




关于 PolarDB PostgreSQL 版
PolarDB PostgreSQL 版是一款阿里云自主研发的云原生关系型数据库产品,100% 兼容 PostgreSQL,高度兼容Oracle语法;采用基于 Shared-Storage 的存储计算分离架构,具有极致弹性、毫秒级延迟、HTAP 、Ganos全空间数据处理能力和高可靠、高可用、弹性扩展等企业级数据库特性。同时,PolarDB PostgreSQL 版具有大规模并行计算能力,可以应对 OLTP 与 OLAP 混合负载。
1. 向量数据库
向量数据在各个领域中具有重要地位和基础作用。为满足不同应用场景的向量索引和查询需求,Polardb数据库提供了多款向量插件,如gin等。
插件 | 功能和应用场景 |
pgsphere | 处理地理空间向量数据,支持各种地理空间操作和查询,如点、线、多边形等。适用于地理信息系统、位置分析等领域。 |
pg_trgm | 用于文本相似度计算,支持文本分词、匹配和相似度计算等操作。适用于文本搜索、模糊匹配、推荐系统等场景。 |
GIN | 提供通用的倒排索引功能,适用于多种数据类型,包括向量数据。特别适合高效的向量相似度查询和范围查询。 |
rum | 一种高性能的范围查询插件,支持范围查询和模糊查询。适用于范围搜索、模糊匹配等场景。 |
pase | 处理大规模向量数据的向量索引插件,采用近似搜索技术,可以在大型数据集上进行高效的相似度查询。适用于大规模向量数据的快速相似度搜索和聚类分析。 |
pgvector | 支持高维向量数据,具有16000维的容量。适用于各种向量数据的存储、查询和相似度计算,如图像处理、特征提取、推荐系统等领域。 |
以上描述是对每个插件一般应用场景的概述,并不涵盖所有可能的使用情况。实际使用时,需要根据具体需求和数据特点选择最合适的向量插件。以下简单介绍下pase插件。
2.1 pase插件介绍
PASE(PostgreSQL ANN search extension)是一款兼容PolarDB-PG数据库的高性能向量检索插件,使用业界中成熟稳定且高效的ANN(Approximate nearest neighbor)检索算法,包括IVFFlat和HNSW算法,通过这两种算法,可以在数据库中实现极高速向量查询。PASE负责的工作是根据已产出的海量级别的向量进行相似向量的检索。
2.2.1数据构建
CREATE TABLE vectors_hnsw_test (
id serial,
name TEXT,
vector float4[]
);2.2.3数据检索
数据库中有了样本,可以利用pase插件的向量计算取得“最近似”数据。
SELECT name, vector, vector <?> %s::pase AS distance
FROM vectors_hnsw_test
ORDER BY distance ASC
LIMIT 2;
"""使用上面sql可以查询出最接近的向量,可以实现类似“人脸识别”的应用。
2.2.3计算过程分析
pase的近似计算:
SELECT ARRAY[2, 1, 1]::float4[] <?> pase(ARRAY[3, 1, 1]::float4[]) AS distance;
SELECT ARRAY[2, 1, 1]::float4[] <?> pase(ARRAY[3, 1, 1]::float4[], 0) AS distance;
SELECT ARRAY[2, 1, 1]::float4[] <?> pase(ARRAY[3, 1, 1]::float4[], 0, 1) AS distance;<?>是PASE类型的操作符,表示计算左右两个向量的相似度。左边向量数据类型必须为float4[],右边向量数据类型必须为pase。
pase类型为插件内定义的数据类型,包含如上示例的三种构造方法,以示例第三条的float4[], 0, 1部分进行说明:第一个参数为float4[],代表右向量数据类型;第二个参数在此处没有特殊作用,可以填入0;第三个参数表示相似度计算方式,0表示欧氏距离,1表示点积(内积)。
左右向量的维度必须相等,否则计算会报错。
postgres=# SELECT ARRAY[2, 1, 1]::float4[] <?> pase(ARRAY[3, 1, 1]::float4[], 0, 1) AS distance;
distance
----------
8
(1 row)
postgres=# SELECT ARRAY[2, 1, 1]::float4[] <?> pase(ARRAY[3, 1, 1]::float4[], 0, 0) AS distance;
distance
----------
1
(1 row)2.2.4索引算法
索引算法,包括hnsw和IVFFlat算法

算法流程说明:
1、按照kmeans等聚类算法对向量进行聚类处理,使得每个类簇有一个中心点。
2、检索向量时首先遍历计算所有类簇的中心点,找到与目标向量最近的n个类簇中心。
3、遍历计算n个类簇中心所在聚类中的所有元素,经过全局排序得到距离最近的k个向量。
本期先介绍到这里,更多向量插件欢迎到官网查看介绍。向量数据在各个领域中具有重要地位和基础作用。为满足不同应用场景的向量索引和查询需求,Polardb数据库提供了多款向量插件,如gin等。
插件 | 功能和应用场景 |
pgsphere | 处理地理空间向量数据,支持各种地理空间操作和查询,如点、线、多边形等。适用于地理信息系统、位置分析等领域。 |
pg_trgm | 用于文本相似度计算,支持文本分词、匹配和相似度计算等操作。适用于文本搜索、模糊匹配、推荐系统等场景。 |
GIN | 提供通用的倒排索引功能,适用于多种数据类型,包括向量数据。特别适合高效的向量相似度查询和范围查询。 |
rum | 一种高性能的范围查询插件,支持范围查询和模糊查询。适用于范围搜索、模糊匹配等场景。 |
pase | 处理大规模向量数据的向量索引插件,采用近似搜索技术,可以在大型数据集上进行高效的相似度查询。适用于大规模向量数据的快速相似度搜索和聚类分析。 |
pgvector | 支持高维向量数据,具有16000维的容量。适用于各种向量数据的存储、查询和相似度计算,如图像处理、特征提取、推荐系统等领域。 |
以上描述是对每个插件一般应用场景的概述,并不涵盖所有可能的使用情况。实际使用时,需要根据具体需求和数据特点选择最合适的向量插件。以下简单介绍下pase插件。
2.1 pase插件介绍
PASE(PostgreSQL ANN search extension)是一款兼容PolarDB-PG数据库的高性能向量检索插件,使用业界中成熟稳定且高效的ANN(Approximate nearest neighbor)检索算法,包括IVFFlat和HNSW算法,通过这两种算法,可以在数据库中实现极高速向量查询。PASE负责的工作是根据已产出的海量级别的向量进行相似向量的检索。
2.2.1数据构建
CREATE TABLE vectors_hnsw_test (
id serial,
name TEXT,
vector float4[]
);2.2.3数据检索
数据库中有了样本,可以利用pase插件的向量计算取得“最近似”数据。
SELECT name, vector, vector <?> %s::pase AS distance
FROM vectors_hnsw_test
ORDER BY distance ASC
LIMIT 2;
"""使用上面sql可以查询出最接近的向量,可以实现类似“人脸识别”的应用。
2.2.3计算过程分析
pase的近似计算:
SELECT ARRAY[2, 1, 1]::float4[] <?> pase(ARRAY[3, 1, 1]::float4[]) AS distance;
SELECT ARRAY[2, 1, 1]::float4[] <?> pase(ARRAY[3, 1, 1]::float4[], 0) AS distance;
SELECT ARRAY[2, 1, 1]::float4[] <?> pase(ARRAY[3, 1, 1]::float4[], 0, 1) AS distance;- <?>是PASE类型的操作符,表示计算左右两个向量的相似度。左边向量数据类型必须为float4[],右边向量数据类型必须为pase。
- pase类型为插件内定义的数据类型,包含如上示例的三种构造方法,以示例第三条的float4[], 0, 1部分进行说明:第一个参数为float4[],代表右向量数据类型;第二个参数在此处没有特殊作用,可以填入0;第三个参数表示相似度计算方式,0表示欧氏距离,1表示点积(内积)。
- 左右向量的维度必须相等,否则计算会报错。
postgres=# SELECT ARRAY[2, 1, 1]::float4[] <?> pase(ARRAY[3, 1, 1]::float4[], 0, 1) AS distance;
distance
----------
8
(1 row)
postgres=# SELECT ARRAY[2, 1, 1]::float4[] <?> pase(ARRAY[3, 1, 1]::float4[], 0, 0) AS distance;
distance
----------
1
(1 row)2.2.4索引算法
索引算法,包括hnsw和IVFFlat算法
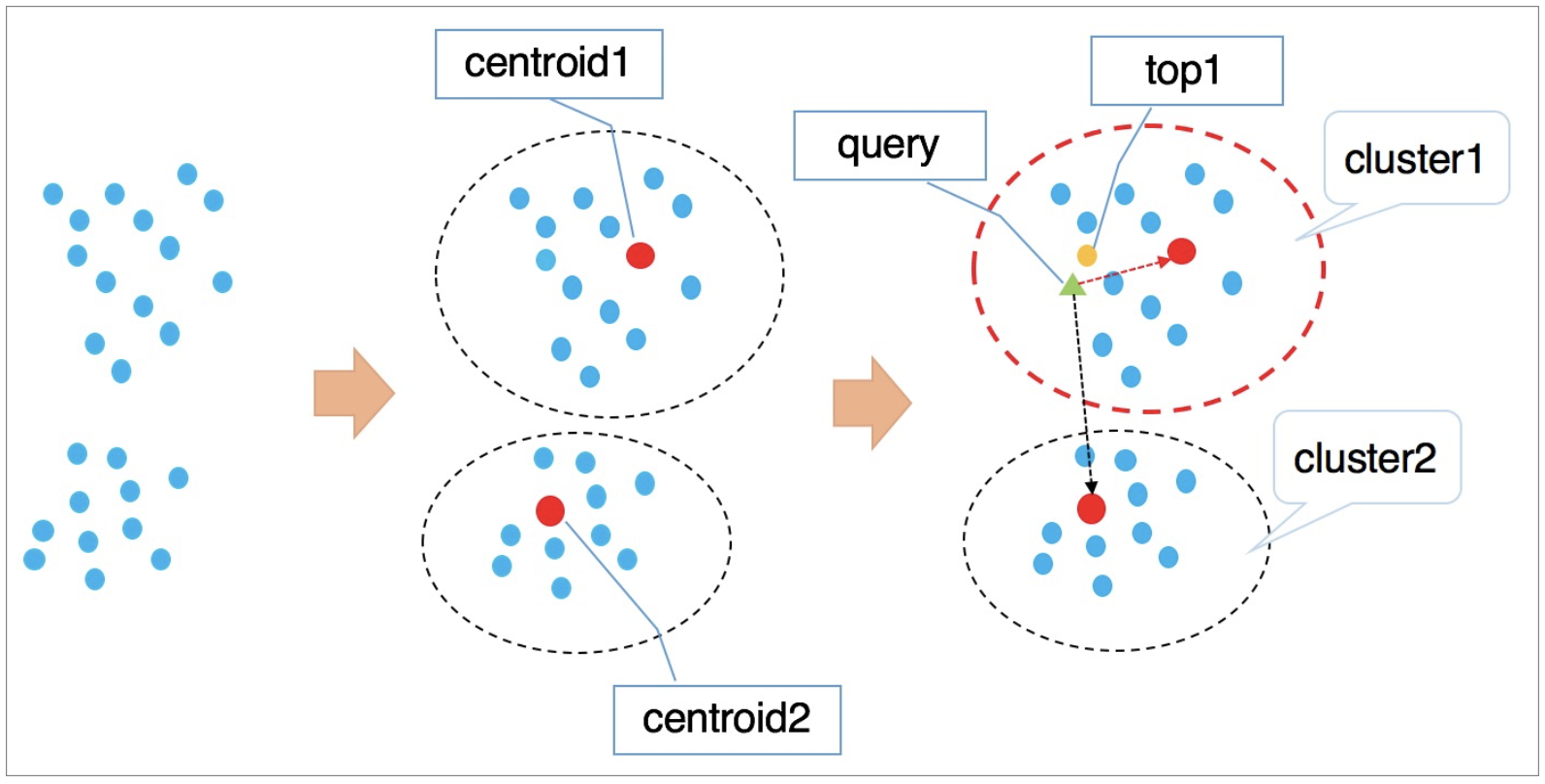
算法流程说明:
1、按照kmeans等聚类算法对向量进行聚类处理,使得每个类簇有一个中心点。
2、检索向量时首先遍历计算所有类簇的中心点,找到与目标向量最近的n个类簇中心。
3、遍历计算n个类簇中心所在聚类中的所有元素,经过全局排序得到距离最近的k个向量。
本期先介绍到这里,更多向量插件欢迎到官网查看介绍。
