






基于代价的优化器
常见的数据库查询优化器分为基于规则的优化器(Rule-based Optimization, RBO)和基于代价的优化器(Cost-based Optimization, CBO)。
规则优化是一种基于事先定义的规则和启发式方法来优化查询计划的方式。优化器会按照一系列预定的规则对查询进行转换和重写,以得到一个较为优化的查询计划。这些规则可能涉及谓词下推、连接顺序调整、子查询展开等。
RBO由于其简单直观,有很好的可预测性,因此在早期被广泛应用于数据库的查询优化器中。但其在处理复杂查询和适应动态环境方面存在局限性,优化质量较低,因此在现代数据库系统中,大家更多地选择采用基于代价的优化器(CBO)等更先进的优化方法。
CBO是通过评估查询执行计划的成本,从而选择最优的查询执行方案。在基于代价的优化中,优化器会使用数据库的统计信息来估算执行查询计划的成本,并根据代价来选择最佳的查询计划。
由于CBO是一种自适应的优化方法,因此可以根据实际运行时的执行情况动态调整查询计划,以适应不断变化的数据和环境条件。这使得优化器能够灵活应对动态的数据库环境,对不同的查询计划进行代价估算,从而更准确地选择最优的执行方案。
优化器的架构包含三个重要组件:基数估计器、代价模型和计划搜索空间。对于用户传来的SQL,优化器首先为其枚举出不同的执行计划,形成一个搜索空间;然后将收集得到的统计信息(如表的行数、谓词的选择率等)作为输入,在代价模型(cost model)中为不同的执行计划计算出相应的代价。由此产生的最小代价的计划会被优化器选中,成为最终的执行计划,并在数据库执行器中运行。
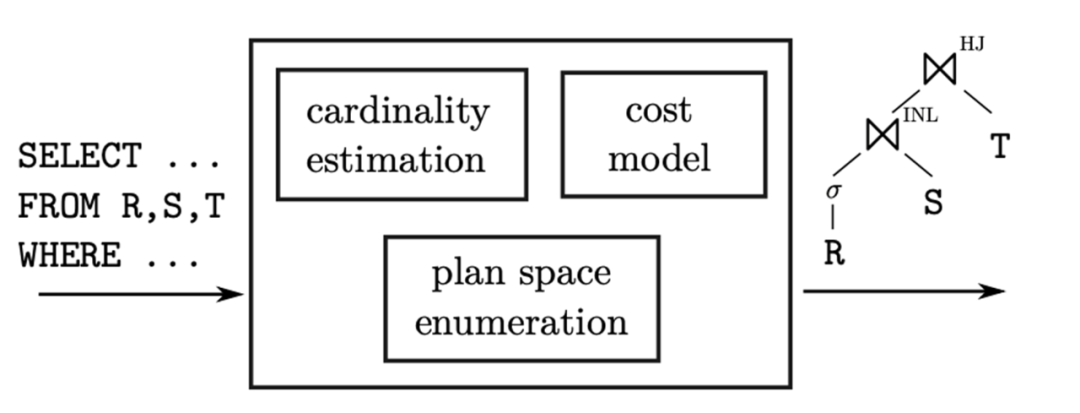
但可以看出,CBO依赖于准确的数据库统计信息,如表的行数、索引的选择率等。如果统计信息不准确或过时,优化器可能会做出错误的优化决策,导致查询性能下降。
学习型优化器
初始化优化器
优化器的更新迭代
在优化器中,找到关联语句的查询顺序是一个最重要也是最困难的能力。对于一个关联查询语句,其搜索空间的个数随着关联表个数的增加而呈指数级增加。
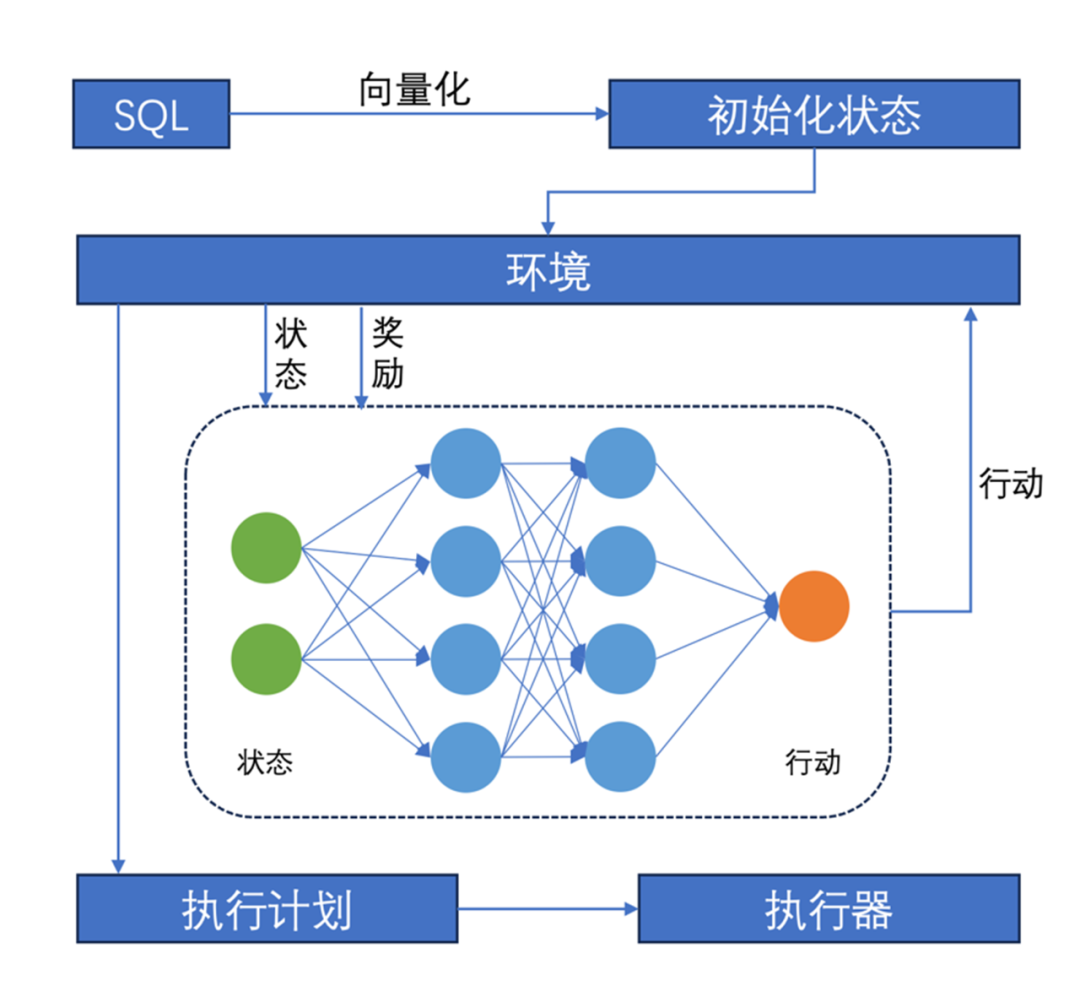
以关联查询为例,首先通过知识库中记忆的执行历史信息和训练模型,获取每张表中各字段的分布情况。在传入一个新的SQL查询语句后,RapidsDB将其转换为查询树,优化器将其向量化以表示表之间的关联关系及选择谓词,同时形成包含表和选择谓词对应基数的向量,最终将包含SQL查询语句和其对应基数的向量组合在一起。接下来,使用强化学习算法找到对于当前状态下的最佳行动,以尽可能增加奖励。由于查询语句的可能性非常多,不可能穷尽所有的状态,因此RapidsDB使用深度确定性策略梯度算法构建奖励数据表,使得优化器可以解决连续动作空间的策略。初始的奖励表由上节初始化的数据训练得出。
随着数据库的使用以及数据源的更新,优化器的知识库增加了新的查询结果,模型会根据用户的设置,在达到一定的时间或精度损失的情况下,使用新的数据对模型进行更新重训练。
以下是RapidsDB在处理多表关联查询时的流程示例:
自适应下推的联邦查询系统
RapidsDB动态查询优化器的优势
对于数据驱动、基于学习的优化器来说,解决冷启动问题是一个重要的挑战。在数据库使用初期,由于缺乏历史数据,模型难以进行有效的优化。为了解决这个问题,RapidsDB采用了预估基数和启发式算法,从而实现了在没有历史数据的情况下也能够进行优化。
随着数据库的使用,系统会产生大量的数据,这为模型的持续优化提供了条件。模型在使用中持续更新、训练,可以让数据库运行越来越高效。
推荐阅读



你的 在看 为智能数据算力点赞
