发者学习,我们基于此文内容整理发布了《阿里云ClickHouse企业版技术白皮书》,系统介绍企业版的技术架构和实现原理。
ClickHouse是一个全球流行的开源高性能、可扩展列式数据库技术,核心应用于在线分析处理(OLAP)业务,在DB-Engine全球数据库流行度排榜排名前列,逐年关注度增长迅猛。ClickHouse分析性能优异,在典型分析场景下,支持数十亿级数据行规模,90%查询在1秒内完成。这使得ClickHouse成为企业处理大规模数据,构建实时数仓的理想选择。微软、ebay、Uber等国内外大厂都在使用ClickHouse构建数据分析平台。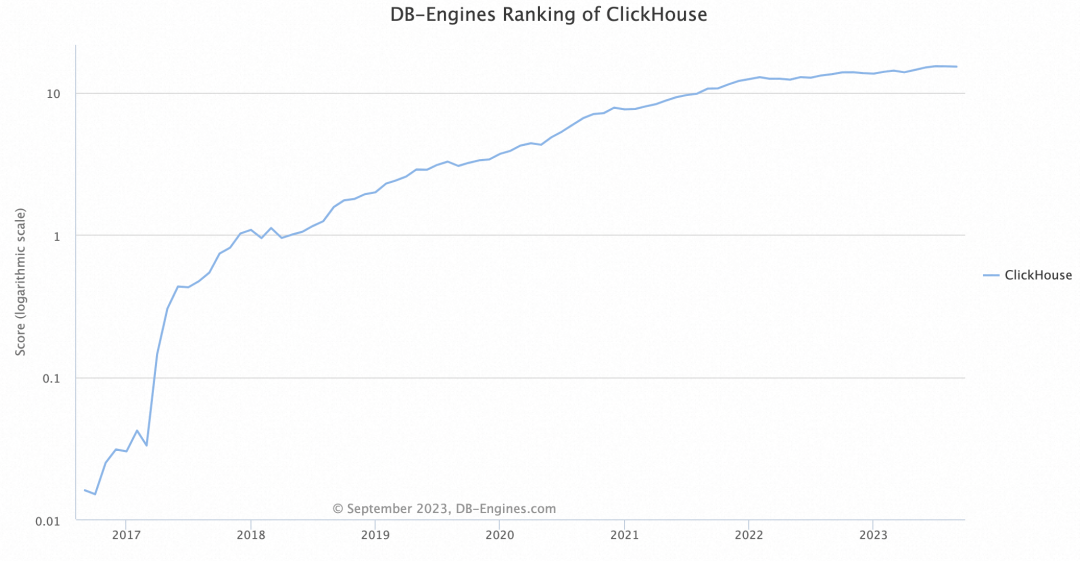
阿里云在2020年发布了基于开源社区版本的云数据库ClickHouse社区兼容版,是全球领先的大规模提供全托管ClickHouse服务的云厂商,成熟稳定服务了包含互联网、游戏、电商、金融保险、汽车制造、媒体广告在内的数千家客户。2021年9月20日, ClickHouse项目创始人 Alexey 在 GitHub 宣布他们正式从 Yandex 独立,并成立一个公司:ClickHouse, Inc。2023年阿里云与ClickHouse, Inc达成独家的商业合作,联合研发阿里云数据库ClickHouse企业版(以下简称ClickHouse企业版),并于2023年8月末开启邀测。
今年3月,阿里云与ClickHouse正式签订战略合作协议
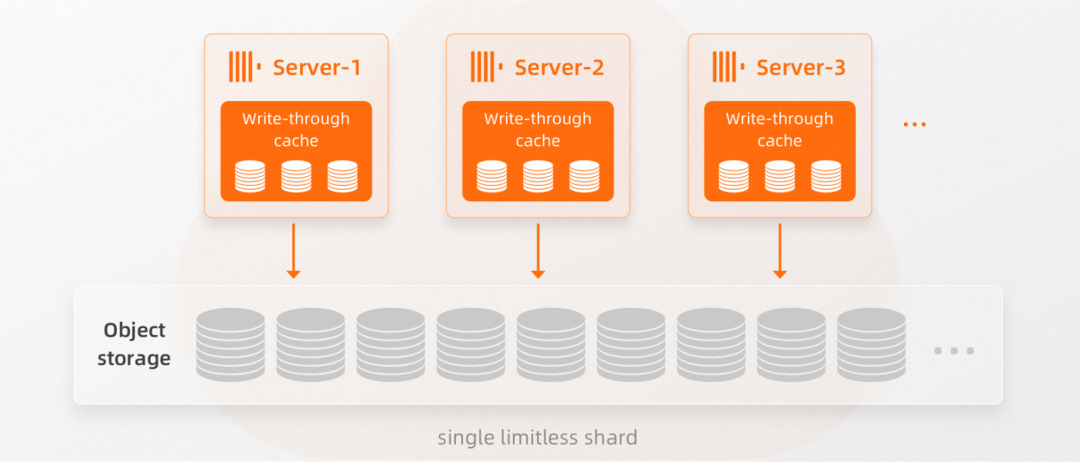
ClickHouse企业版对比社区版是里程碑的升级,从传统存算一体的架构全面升级为云原生架构,支持云原生按需弹性 Serverless能力,解决了长期困扰用户的集群扩展效率和平滑性问题。同时升级支持lightweight update&delete, 数据更新实时可见,且执行成本更低,效率更高。本文将详细揭秘ClickHouse企业版的技术实现原理。ClickHouse企业版采用完全不同与开源社区版本的云原生新架构,针对云环境做了全面适配。新架构基于存储和计算分离的架构基础,采用对象存储数据实现Share Storage共享存储,所有ClickHouse Server节点都可以访问相同的全局物理数据, 单个Server节点实际上是单个没有限制分片的Replica节点,节点之间访问同一份数据副本。
云数据库ClickHouse企业版产品架构图
MergeTree系列的表引擎是ClickHouse中的主要表引擎。它们负责存储插入的数据,在后台进行数据合并,根据特定的引擎进行数据转换等操作。企业版新推出 SharedMergeTree 引擎加入到MergeTree引擎大家庭,而企业版能够支持云原生架构,也核心依赖SharedMergeTree引擎。SharedMergeTree引擎是商业化引擎,仅在企业版提供,在开源社区版不支持。企业版内核相较于开源社区版的核心能力差异如下所示:大多数MergeTree家族中的表都支持自动的数据复制,并通过ReplicatedMergeTree 表引擎的复制机制实现。在社区版Share-nothing架构的ClickHouse集群中,通过ReplicatedMergeTree进行复制以实现数据高可用,并通过分片实现集群横向扩展。阿里云ClickHouse社区兼容版也正是基于这一内核特性实现的高可用和扩展。而 ClickHouse企业版采用了一种新方法,基于SharedMergeTree构建了云原生数据库服务。SharedMergeTree表引擎是ClickHouse内核ReplicatedMergeTree表引擎的更高效的替代品,专为云原生数据处理而设计和优化。我们将深入了解这个新表引擎,解释其优势,并通过基准测试展示其效率。同时当前正在引入轻量级更新Lightweight Update,与SharedMergeTree形成协同效应。
▶︎ 对象存储上的数据可用性
ClickHouse企业版将所有数据存储在对象存储中,所以不需要在不同服务器上显式地创建数据的物理副本。对象存储本身实现确保存储具有高可用性和容错性。需要注意的是,尽管访问对象存储较慢,但ClickHouse企业版服务具有多层读写缓存,它专为在对象存储上读写而设计,以提供快速的查询结果。对象存储虽然访问延迟比磁盘较大,但具有高并发吞吐量和大的聚合带宽。ClickHouse企业版通过利用多I/O线程来访问对象存储,并通过异步预读取数据来改善这一点。▶︎ 自动集群扩展
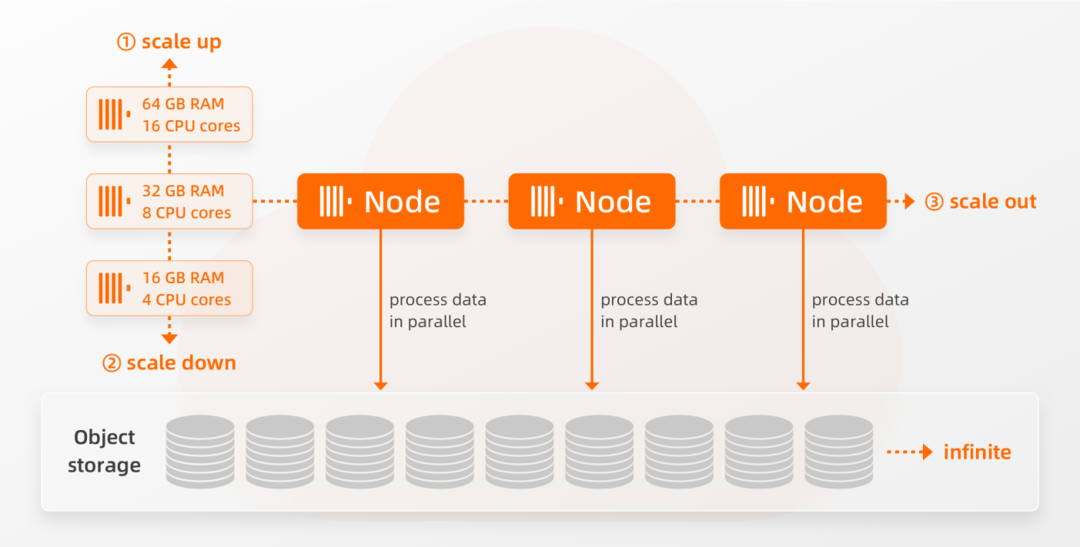
与开源版本使用分片来扩展集群不同,ClickHouse企业版让用户通过简单地增加计算节点的规格和数量来增加 INSERT和SELECT的并行处理能力。请注意,ClickHouse企业版计算节点实际上是单分片的多个副本。这些节点不是包含相同数据的本地副本节点,而是可以访问存储在对象存储中全量相同的数据的无状态差异节点。计算节点规格和数量可以适应工作负载,进行对应的升降配和水平扩缩容,具体步骤描述如下图所示:通过①垂直升配操作和②垂直缩容操作,我们可以更改节点的规格(CPU和内存)。而通过③水平扩展,我们可以增加计算节点的数量。而无需进行任何物理Resharding或数据的Rebalancing,我们可以自由地添加或删除节点。这种无数据移动和搬迁支持水平集群扩展方法,就需要ClickHouse企业版能够提供支持节点访问相同共享数据的表引擎。
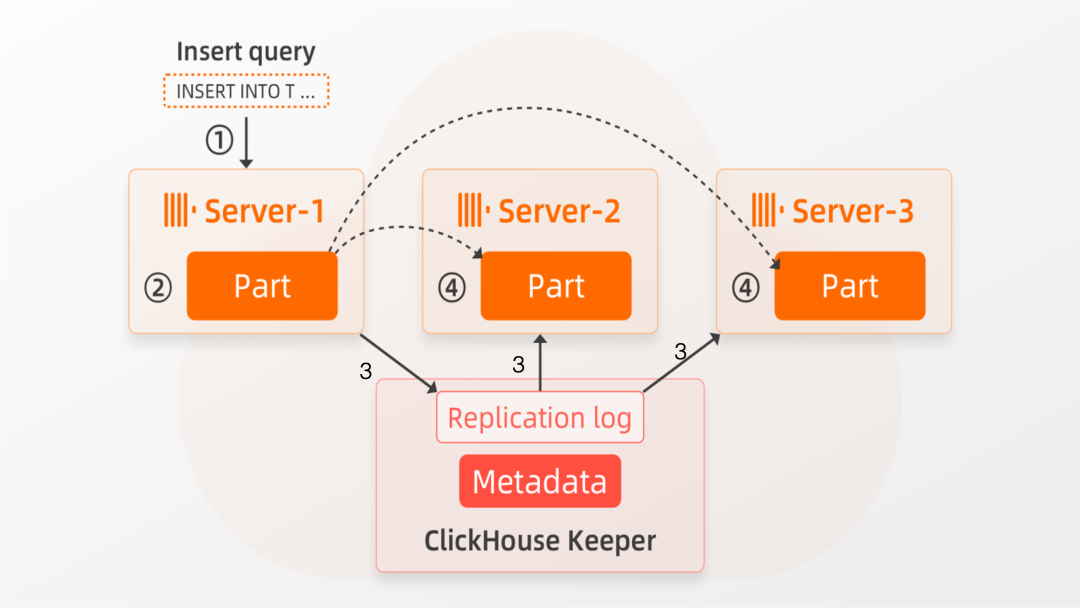
ReplicatedMergeTree表引擎并不适用于ClickHouse企业版的预期架构,因为其复制机制旨在在少量的节点上创建数据的物理副本。而ClickHouse企业版需要一个支持在对象存储之上运行大量计算服务节点的表引擎。首先我们解释一下ReplicatedMergeTree表引擎的复制机制。该引擎使用ClickHouse Keeper(也称为“Keeper”)作为协调系统,通过复制日志方式进行数据复制。Keeper充当复制过程特定元数据和表结构的集中式存储,以及分布式操作的一致性协调系统。Keeper确保为Part顺序地分配连续的块编号,将merge和mutation操作分配给特定的replica。下图概述了一个具有3个replica节点的shared-nothing架构的ClickHouse集群,并显示了ReplicatedMergeTree表引擎的数据复制机制:当①Server-1接收到插入查询时,②Server-1在其本地磁盘上创建一个包含插入数据的新Part。③通过复制日志,其他节点(Server-2、Server-3)被告知Server-1上存在一个新Part。在④处,其他server独立地从server-1下载(“获取”)该Part到自己的本地文件系统。创建或接收Part后,三个节点还会在Keeper中更新元数据,元数据用以描述Part文件信息。请注意,我们仅展示了如何复制新创建的Part。Part合并(和mutation)也以类似的方式复制。如果一个节点决定合并一组Parts,那么其他节点将在其本地Parts副本上自动执行相同的合并操作。在本地存储完全丢失或添加新副本时,ReplicatedMergeTree从已有的副本克隆数据。ClickHouse企业版使用持久性更好的对象存储来实现数据可用性,所以不需要ReplicatedMergeTree的显式数据复制功能。shared-nothing架构下的ClickHouse集群用户可以将replication与sharding相结合,来实现高可用和水平扩展。表中数据以分片的形式分布在多个节点上,每个分片通常有2个或3个副本,以确保存储和数据可用性。通过添加更多分片,可以增加数据写入和查询处理的并行能力。而ClickHouse企业版不需要使用分片进行集群扩展,因为所有数据都存储在共享的对象存储中,只需通过添加额外的节点来增加并行数据处理能力。
ClickHouse企业版实现了一个名为SharedMergeTree的表引擎——专为在共享存储上工作而设计。SharedMergeTree是云原生方式,具有如下优点:1. MergeTree 代码更加简单易维护;
2. 支持垂直和水平自动扩展;
3. 为我们的云用户提供未来的功能和改进。如更高的一致性保证、更好的耐用性、基于时间点数据恢复等。SharedMergeTree引擎下的集群扩展原理
在这里,我们简要介绍SharedMergeTree如何支持ClickHouse企业版自动进行集群扩展。提醒一下:ClickHouse企业版计算节点是具有访问共享存储的计算单元,其规格和数量可以更改。基于此机制,SharedMergeTree完全将业务数据和元数据的存储与计算节点分离,并使用Keeper的接口去读取、写入和修改共享元数据。每个计算节点都有一个存储元数据的本地缓存,并通过订阅机制自动获取数据更改的通知。下图描述了如何使用SharedMergeTree将新服务器添加到集群中: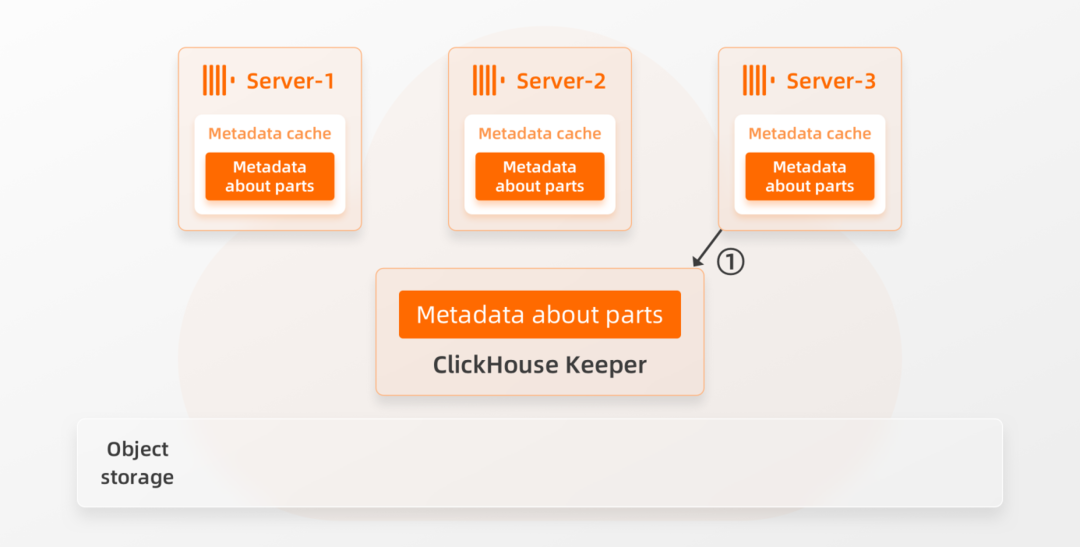
1. 当Server-3添加到集群时,这个新Server ①订阅Keeper中的元数据更改信息并将当前Parts的元数据获取到其本地缓存中。这不需要任何锁机制;2. ②新Server基本上只需说:“我在这里。请随时通知我所有数据更改”。3. ③新添加的Server-3几乎可以立即参与数据处理,因为它通过从Keeper中只获取必要的元数据信息,找到有哪些数据以及在共享存储中的什么位置。
SharedMergeTree引擎下的数据一致性原理
下图描述所有Server节点如何知道新插入的数据,来保证查询数据一致性: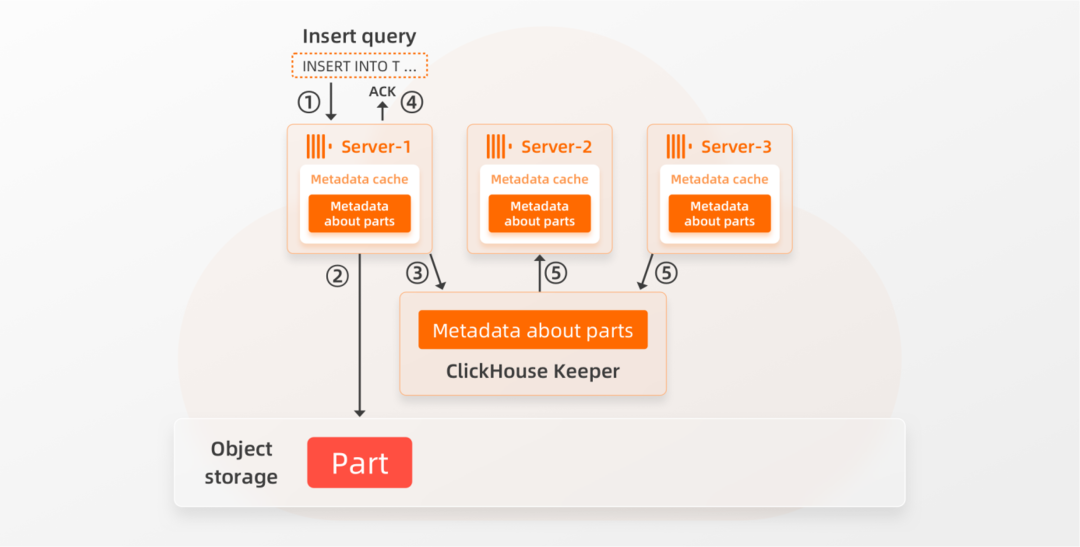
① Server-1接收到插入查询
② Server-1将写入的数据以Part的形式写入共享存储。
③ Server-1还将关于该部分的信息存储在其本地缓存和Keeper中(例如,哪些文件属于该Part,以及与文件对应的块位于共享存储中的位置)。
④ ClickHouse向查询的发送者确认插入成功。其他节点(Server-2、Server-3)通过 Keeper 的订阅机制⑤自动得到存储层中存在新数据的通知,并将更新的元数据提取到其本地缓存中。请注意,在步骤④之后,插入的数据是持久的。即使Server-1或其他任何节点崩溃,Part都存储在高可用的存储中,元数据存储在Keeper中(Keeper具有至少3个Keeper节点的高可用设置)。从集群中移除节点也是一个简单且快速的操作。为了优雅地移除,相关节点只需从 Keeper中注销,以便处理进行中的分布式查询时不会出现缺少服务器的警告。
在ClickHouse企业版中,SharedMergeTree表引擎是ReplicatedMergeTree表引擎的更高效的替代品。为ClickHouse企业版用户带来以下好处:ClickHouse企业版将所有数据存储在存储量几乎无限的共享存储中。SharedMergeTree表引擎为所有表添加了共享的元数据存储。它实现了在该存储之上运行的节点几乎无限的扩展。服务器实际上是无状态的计算节点,我们可以立即改变它们的规格和数量,如下示例:
假设ClickHouse企业版用户当前正在使用三个节点,如下图所示: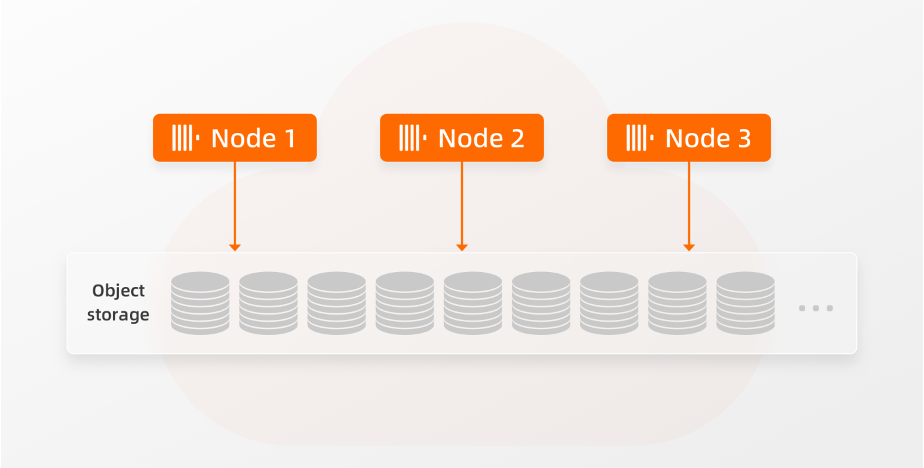
通过简单地(手动或自动)将每个节点的大小翻倍,或者根据实例负载,将节点数量从三个翻倍到六个,用户可以实现计算能力的翻倍:
同时也会使写入吞吐量翻倍。对于SELECT查询,增加节点数会增加并发查询能力,以及单个查询的并发执行。请注意,在ClickHouse企业版中增加(或减少)节点的数量不需要进行物理数据resharding或rebalancing,我们可以自由地添加或删除节点。而在shared-nothing架构下的集群中更改节点数量需要更多的工作和时间。如果一个集群当前由三个分片,每个分片由两个副本组成: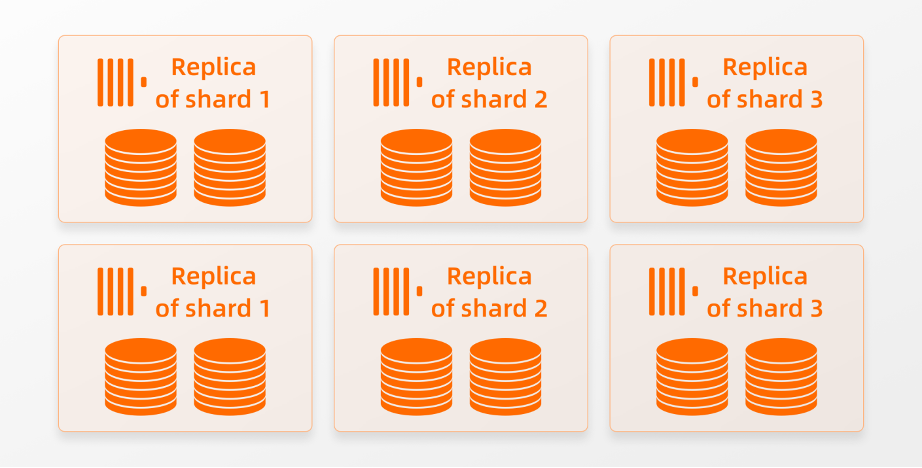
然后翻倍分片数量需要对当前存储的数据进行resharding和rebalancing:对于开源ReplicatedMergeTree,需要使用insert_quorum设置来确保数据的持久性,可以配置插入的数据仅在指定数量的副本上持久化好时返回给发送者。对于SharedMergeTree,不需要insert_quorum。如上所示,当插入成功返回给发送者时,查询的数据将存储在高可用的共享存储中,并且元数据集中存储在Keeper中。
如果您的使用场景对每个节点都返回相同的查询结果有一致性保证的要求,则可以运行SYNC REPLICA系统语句,这在SharedMergeTree中是一个更轻量级的操作。每个节点不需要在节点之间同步数据,只需从Keeper中获取当前版本的元数据即可。
通过SharedMergeTree,增加更多的节点不会导致性能下降。在Keeper资源充足的情况下,后台合并的吞吐量随着节点数量的增加而增加。对于显式触发的mutation(默认情况下为异步执行合并)也是如此。
这对于ClickHouse中的其他新功能具有积极的影响,例如SharedMergeTree为Lightweight Update提供了性能提升。同样地,特定引擎的数据转换(AggregatingMergeTree的聚合,ReplacingMergeTree的去重等)也受益于 SharedMergeTree能够提供更好的合并吞吐量。这些转换在后台Parts合并过程中逐步应用。为了确保查询结果的正确性,用户需要在查询时通过使用FINAL修饰符或使用带有显式GROUP BY子句来合并还未合并的数据。在这两种情况下,更高的合并吞吐量都会加速查询的执行速度。因为此时查询所需要进行的数据合并工作较少。SharedMergeTree表引擎现在已经作为ClickHouse企业版中默认的表引擎。ClickHouse企业版支持的MergeTree家族中的所有特殊表引擎,并都会自动基于 SharedMergeTree进行更新。例如,当您创建ReplacingMergeTree表时,ClickHouse企业版将在后台自动创建一个SharedReplacingMergeTree表:在本节中,我们将展示SharedMergeTree的无缝写入性能扩展能力。
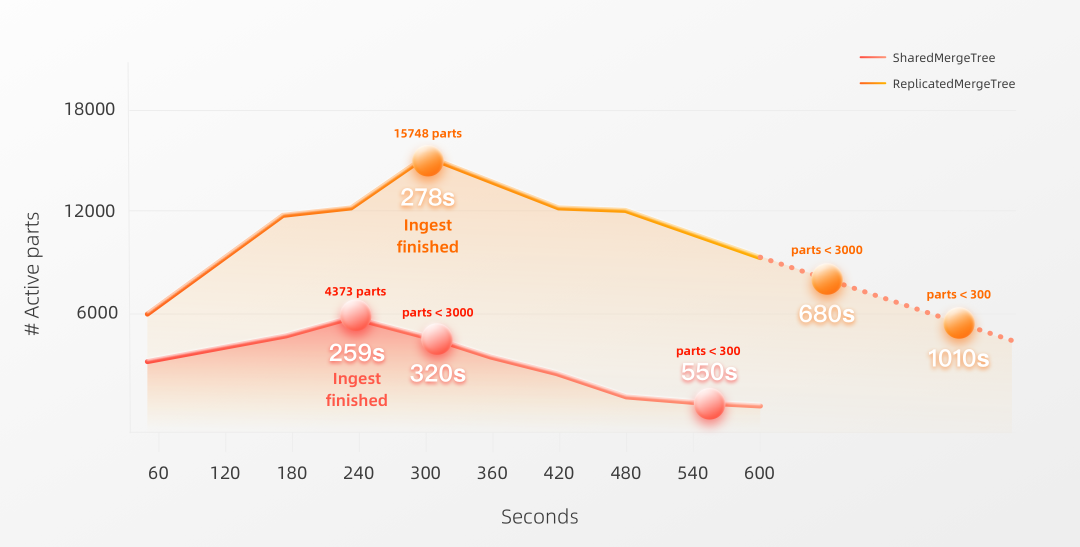
在我们的测试case中,我们将2022年前六个月的WikiStat数据集加载到ClickHouse企业版中的一张表中。为此,ClickHouse需要从大约4300个压缩文件(一个文件代表一天的一个小时)中加载约260亿条记录。我们使用了四种不同数量节点的配置。每个节点都有 30 个 CPU和 120 GB 内存:请注意,前两个集群配置都使用了一个3节点ClickHouse Keeper服务,每个节点有3个CPU和2 GB内存。对于 20 个节点和 80 个节点的配置,我们将Keeper的大小增加到每个节点有 6 个 CPU和6 GB内存。在数据加载运行期间,我们监控了Keeper,以确保Keeper的资源不是瓶颈。Shared*MergeTree并行使用的节点数量越多,期望数据加载速度越快,同时每个时间单位内创建的Parts也越多。为了实现SELECT查询的最大性能,有必要尽量减少处理的Parts数量。为此,每个MergeTree表引擎在后台不断将Parts合并成更大的Parts。每个表的默认健康Parts数量(表分区)是 3000 个(之前是 300 个)。因此,我们测量了从开始加载数据起,到在数据写入完成,整个期间创建的Parts合并到少于 3000 个的健康数量所花费的时间。为此我们使用系统表上的SQL查询来监控活动Parts随时间的变化。请注意,同时我们还选择了shared-nothing架构下的ReplicatedMergeTree表引擎进行写入参照。如上所述,这个表引擎并不适合支持高数量的副本节点。以下图表显示了将所有Parts合并为少于 3000 个健康Parts所花费的时间(以秒为单位):SharedMergeTree 支持无缝的集群扩展。我们可以看到,在我们的测试中,后台合并的吞吐量与节点数量呈线性关系。当我们将节点数量从 3 增至 10 时,吞吐量也将增加三倍左右。当我们将节点数量再次增加 2 倍至 20,然后增加 4 倍至 80 时,吞吐量也分别增加了约两倍和四倍。正如预期的那样,使用ReplicatedMergeTree 在随着副本节点数量的增加时无法很好地扩展(甚至在较大的集群大小下会减少写入性能),而SharedMergeTree则随着副本节点数量的增加而获得更好的扩展。因为它的复制机制不适用于处理大量副本的情况。为了完整起见,下图显示了将Parts合并少于 300个所花费的时间。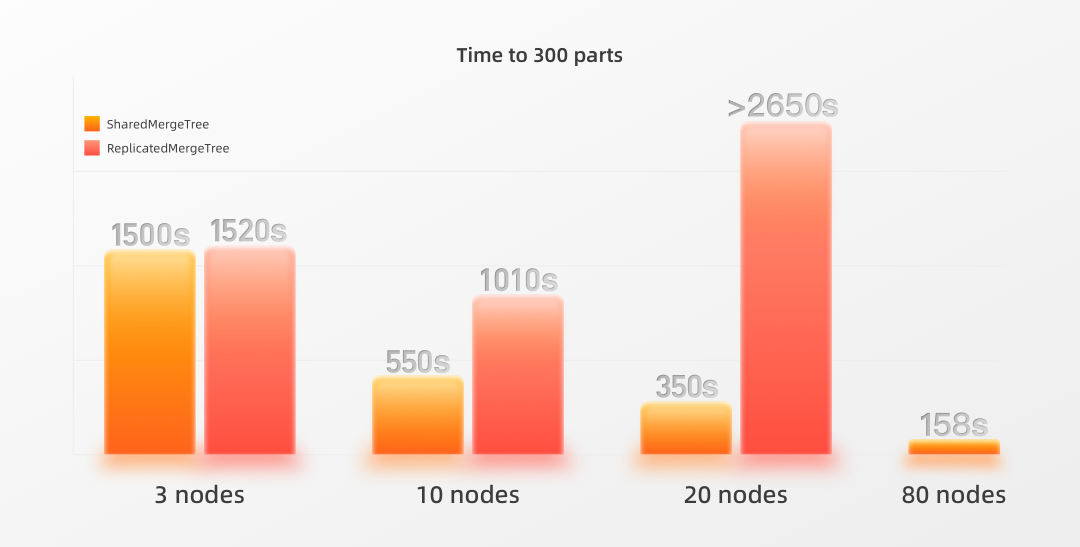
▶︎ 3 个节点
下图可视化了在具有3个副本节点的集群上进行基准测试,期间活动Parts的数量,成功加载数据所花费的秒数(见Ingest finished标记),以及在将Parts合并到少于3000 和 300 个活动Parts时所花费的秒数:我们可以看到两种表引擎的性能在这里非常相似。
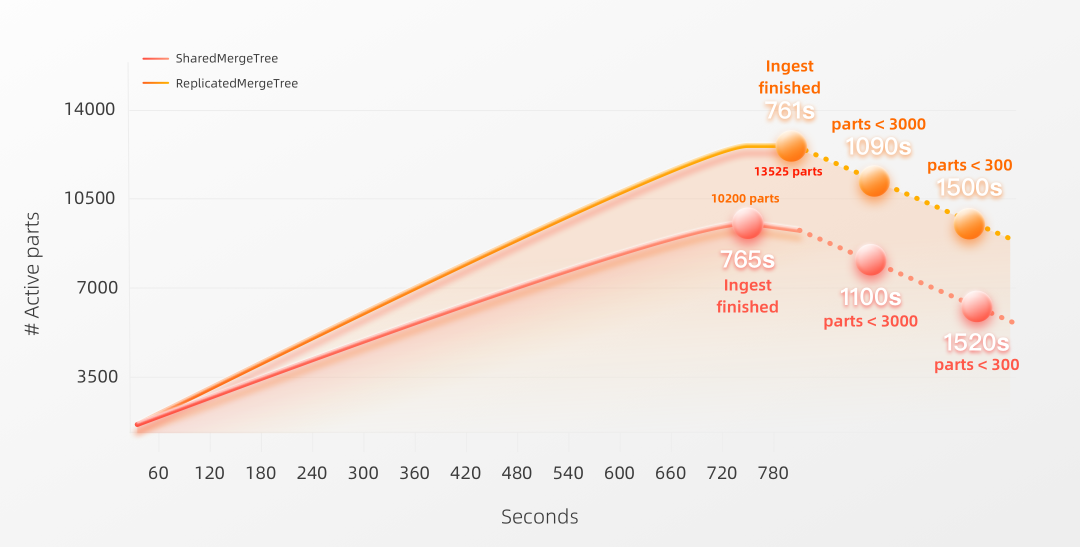
我们可以看到两种表引擎在数据加载期间执行的合并操作的数量大致相同:▶︎ 10 个节点
在10 个节点的集群中,我们可以看到一些不同之处:写入时间的差异只有 19 秒。然而,当写入完成时,两种表引擎活动Parts的数量是非常不同的。对于使用ReplicatedMergeTree,该数量要多三倍以上。并且将Parts合并到少于 3000 和 300 个活动Parts所花费的时间也要多两倍。这意味着我们可以更早地通过SharedMergeTree获得更快的查询性能。当写入完成时,大约 4 千个活动Parts的数量仍可以进行查询。而大约1万5个数量级时,则是不可行的。对于从WikiStat数据集写入约 260 亿行的任务,这两种引擎都会创建大约2万3千个初始Parts,每个部分大小约为 10 MB,包含大约 100 万行数据:WITH
'default' AS db_name,
'wikistat' AS table_name,
(
SELECT uuid
FROM system.tables
WHERE (database = db_name) AND (name = table_name)
) AS table_id
SELECT
formatReadableQuantity(countIf(event_type = 'NewPart')) AS parts,
formatReadableQuantity(avgIf(rows, event_type = 'NewPart')) AS rows_avg,
formatReadableSize(avgIf(size_in_bytes, event_type = 'NewPart')) AS size_in_bytes_avg,
formatReadableQuantity(sumIf(rows, event_type = 'NewPart')) AS rows_total
FROM clusterAllReplicas(default, system.part_log)
WHERE table_uuid = table_id;
┌─parts──────────┬─rows_avg─────┬─size_in_bytes_avg─┬─rows_total────┐
│ 23.70 thousand │ 1.11 million │ 9.86 MiB │ 26.23 billion │
└────────────────┴──────────────┴───────────────────┴───────────────┘
大约2万3千个初始Parts均匀分布在这 10 个副本节点上:WITH
'default' AS db_name,
'wikistat' AS table_name,
(
SELECT uuid
FROM system.tables
WHERE (database = db_name) AND (name = table_name)
) AS table_id
SELECT
DENSE_RANK() OVER (ORDER BY hostName() ASC) AS node_id,
formatReadableQuantity(countIf(event_type = 'NewPart')) AS parts,
formatReadableQuantity(sumIf(rows, event_type = 'NewPart')) AS rows_total
FROM clusterAllReplicas(default, system.part_log)
WHERE table_uuid = table_id
GROUP BY hostName()
WITH TOTALS
ORDER BY node_id ASC;
┌─node_id─┬─parts─────────┬─rows_total───┐
│ 1 │ 2.44 thousand │ 2.69 billion │
│ 2 │ 2.49 thousand │ 2.75 billion │
│ 3 │ 2.34 thousand │ 2.59 billion │
│ 4 │ 2.41 thousand │ 2.66 billion │
│ 5 │ 2.30 thousand │ 2.55 billion │
│ 6 │ 2.31 thousand │ 2.55 billion │
│ 7 │ 2.42 thousand │ 2.68 billion │
│ 8 │ 2.28 thousand │ 2.52 billion │
│ 9 │ 2.30 thousand │ 2.54 billion │
│ 10 │ 2.42 thousand │ 2.68 billion │
└─────────┴───────────────┴──────────────┘
Totals:
┌─node_id─┬─parts──────────┬─rows_total────┐
│ 1 │ 23.71 thousand │ 26.23 billion │
└─────────┴────────────────┴───────────────┘
但是SharedMergeTree引擎在数据加载过程中更有效地合并了这些部分:

▶︎ 20 个节点
当20个节点并行插入数据时,使用ReplicatedMergeTree无法应对每单位时间内新创建的Parts数。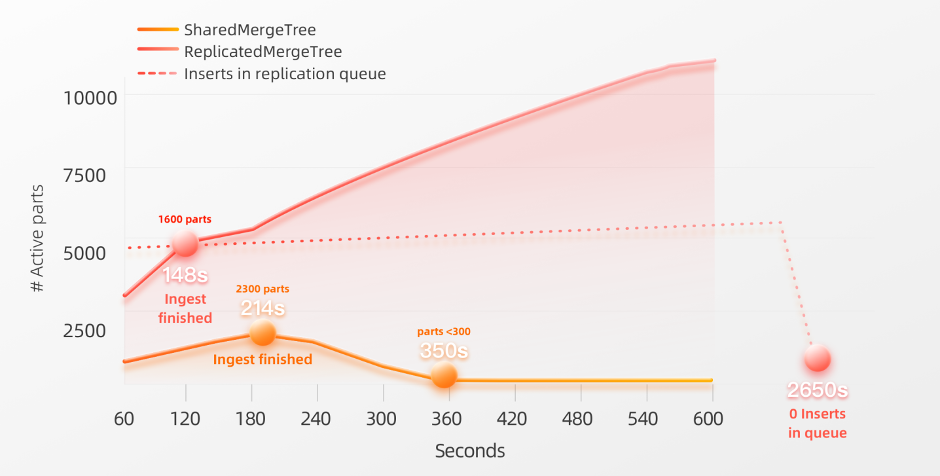
尽管ReplicatedMergeTree在SharedMergeTree之前完成了数据插入过程,但活动parts的数量仍然持续增加到约 1 万个左右。因为ReplicatedMergeTree引擎仍然在复制队列中有需要在这 20 个节点之间进行复制的insert操作。通过这个查询我们获取了在复制队列中的insert数。处理该队列花费了将近 45 分钟。20 个节点每单位时间创建大量新的Parts会导致复制日志上的竞争过于激烈,并且锁和节点间通信的开销过高。减轻这种情况的方法是通过手动调整插入查询的一些设置来限制新创建部分的数量。例如,您可以减少每个节点的并行插入线程数(max_insert_threads),并增加写入每个新Parts的行数(min_insert_block_size_rows)。需要注意的是,后者会增加内存使用。需要注意的是,测试运行期间Keeper的负载并未过载。以下截图显示了两种表引擎的Keeper的CPU和内存使用情况:
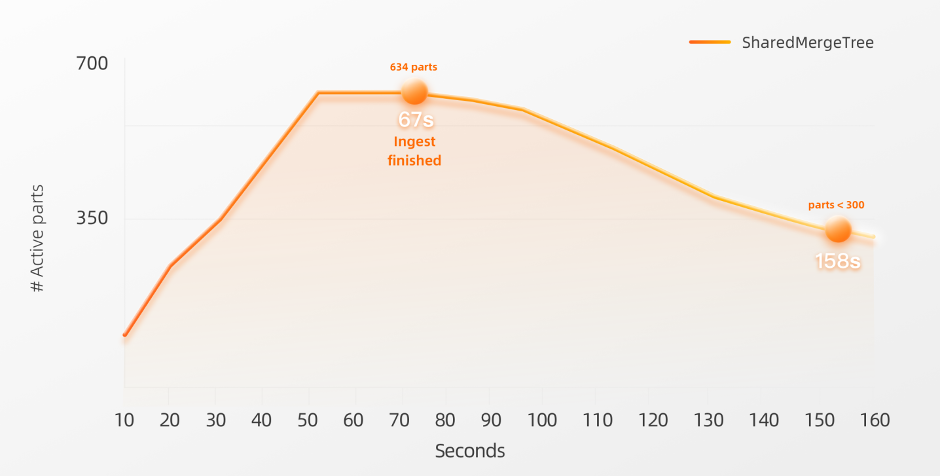
在我们的 80 个节点集群中,我们只将数据加载到一个SharedMergeTree表中。我们已经在上面解释了使用ReplicatedMergeTree并不适用于更高的副本节点数的场景。插入 260 亿行的过程在 67 秒内完成,平均速度为每秒 3.88 亿行。SharedMergeTree是云原生服务的一个重要基础组成。它使我们能够在以前无法或过于复杂实现的情况下构建新的功能和改进现有功能。许多功能从SharedMergeTree的架构下受益,使ClickHouse企业版性能更强、更易用和高持久性。其中一个特性就是“Lightweight Update” :一种可以在使用更少资源的情况下立即使 ALTER Update 查询的结果实时可见的优化。
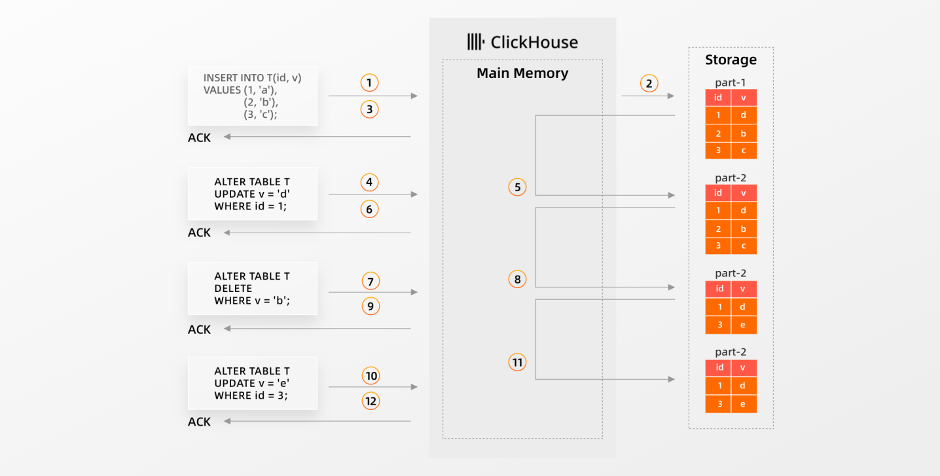
ClickHouse中的ALTER TABLE … Update是通过mutation来实现的。mutation是一个重型操作,可以同步或异步地重写Parts。
在我们上面的示例情况中,ClickHouse ①接收一个对空表的插入操作,②将插入的数据以新的Part写入存储中,并③确认插入。接下来,ClickHouse ④接收一个更新操作并通过⑤ mutate Part-1来执行该操作。该Part被加载到内存中,执行修改,修改后的数据被写入和存储到新的 Part-2中(Part-1 被删除)。只有在该Part重写完成时,才会将⑥对更新操作的确认返回到更新的发起者。其他更新(或删除数据)也以相同的方式执行。对于较大的Part,这是一个非常重的操作。▶︎ 异步mutation
默认情况下,为了将几个收到的更新融合到单个mutation中,更新操作是异步执行的,以减轻重写Parts对性能的影响: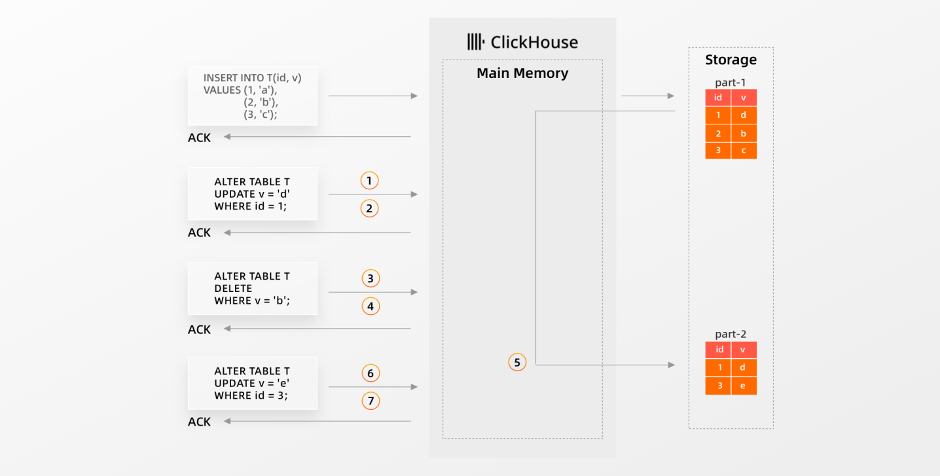
当ClickHouse ①接收到更新操作时,更新会被添加到队列中并异步执行,②更新查询立即获得更新的确认。
请注意,在更新被后台的mutation物化之前,表中的SELECT操作不会看到更新的数据⑤。
此外,注意ClickHouse可以将排队的更新融合到单个Part重写操作中。因此,最好的做法是批量更新,并通过单个查询发送数百个更新操作。
企业版Lightweight Update轻量操作且实时性高
▶︎ 更新机制
Lightweight update不再需要显式地对更新查询进行批处理,从用户的角度来看,即使在mutation异步物化时,来自单个更新操作的修改也会立即成功。下图描述了 ClickHouse 中的轻量级即时更新机制: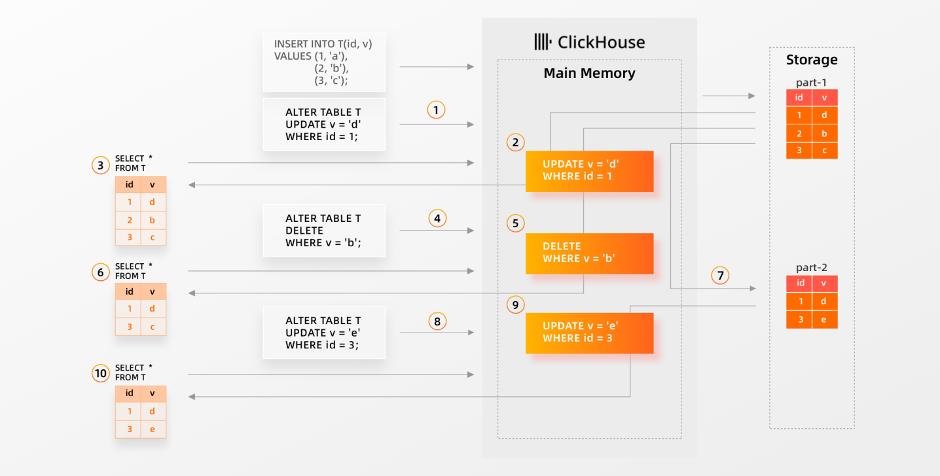
当ClickHouse ①接收到更新操作时,更新会被添加到队列并异步执行。②此外,将更新操作的表达式会放入内存中。同时更新操作也存储在 Keeper上,并分发到其他节点。当③ ClickHouse 在更新还未通过Parts重写和物化之前接收到 SELECT 查询时,ClickHouse 将按照通常的方式执行 SELECT 查询 - 使用primary index来减少需要从Parts流到内存的数据集合,然后在流式传输的数据集合上应用来自②的更新数据。这就是我们称之为 on [the] flymutation的机制。当④另一个更新操作被 ClickHouse 接收时,⑤查询的更新(这次是删除)表达式再次保存在内存中,然后⑥后续的 SELECT 查询将被执行,通过将(② 和 ⑤)更新表达式应用于流式传输的数据集合上。当 ⑦ 所有排队的更新都通过下一个后台mutation物化到parts上时,on-the-fly 更新表达式将从内存中删除。⑧新接收的更新操作和⑩SELECT 查询将按照上述所述执行。这个新的机制可以通过将 apply_mutations_on_fly 设置为 1 来启用。▶︎ 实时性优势
用户无需等待mutation物化。ClickHouse立即提供更新后的结果,同时使用更少的资源。此外,这使得ClickHouse用户更容易使用更新,而无需考虑如何批处理更新。▶︎ 与SharedMergeTree的协同
从用户的角度来看,Lightweight Update的修改会立即生效,但在物化更新前,用户会体验到SELECT查询的性能稍微降低了,因为应用更新表达式会消耗一点查询时间。而随着更新在后台的合并操作中被物化,因此对查询延迟的影响会消失。SharedMergeTree表引擎对后台合并和提升mutation的吞吐量和可扩展性都有帮助,因此mutation完成得更快,Lightweight Update后的SELECT查询也更快地恢复到全。在这篇文章中,我们探索了新的ClickHouse企业版SharedMergeTree表引擎的机制。我们解释了为什么需要引入一种新的表引擎,包含垂直和水平可扩展的计算节层,及几乎没有存储上限对象存储层的读写分离架构。SharedMergeTree可以在存储之上无缝且几乎无限地扩展计算层。插入和后台合并的吞吐量可以轻松扩展,这有助于 ClickHouse中的其他功能,如Lightweight Update和特定引擎的数据转换。
此外,SharedMergeTree 为插入提供了更好的持久性,为Select查询提供了更轻的强一致性。为新的云原生功能和改进打开了大门。我们通过基准测试展示了引擎的效率,并对由SharedMergeTree支持的,称为Lightweight Update的新功能,进行了详细的描述。
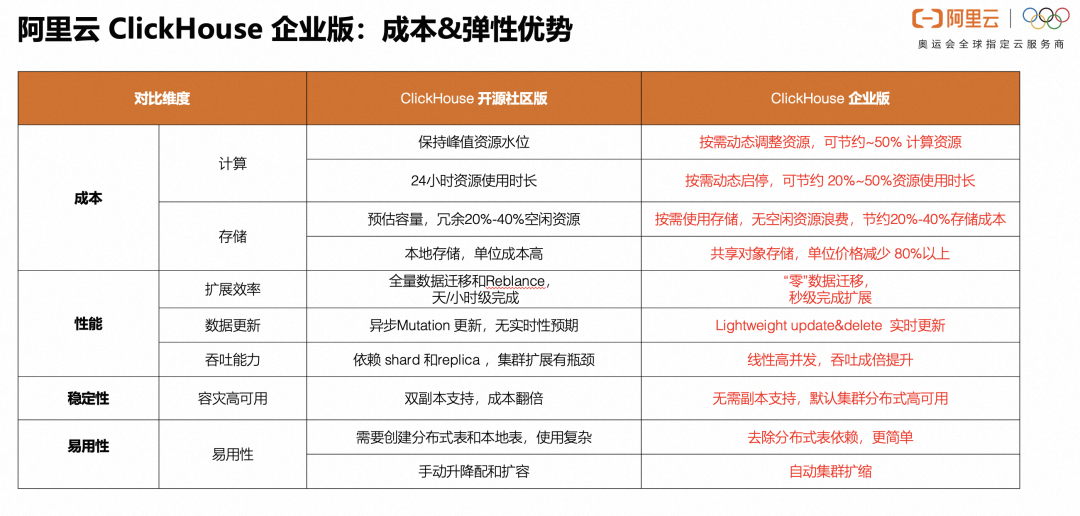
ClickHouse企业版在成本、性能、稳定性上对比开源社区版都有极大的提升,具体对比如下:
我们期待看到这个新的表引擎能提升您在ClickHouse企业版使用场景中的性能。当前阿里云已经上线发布了基于SharedMergeTree的ClickHouse企业版并启动邀测,欢迎您申请测试使用。扫描下方二维码即可提交邀测申请单。
扫码提交邀测申请单
👉 欢迎钉钉搜索群组,加入ClickHouse技术交流群和我们一起讨论。
ClickHouse技术交流群1:34842991
ClickHouse技术交流群2:23300515



 点击 阅读原文 下载《阿里云ClickHouse企业版技术白皮书》
点击 阅读原文 下载《阿里云ClickHouse企业版技术白皮书》